- Cisco Community
- Technology and Support
- DevNet Hub
- DevNet Collaboration
- Contact Center
- Re: Build archiving Social Miner API
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Build archiving Social Miner API
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-14-2016
10:14 PM
- last edited on
03-05-2021
09:38 AM
by
dekwan
![]()
Dear All, As Social Miner doesn't have an option for archiving or store the data on the external disk. Can anyone assist me to build an API using by Social Miner as archive the Social Contact as per need.
Refer to link below: https://developer.cisco.com/docs/contact-center-express/#!customer-collaboration-platform-dev-guide
if we can use GET API code to store the Social Contact in our data store.
Thanks & Regards
- Labels:
-
SocialMiner
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-14-2016 11:49 PM
Hi Ahmed,
SocialMiner does not provide you a ready-made option to archive/store data on an external disk/server.
However, what we do provide are a family of rich REST APIs using which you can easily extract the data you want.
To understand your use-case better, can you help clarify the following?
- What specific data are you interested in archiving? Is it all socialContacts in the system, or all chat transcripts, etc.?
- What is the reason you need to archive this outside of SocialMiner box? (SocialContact data remains in SM for a sufficiently long time, and you can even control the data purge settings in SocialMiner Administration - see below screenshot)
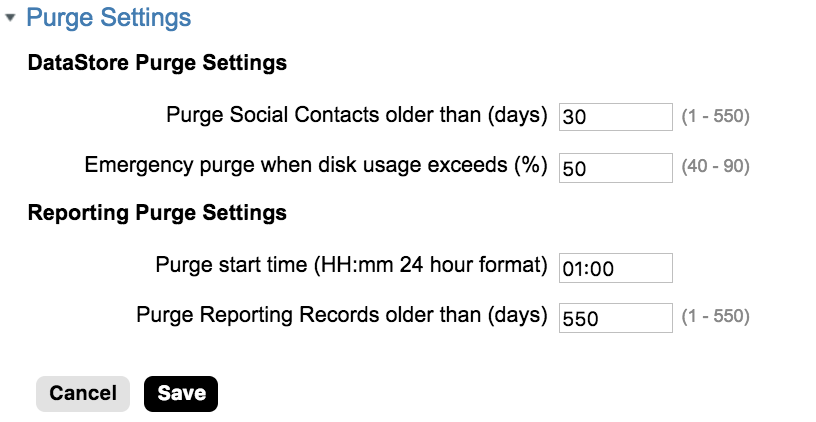
Based on understanding this, we will definitely help you achieve your use-case using our APIs.
Hope this helps.
Thanks,
Nagendra U M
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2016 12:04 AM
Hi Nagendra, thanks for your reply, Kindly note that we are interested in archiving the Chat contact transcripts only, Also note that if the disk usage exceeds certain percentage that confgiured such as(90%), the purge will take action automaticly to delete the oldest chat contacts, as we need some chat contacts transcript to be archiving for a long time rather than (550 days), although the disk usage exceed 90%. So that the reason for this request.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2016 12:24 AM
Hi Ahmed,
This is helpful. I understand your use-case now.
This is definitely possible, as described below:
- Use the Search REST API to search for all chat contacts in the system which are in HANDLED state (since successful chats with transcripts would all be in HANDLED state).
This would be an authenticated GET API with the below URL:
This API uses basic auth, so provide your SocialMiner administrator credentials while making the GET request.
For complete details on this API, refer Chapter 28 - Social Contact --> GET (Search) in Cisco SocialMiner Developer Guide.
- Upon successfully making this REST API request, the response will be an XML-based ATOM feed containing all SocialContacts that match the search (essentially, all HANDLED chat contacts), and within each <SocialContact> tag, you will find a <ChatTranscript> tag that contains all the chat transcript for every contact.
However, this is in an XML format. You can process this using your own program/script to convert this into plain-text or HTML etc. and then persist them wherever you want to, based on your needs and preference.
I am currently in the middle of creating a friendly python script that can connect to any SocialMiner and extract/download chat transcripts in bulk, and save them as text files on the local machine which can then be archived.
If you are interested in using and extending this script (purely on an as-is basis), please reach out to me again next week (by when I should be hopefully done).
Hope this helps.
Thanks,
Nagendra U M
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-21-2016 07:25 AM
Hi,
thanks for the interesting example, we have to face with a similar request on chat, but on custom parameters. We need to access custom parameters shared between customer and agent in order to trace the type of request, for example information, user type, ecc. The SocialMIner INFORMIX DB does not contain any of these field.
How can We get such variable/value field?
May thanks
Domenico
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-21-2016 10:13 PM
Hi Domenico,
What you ask for is also totally possible using SocialMiner REST APIs.
This is how you would be able to do it:
- Use the Search REST API to search for all chat contacts in the system which are in HANDLED state (since successful chats with transcripts would all be in HANDLED state).
This would be an authenticated GET API with the below URL:
This API uses basic auth, so provide your SocialMiner administrator credentials while making the GET request.
For complete details on this API, refer Chapter 28 - Social Contact --> GET (Search) in Cisco SocialMiner Developer Guide.
- Upon successfully making this REST API request, the response will be an XML-based ATOM feed containing all SocialContacts that match the search (essentially, all HANDLED chat contacts), and within each <entry> tag (which represents a SocialContact), you will find a <link rel="socialcontact" ...> tag that contains a URL to the SocialContact. For example:
<link rel="socialcontact" href="http://10.78.95.237/ccp-webapp/ccp/socialcontact/20DCF7B81000015900000D2C0A4E5FED"/>
- Now, use this SocialContact URL and do an authenticated GET request (basic auth, so provide your SocialMiner administrator credentials). The response from to this GET request is an XML with all details of the SocialContact, including a set of fields called <extensionFields> which are basically name-value pairs.
- The custom parameters/fields that the chat customer has provided (in the chat form) will be included as part of <extensionFields>. You can then extract that and process it however you want to.
Hope this helps.
Thanks,
Nagendra U M
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-22-2016 01:29 AM
Hi Nagendra,
many thanks for the useful and comprehensive explanation, now I have a very clear understanding.
I would also ask you a suggestion: the customer is asking graphical reports integrated with CUIC. According to you, which is the best way to integrate information coming from CCX via SQL and from SocialMiner via REST API?
Best regards
Domenico
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-22-2016 01:32 AM
Hi Domenico,
Glad this helped.
For your question on visualising this data in a CUIC report, I recommend that you post this question on CUIC support forums where you can get more information on how this can be achieved.
Thanks,
Nagendra U M
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-20-2017 10:48 AM
Hey Nagendra,
Did you ever have any luck in creating this Python script? We currently have our help desk tech manually pulling these logs and this would save him a few hours of work every week. Please let me know.
Thank you,
Kevin Ryan Pilsbury
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-20-2017
10:56 AM
- last edited on
03-05-2021
10:21 AM
by
dekwan
![]()
Hi Kevin,
Yes! The script is ready.
You can download it from here: https://github.com/CiscoDevNet/socialminer-sample-code/tree/master/bulk-transcript-downloader
It is available for all partners and customers under samples in SocialMiner DevNet portal (Cisco DevNet: SocialMiner - Overview)
There is a README alongside the script that provides details on how to run it, and system requirements etc.
Please note that this is a working sample script to be used on an as-is basis. Feel free to modify and enhance this script in whatever way you want.
Thanks,
Nagendra U M
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-20-2017 10:58 AM
Thank you so much!
Kevin Ryan Pilsbury
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-08-2017 07:39 AM
Hi Nagendra ,
I engage in the conversation because our scenario is almost the same. We have developed a cutom php script that uses Social Miner Api for taking chat sessions info. Then the API's results are inserted into a UCCX table (a new table that we freshly have created in db_cra database). So my question is: could be this process dangerous to UCCX's health? (we have 200/300 chat sessions for day).
Many thanks.
Antonino.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-19-2020 01:04 PM
I am using the github version
https://github.com/CiscoDevNet/socialminer-sample-code/tree/master/bulk-transcript-downloader
Wondering how to capture "queuetag" in the filename? Can't find anything about the metadata for transcripts.
def compose_transcript_metadata(transcript_node, host, user):
return TRANSCRIPT_METADATA.format(host,
user,
time.strftime(TIMESTAMP_FORMAT, time.localtime(time.time())),
transcript_node.find('id').text,
transcript_node.find('chatInitiator').text,
time.strftime(TIMESTAMP_FORMAT, time.localtime(
float(transcript_node.find('startDate').text) / 1000)),
time.strftime(TIMESTAMP_FORMAT, time.localtime(
float(transcript_node.find('endDate').text) / 1000)));
=============
def export_transcript(transcript_node, host, user):
transcript_text = extract_transcript(transcript_node, host, user)
filename = TRANSCRIPT_FILENAME.format(time.strftime(FILENAME_TIMESTAMP_FORMAT,
time.localtime(
float(transcript_node.find('startDate').text) / 1000)),
transcript_node.find('chatInitiator').text)
print "Exporting transcript into file: %s" % filename
# write to text file
with open(TRANSCRIPT_TEMP_DIRNAME + os.path.sep + filename, 'w') as text_file:
text_file.write(transcript_text)
Or possibly how to modify the existing query to query on Handled by queue tag.
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-09-2017 12:10 AM
Hello Nagendra,
Hope you are doing good. I tried using the python script (installed Python 2.7, PIP and requests module as well) to download the chat transcript; But we are hitting an error while executing the script. Below is the error snippet,
C:\Python Folder\bulk-transcript-downloader>python bulk-transcript-downloader.py --host 10.207.32.200 --user smradmin --password a5t3lla51pt
Making a GET request to the URL: https://10.207.32.200/ccp-webapp/ccp/search/contacts?q=sc.sourceType:chat%20AND%20sc.socialContactStatus:handled
Traceback (most recent call last):
File "bulk-transcript-downloader.py", line 190, in <module>
main()
File "bulk-transcript-downloader.py", line 168, in main
search_response = make_search_request(SEARCH_API_URL.format(host), username, password)
File "bulk-transcript-downloader.py", line 86, in make_search_request
response = requests.get(url, auth=(user, password), verify=False)
File "C:\Python27\lib\site-packages\requests\api.py", line 72, in get
return request('get', url, params=params, **kwargs)
File "C:\Python27\lib\site-packages\requests\api.py", line 58, in request
return session.request(method=method, url=url, **kwargs)
File "C:\Python27\lib\site-packages\requests\sessions.py", line 513, in request
resp = self.send(prep, **send_kwargs)
File "C:\Python27\lib\site-packages\requests\sessions.py", line 623, in send
r = adapter.send(request, **kwargs)
File "C:\Python27\lib\site-packages\requests\adapters.py", line 514, in send
raise SSLError(e, request=request)
requests.exceptions.SSLError: [SSL: SSL_NEGATIVE_LENGTH] dh key too small (_ssl.c:661)
C:\Python Folder\bulk-transcript-downloader>
I am trying understand whether I should be installing any other module before running this script(apart from request module) and also what could be the issue here is?
Please advise.
Thanks in advance
Regards
Bala R
AT&T
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide