- Cisco Community
- Technology and Support
- Collaboration
- Collaboration Knowledge Base
- CUCM IP Phone (SCCP) Keepalive and Failover Architecture
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-17-2011 10:10 AM - edited 03-12-2019 09:41 AM
- Purpose
- What is a keeplive and why do we use them?
- Ok, so how does it work?
- So what happens when the keepalives don't get to where they need to go?
- "Delayed" failover for SCCP phones.
- "Normal" failover behavior (Geometric TCP Phone Failover).
- So why would I ever set my phones to Delayed??
Purpose
The manner in which Cisco Unified Communications Manager (CUCM), and Skinny Call Control Protocol (SCCP) phones exchange and monitor keepalives has been often misunderstood and not very well documented, leaving many with questions about the process, and architecture. This document is meant to be a reference, with the hopes of clearing some of the confusion. This document does not address Signal Distribution Layer (SDL) keepalives that are passed between CUCM nodes.
What is a keeplive and why do we use them?
A keepalive, for the purposes of this document, is a TCP/SCCP packet sent from a phone to one or more CUCM nodes to which it is configured to register and communicate.
These keepalives are used by the phone for a couple of different reasons. First, the keepalives ensure that the TCP link to the CUCM node(s) is still viable. Second, the keepalive ensures that the Cisco Call Manager (CCM) Service is still functional, and able to process the phone's call control needs, and requests. While these may seem to be one in the same, they are actually slightly different in functionality, but both are obviously important with the SCCP connection to the CCM Service being reliant upon the TCP connection being connected for success. The implication of keepalive failure to either of these processes will be discussed in greater detail later on in this document.
Ok, so how does it work?
By default, SCCP phones send a keepalive to their primary CUCM server every 30 seconds and to their failover node, which is the second node listed in the phone's Call Manager (CM) Group, every 60 seconds. The primary node will respond with a keepalive ACK confirming that both the TCP connection and the SCCP connection are both still valid. Alternatively, if the CCM Service on the primary node is down, the TCP connection may be ACK'd, but the SCCP aspect of the keepalive would not. This type of a response would signal to the phone that the TCP stack on the CUCM is still able to respond to inbound traffic, however the CUCM does not appear to be able to process calls at this time. Additionally, if the TCP connection fails to respond, then the phone quickly recognizes that the link is broken and the failover process begins.
Cisco IP phones also send a SCCP keepalive to their secondary node. This is done to maintain and monitor a TCP connection between the phone and the secondary CUCM in order to facilitate a prompt and reliable failover should the need arise. The secondary CUCM, however, does not have a SCCP connection (as the phone has not registered to the secondary node at this point) and will therefore only ACK the TCP connection in response to the SCCP keepalive sent by the phone.
In the packet capture (pcap) below, you can see an example of the keepalive transaction between a phone and it's CUCM nodes.
Frame 3232 - Phone (14.106.2.80) is sending a SCCP KeepAliveMessage to it's primary CUCM server (10.86.76.85).
Frame 3233 - CUCM (10.86.76.85) responds with a KeepAliveAck to the phone acknowledging that both the TCP and CCM connections are still valid.
Frame 3234 - Phone (14.106.2.80) sends a TCP ACK to the CUCM ACK received in Frame 3233.
Frame 3237 - Phone (14.106.2.80) sends a SCCP KeepAliveMessage to it's secondary CUCM server (10.86.76.86).
Frame 3238 - CUCM (10.86.76.86) responds with a TCP ACK to the phone, but notice that the SCCP aspect is missing from the TCP frame as the secondary CUCM does not ACK a SCCP connection, only the TCP connection to maintain a failover connection to this node if needed.

From a CUCM perspective, when keepalive tracing is enabled, this is what would be seen in the CCM SDI traces as an example of inbound SCCP keepalive messages to CUCM:
08:48:56.386 |InboundStim - KeepAliveMessage - Send KeepAlive to Device Controller. DeviceName=SEP000000000000, TCPPid = [1.100.9.2742], IPAddr=10.1.1.13, Port=17994, Device Controller=[1,50,1369]|1,100,49,1.7224140^10.25.11.13^
SEP000000000000
08:48:56.389 |InboundStim - KeepAliveMessage - Send KeepAlive to Device Controller. DeviceName=SEP000000000001, TCPPid = [1.100.9.3162], IPAddr=10.1.1.5, Port=6830, Device Controller=[1,50,1652]|1,100,49,1.7224141^10.1.19.5^SEP000000000001
While the primary CUCM does log the inbound keepalive message from the phone, there is no logging of the response. From a troubleshooting perspective it is assumed that the CUCM responds to the keepalive when the above message is printed in the traces, but for solid evidence of a response we would need to get a packet capture from the CUCM interface or port.
Conversely, viewing the same keepalive tracing on a secondary node yields slightly different results. Notice below how the CUCM logs the keepalive event, but also states that it is dropping the KeepAliveAck rather than responding. Remember, this is only at the CCM process/SCCP level as the secondary does respond to at a TCP level to maintain that connection to the phone.
12:04:25.892 |KeepAliveMessage received on backup CM link. Dropping KeepAliveAck. DeviceName=, TCPPid = [2.100.9.14348], IPAddr=10.1.1.13, Port=24527, Device Controller=[0,0,0]|2,100,49,1.5783617^10.1.18.3^*
12:04:26.048 |KeepAliveMessage received on backup CM link. Dropping KeepAliveAck. DeviceName=, TCPPid = [2.100.9.157], IPAddr=10.1.1.14, Port=32877, Device Controller=[0,0,0]|2,100,49,1.5783618^10.1.19.4^*
So what happens when the keepalives don't get to where they need to go?
In an ideal situation, Cisco IP phones will pass keepalives to their primary and secondary CUCM servers and receive an ACK back for each one maintaining a TCP connection to each and registration to the primary. However, the main reasons for the keepalive system is not only to ensure current connectivity, but to also ensure that the backup link is still available to facilitate a prompt failover.
There are three basic reasons why a phone may failover from one server to another: unresponsive CCM Service on the CUCM node where the phone is currently registered, TCP socket break with the currently registered CUCM node, or availability of a higher priority CUCM server than the one to which the phone is currently registered.
The unavailability of the CCM service (sometimes due to CCM process crashing or high CPU utilization causing response delays) is often confused with the TCP socket break, but they are actually quite different. In a case where the phone is sending keepalives to its registering CUCM server and is receiving TCP ACKs, but is not receiving SCCP ACKs, the phone will wait for three failed SCCP keepalives in a row before considering that node unavailable. After the third failed SCCP keepalive, the phone will fail over to its secondary CUCM server.
Conversely, the second and likely the most common failover reason, is due to a TCP timeout. TCP timeout is almost exclusively indicative of a network problem between the phone and the CUCM server(s). While the CCM Service on the registered CUCM must fail to respond to three consecutive SCCP keepalives before the phone will fail over, TCP keepalive behavior is dependant upon the configuration settings of the phone and is generally much more sensitive to missed keepalives.
By default, CUCM uses Normal failover behavior as set by the "Detect Unified CM Connection Failure" parameter on the device configuration page. The Normal setting was introduced as an enhancement in phone load 7.2(1) and is also known as Geometric TCP Phone Failover, or adaptive failover. Geometric Failover was introduced as an improvement to the previous default configuration (now refererred to under the same parameter as "Delayed") as it allows for a much faster conversion to the secondary CUCM node when the TCP connection to the primary CUCM fails to respond to the keepalives sent from the phone.
"Delayed" failover for SCCP phones.
First, let's review the traditional functionality, or the "Normal" setting, for the "Detect Unified CM Connection Failure" parameter. The original behavior uses a TCP back-off timer that is used to detect TCP connection failure. If a phone sends a SCCP keepalive to CUCM and does not receive a response within 300ms, the phone retransmits the keepalive and again 300ms later if the first retransmit is also unacknowledged. After missing the three initial TCP keepalives, the phone then begins its back-off algorithm sending subsequent TCP retransmissions at approximate intervals of 400ms, 800ms, 1.5 seconds, 2.5 seconds, 5 seconds, 10 seconds and finally resetting the TCP connection after an additional 15 seconds if an ACK still has not been received from the CUCM.
This, as you can calculate, can lead to a minimum time frame of over 35 seconds simply to declare the connection to be link-dead. Add to this 35 seconds the amount of time required to re-register to the secondary node and the worst case scenario of the link loss occurring immediately after the last successful keepalive ACK from CUCM (giving an additional 30 seconds until the next keepalive is sent from the phone) and you can understand why this is now referred to as "Delayed" behavior. See the image below for an example pcap for a Delayed failover scenario.
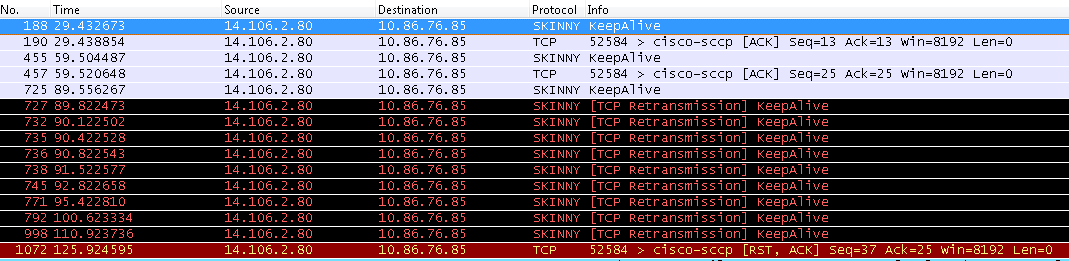
"Normal" failover behavior (Geometric TCP Phone Failover).
Given the above example of the initial failover timing and behavior of Cisco SCCP IP phones, it's easy to see why there was a call for a faster failover mechanism to address scenarios where link-loss occurred. Any administrator of a large network will tell you that a five minute outage during which users are unable to use their phones while they are missing keepalives and then registering to their secondary nodes will tell you that it's too long. This was the catalyst for the introduction of Geometric TCP Phone Failover.
The Normal setting for "Detect Unified CM Connection Failure" implements an algorithm that monitors each keepalive response from the CUCM to the phone and measures the transit times to create a baseline, expected transit time to which it will compare all future keepalive attempts. A very basic example of this would be that if the phone has received 10,000 keepalive ACK messages and the expected transit time is X, the algorithm will then determine a retransmit time based upon X and then retransmit the keepalive messages accordingly. Generally speaking, the retransmit time under the Normal setting is much faster and at shorter intervals between retransmission than under the Delayed setting. Additionally, the Normal setting will only allow for six missed keepalive ACKs before the connection is reset. As is expected, this drastically reduces the failover time for phones from what could be as much as minutes to as little as seconds in the event of a network outage, between the phones and their primary CUCM server. See the image below for an example pcap for a Normal failover scenario.

So why would I ever set my phones to Delayed??
Under most situations, the default setting of Normal should be used for phones in a CUCM environment. However, in the event that phones are traversing a less-than-reliable connections or in bandwidth-starved networks (specifically extreme examples where all available bandwidth is given to high-priority voice/RTP traffic and all other traffic is scavenging) to connect to their CUCM server, the Delayed setting may be useful. If the connection is sufficient to support voice in a reliable manner, but may miss keepalives periodically, the algorithm used by the Normal setting may be too sensitive and cause phones to unregister (and subsequently, re-register) from their primary CUCM node without just cause. Under these conditions, setting the value to Delayed may allow enough time for the phone to receive keepalives before failing over. The important thing to remember is that this is not "fixing" the problem, but merely increasing the failover tolerance and allowing the phones to exercise more flexibility within the keepalive process.
Here are two examples of ping tests from a CUCM server to a phone with two very different network responses. In Ping Test 1, the Normal setting would be the correct setting. In Ping Test 2, however, we may wish to set our "Detect Unified CM Connection Failure" parameter to Delayed in order to account for the massive discrepancies in transit time from packet to packet.
Ping Test 1
64 bytes from 10.1.2.4: icmp_seq=0 ttl=63 time=0.407 ms
64 bytes from 10.1.2.4: icmp_seq=1 ttl=63 time=0.396 ms
64 bytes from 10.1.2.4: icmp_seq=2 ttl=63 time=0.391 ms
64 bytes from 10.1.2.4: icmp_seq=3 ttl=63 time=0.469 ms
64 bytes from 10.1.2.4: icmp_seq=4 ttl=63 time=0.419 ms
64 bytes from 10.1.2.4: icmp_seq=5 ttl=63 time=0.392 ms
64 bytes from 10.1.2.4: icmp_seq=6 ttl=63 time=0.383 ms
64 bytes from 10.1.2.4: icmp_seq=7 ttl=63 time=0.399 ms
64 bytes from 10.1.2.4: icmp_seq=8 ttl=63 time=0.427 ms
64 bytes from 10.1.2.4: icmp_seq=9 ttl=63 time=0.400 ms
64 bytes from 10.1.2.4: icmp_seq=10 ttl=63 time=0.389 ms
64 bytes from 10.1.2.4: icmp_seq=11 ttl=63 time=0.388 ms
64 bytes from 10.1.2.4: icmp_seq=12 ttl=63 time=0.391 ms
64 bytes from 10.1.2.4: icmp_seq=13 ttl=63 time=0.395 ms
64 bytes from 10.1.2.4: icmp_seq=14 ttl=63 time=0.469 ms
64 bytes from 10.1.2.4: icmp_seq=15 ttl=63 time=0.422 ms
64 bytes from 10.1.2.4: icmp_seq=16 ttl=63 time=0.392 ms
64 bytes from 10.1.2.4: icmp_seq=17 ttl=63 time=0.394 ms
64 bytes from 10.1.2.4: icmp_seq=18 ttl=63 time=0.405 ms
64 bytes from 10.1.2.4: icmp_seq=19 ttl=63 time=0.399 ms
64 bytes from 10.1.2.4: icmp_seq=20 ttl=63 time=0.392 ms
64 bytes from 10.1.2.4: icmp_seq=21 ttl=63 time=0.397 ms
64 bytes from 10.1.2.4: icmp_seq=22 ttl=63 time=0.416 ms
64 bytes from 10.1.2.4: icmp_seq=23 ttl=63 time=0.432 ms
64 bytes from 10.1.2.4: icmp_seq=24 ttl=63 time=0.387 ms
64 bytes from 10.1.2.4: icmp_seq=25 ttl=63 time=0.397 ms
Ping Test 2
64 bytes from 10.1.1.4: icmp_seq=1 ttl=63 time=28.1 ms
64 bytes from 10.1.1.4: icmp_seq=2 ttl=63 time=156 ms
64 bytes from 10.1.1.4: icmp_seq=3 ttl=63 time=0.410 ms
64 bytes from 10.1.1.4: icmp_seq=4 ttl=63 time=0.423 ms
64 bytes from 10.1.1.4: icmp_seq=5 ttl=63 time=0.409 ms
64 bytes from 10.1.1.4: icmp_seq=6 ttl=63 time=272 ms
64 bytes from 10.1.1.4: icmp_seq=7 ttl=63 time=224 ms
64 bytes from 10.1.1.4: icmp_seq=8 ttl=63 time=118 ms
64 bytes from 10.1.1.4: icmp_seq=9 ttl=63 time=0.410 ms
64 bytes from 10.1.1.4: icmp_seq=10 ttl=63 time=148 ms
64 bytes from 10.1.1.4: icmp_seq=11 ttl=63 time=82.9 ms
64 bytes from 10.1.1.4: icmp_seq=12 ttl=63 time=412 ms
64 bytes from 10.1.1.4: icmp_seq=13 ttl=63 time=0.413 ms
64 bytes from 10.1.1.4: icmp_seq=14 ttl=63 time=213 ms
64 bytes from 10.1.1.4: icmp_seq=15 ttl=63 time=142 ms
64 bytes from 10.1.1.4: icmp_seq=16 ttl=63 time=226 ms
64 bytes from 10.1.1.4: icmp_seq=17 ttl=63 time=0.400 ms
64 bytes from 10.1.1.4: icmp_seq=18 ttl=63 time=0.404 ms
64 bytes from 10.1.1.4: icmp_seq=19 ttl=63 time=83.1 ms
64 bytes from 10.1.1.4: icmp_seq=20 ttl=63 time=2.61 ms
64 bytes from 10.1.1.4: icmp_seq=21 ttl=63 time=417 ms
64 bytes from 10.1.1.4: icmp_seq=22 ttl=63 time=206 ms
64 bytes from 10.1.1.4: icmp_seq=23 ttl=63 time=284 ms
64 bytes from 10.1.1.4: icmp_seq=25 ttl=63 time=172 ms
Related Defects
CSCed01179 - AVVID: Phone TCP backoff algorithm slow to return to initial timeout
CSCsm81227 - Allow Geometric TCP phone failover to be configurable
CSCtc43246 - Disable fast TCP connection loss detection for wireless networks
CSCtl03634 - Detect Connection Unified CM Failure DELAY does not work properly
Special thanks to Kenneth Russell, Wes Sisk, Ryan Ratliff and Jason Wiatr for helping me research this topic and providing me with information.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Good document!
It great help me.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
5 stars*****
Nice doc!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Awesome Documentation...This is where you seperate the boys from the men!!! Love it!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Expected behavior for the above incident would be for the phone to go into a "CM Down" state. In this state, RTP stays active and the voice call should continue without interruption, however any "advanced" features that would require communication with the UCM node are no longer available for the remainder of the call (transfer/hold/conference). The phone(s) will go through a soft-reset/re-registration when the call concludes to re-establish the registration with UCM.
")
")
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Great doc Steven!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Good document. I just wish CUCM had a setting between Normal and Delayed. I'm finding that routing protocols take longer than Normal time to settle down, but Delay, is too long a delay for when there is a server outage.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Great Document , very helpful in an easy to understand explanation !!!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
This document is awesome and has me thinking about the addition of MTP’s into the equation. Because although the call “should” stay up if the cucm goes down, if there’s a mtp that’s registered to the cucm, for possibly a codec mismatch, dtmf mismatch, or something like that, the call would drop if the call manager responsible for the mtp registration dies or goes offline.
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: