- Cisco Community
- Technology and Support
- Data Center and Cloud
- Data Center Switches
- VMWare 4.1 - MS 2k3 NLB & Nx 1000K problem
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
VMWare 4.1 - MS 2k3 NLB & Nx 1000K problem
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-21-2010 05:23 AM
Hi out there
We have a 8 Srv Dell Blade running VMWare 4.1 with 10GB pass-through modules which is connected to a dual-set of NX5010 for SAN (iSCSI) and a dual set of NX5020 for "user-data" - eg: RDP, SMB etc - normal LAN traffic.
We have successfully integrated the NX 1000V into this envronment and where going to migrate some physical servers - Win2k3 with MS NLB in unicast mode - to this environment. The first went very successfully - but the second showed us some basic problems - the NLB protocol in unicast mode didn't work here.
The NX1KV did "learn" the cluster mac-address on the assigned veth so the NLB part didn't work at all - all users were assigned to the same server.
We also tried the multicast setup as preferred by VMWare but this doesn't work very well in our environment.
Has somebody done a successfully implementation of Cisco NX 1KV running MS NLB? We where forced to de-install the NX1KV on those ESXi hosts we are using for terminalservice and use VMWares native switch - which works fine...
best regards /ti
- Labels:
-
Nexus 1000V
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-25-2010 05:52 AM
Has no-one tried a similary setup?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-28-2010 06:11 AM
Hi Thomas,
I will look into this issue for you. Firstly, I just wanted to clarify a couple of things.
1) What version of Nexus 1000v did you attempt to use?
2) When attempting to make use of unicast mode, you mentioned that --- the NX1KV did "learn" the cluster mac-address on the assigned veth so the NLB part didn't work at all - all users were assigned to the same server. --- What I understand from this statement, the cluster MAC address was only learnt on the first clustered VM's veth port and not on the second clustered VM's veth port, hence all traffic was going to the first VM. Please confirm/clarify if I have misunderstood.
3) What issues did you encounter using multicast mode?
Thanks,
Michael
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-28-2010 06:51 AM
Hi Michael
1) version:
Nexus1000V# sh ver
Cisco Nexus Operating System (NX-OS) Software
TAC support: http://www.cisco.com/tac
Copyright (c) 2002-2010, Cisco Systems, Inc. All rights reserved.
The copyrights to certain works contained in this software are
owned by other third parties and used and distributed under
license. Certain components of this software are licensed under
the GNU General Public License (GPL) version 2.0 or the GNU
Lesser General Public License (LGPL) Version 2.1. A copy of each
such license is available at
http://www.opensource.org/licenses/gpl-2.0.php and
http://www.opensource.org/licenses/lgpl-2.1.php
Software
loader: version unavailable [last: image booted through mgmt0]
kickstart: version 4.0(4)SV1(3a)
system: version 4.0(4)SV1(3a)
kickstart image file is:
kickstart compile time: 7/25/2010 21:00:00
system image file is: bootflash:/nexus-1000v-mz.4.0.4.SV1.3a.bin
system compile time: 7/25/2010 21:00:00 [07/26/2010 10:44:30]
Hardware
Cisco Nexus 1000V Chassis ("Virtual Supervisor Module")
Intel(R) Xeon(R) CPU with 2075028 kB of memory.
Processor Board ID T5056A50004
Device name: Nexus1000V
bootflash: 2332296 kB
Kernel uptime is 13 day(s), 2 hour(s), 44 minute(s), 2 second(s)
plugin
Core Plugin, Ethernet Plugin
Nexus1000V#
2) this notes from technet might clarify how MS NLB works:
Network Load Balancing uses layer-two broadcast or multicast to simultaneously distribute incoming network traffic to all cluster hosts. In its defaultunicast mode of operation, Network Load Balancing reassigns the station address ("MAC" address) of the network adapter for which it is enabled (called the cluster adapter), and all cluster hosts are assigned the same MAC address. Incoming packets are thereby received by all cluster hosts and passed up to the Network Load Balancing driver for filtering. To insure uniqueness, the MAC address is derived from the cluster's primary IP address entered in the Network Load Balancing Properties dialog box. For a primary IP address of 1.2.3.4, the unicast MAC address is set to 02-BF-1-2-3-4. Network Load Balancing automatically modifies the cluster adapter's MAC address by setting a registry entry and then reloading the adapter's driver; the operating system does not have to be restarted.
If the cluster hosts are attached to a switch instead of a hub, the use of a common MAC address would create a conflict since layer-two switches expect to see unique source MAC addresses on all switch ports. To avoid this problem, Network Load Balancing uniquely modifies the source MAC address for outgoing packets; a cluster MAC address of 02-BF-1-2-3-4 is set to 02-h-1-2-3-4, where h is the host's priority within the cluster (set in the Network Load Balancing Properties dialog box). This technique prevents the switch from learning the cluster's actual MAC address, and as a result, incoming packets for the cluster are delivered to all switch ports. If the cluster hosts are connected directly to a hub instead of to a switch, Network Load Balancing's masking of the source MAC address in unicast mode can be disabled to avoid flooding upstream switches. This is accomplished by setting the Network Load Balancing registry parameter MaskSourceMAC to 0. The use of an upstream level three switch will also limit switch flooding.
Network Load Balancing's unicast mode has the side effect of disabling communication between cluster hosts using the cluster adapters. Since outgoing packets for another cluster host are sent to the same MAC address as the sender, these packets are looped back within the sender by the network stack and never reach the wire. This limitation can be avoided by adding a second network adapter card to each cluster host. In this configuration, Network Load Balancing is bound to the network adapter on the subnet that receives incoming client requests, and the other adapter is typically placed on a separate, local subnet for communication between cluster hosts and with back-end file and database servers. Network Load Balancing only uses the cluster adapter for its heartbeat and remote control traffic.
But in fact did the veth of the first vm "learn" the clusters actual MAC address - and I guess that this caused the traffic to be sent only to this VM.
3) We have a "funny" disconnect/reconnect when we try to run the cluster in multicast mode - I cannot find anything why my client is behaving like this but my guess is that we have multiple adapters in the server and hereby will the Session Directory re-assign the session to other ip-adress of the server - I have attached a screenshot of the login-sequence where you can see the disconnect & re-connect between packet 1094 & 1095 - the cluster ip is .31 and the other i/f is .150
But you see - we have now been re-configuring a few of the ESX hosts to run under VMWares native switch where we have - for the time - a single cluster with 4 vm's used by ~ 250 interactive RDP users on it - this runs fine - but we would prefer to move it to the Cisco 1000V if possibly. It would really be nice if you could show me the trick in how this should be set up. It doesn't look to me as if other have had much succes with NLB and Nexus 1k :-)
best regards /ti
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-04-2010 05:23 AM
We are having a sort of similar issue after migrating from IOS (Cat6500) to NX-OS 7018/5000/2248.
Windows should not advertise the Cluster MAC to the switch because that will "kill" their abuse of "port flooding" where NLB is based on.
According to this TechNet article here MS should not advertise this address to the switch if the regkey MaskSourceMac = 1
http://technet.microsoft.com/en-us/library/cc736597%28WS.10%29.aspx
But it seems it still does after a interface disconnect/connect, it will take your mac aging-time timeout before it will be removed from the table and the switch will start to flood out packets to all hosts in the specific VLAN.
Next to the MAC registration issue we are still having an instable cluster, and are at the moment investigating what else is wrong...
I'll report back if I figure out more.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2010 07:27 PM
Hi Thomas,
I have performed some additional research into your issue. Currently the only supported method to use MS NLB with Nexus 1000v is to make use of Multicast mode.
Now, if you are running a Nexus 1000v version prior to 4.0(4)SV1(2), you'll also have issues with multicast mode. This is due to CSCsz93798 - MS NLB multicast addr pkts are dropped instead of getting flooded. This bug has been fixed in the 4.0(4)SV1(2) onwards, however this resolves part of the issue. This ensures the virtual machines receive the non-IP multicast frames, where as previously these frames were dropped. With the fix, now these frames will get flooded in the vlan.
The cli to add static multicast MAC entries on the Nexus 1000v is currently not available. Cisco is also planning to add this support to further limit the flooding and is being tracked by CSCtb93725 - Add support for configuring static mcast MAC entries (for MS NLB).
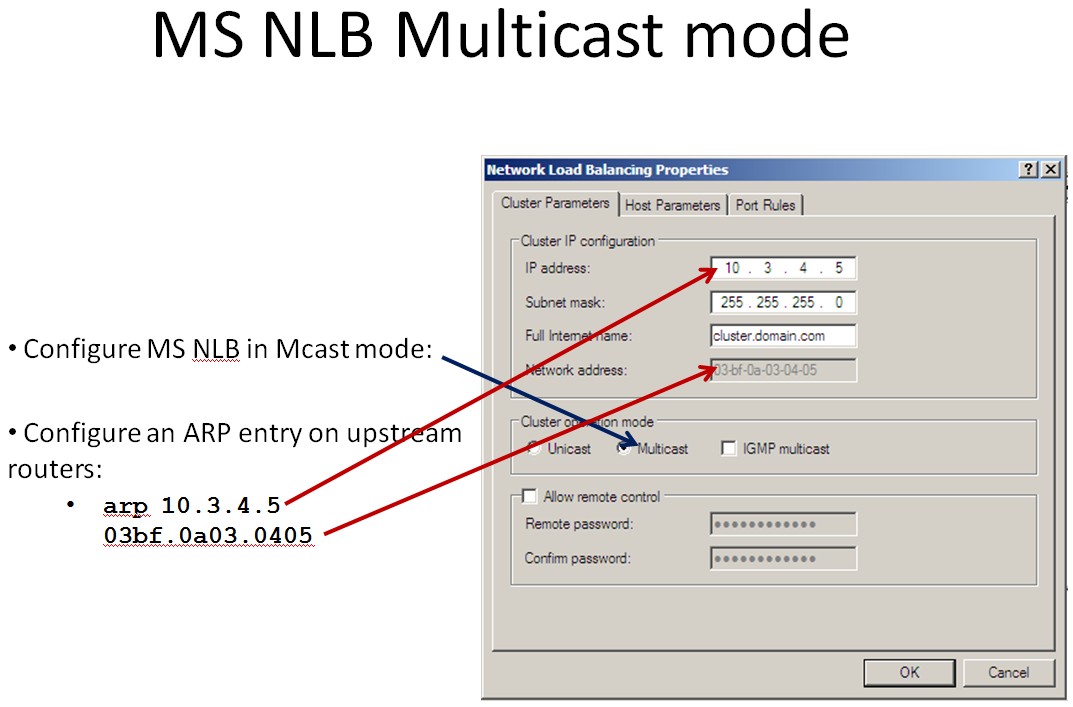
So, in order to make use of MS NLB’s multicast mode with the Nexus 1000v, it requires static ARP entries on the shared cluster IP and MAC on the upstream routers. As mentioned, in multicast mode, MS NLB traffic would be flooded in the network/vlan. This could be limited by configuring static multicast MAC entries on the upstream switches as well.
Example:
* I've attached a screenshot for the relevant information for MS NLB Multicast Mode
* Static ARP Entry:
arp 172.16.63.241 0300.5e11.1111
* Static MAC Entry:
mac-address-table static 0300.5e11.1111 vlan 200 interface fa2/3 fa2/4
Note: For Cisco Catalyst 6000/6500 series switches, you must add the disable-snopping parameter. For example:
mac-address-table static 0300.5e11.1111 vlan 200 interface fa2/3 fa2/4 disable-snooping
Further Information is available within Catalyst Switches for Microsoft Network Load Balancing Configuration Example
Hope that helps clear things up.
Thanks,
Michael
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-25-2010 12:22 AM
Hi Michael,
Is the non flood issue also valid for NX-OS 5.0.x?
We where having similar issues on our 7k's and have upgraded the NLB Servers to 2008 wich also seems to resolve the issue.
Kind Regards,
Ronny
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2011 08:56 PM
What kind of "similar" problem were you having with the 7K? We're possibly having the same sort of problem with our 7ks (we have 2 datacenters with 2 7k switches in each). We are intermittenly loosing connectivty between virtual servers and when this happens the arp entry (sometimes) resets on the 7K.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-08-2012 10:56 AM
I am seeing a problem running 610 and 710hd Blades with ESX 4.1, 10gb Pass-though and Cisco Nexus switches. What we are seeing is the interface in ESX as showing up, on the pass-though ssh session the link is showing down and on the switch port for the 2k's the link is showing down. Performing a show port link from the ssh session on the pass-though modules seems to bring the link back up. Since the link is showing as up in ESX the VMs try to use that link as well as the Mgmt. port group. Anyone seeing this issue? We are not using MS NLB. This issue typically occurs after a server reboot or port reset.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-07-2010 08:04 AM
Michael:
Will unicast be supported by the Nexus 1000v? If so what version of the Nexus 1000v? 1.3(b) or 1.4?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-06-2011 08:13 PM
Ronny,
The issue described by Bug CSCsz93798 only affects the Nexus 1000v.
Rob,
In terms of Unicast NLB support, the last I heard was that it was being investigated by the development teams. No tentative date for a potential release.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-06-2011 11:28 PM
Hi Michael
Can you maybe explain a little of what is going on with this problem becuase in bugtrack I can only get this note:
Dear valued Cisco Bug Toolkit customer, the bug ID CSCsz93798 you searched contains proprietary information that cannot be disclosed at this time; therefore, we are unable to display the bug details. Please note it is our policy to make all externally-facing bugs available in Bug Toolkit to best assist our customers. As a result, the system administrators have been automatically alerted to the problem.
hmmmm ??
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-07-2011 07:53 PM
Hi Thomas,
The reason you were receiving that error is because the release note for CSCsz93798 wasn't available publically. I have updated the release note to include the details already mentioned in this post and also make it publically viewable.
However, keep in mind that this Bug has been fixed in the 4.0(4)SV1(2) onwards. This Bug fix ensures the virtual machines receive the non-IP multicast frames, where as previously these frames were dropped.
Regards,
Michael
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-25-2011 10:49 AM
Hello,
Can you please tell me if a static mac address entry is required on both the 5010 and 1000V or just the 1000v?
Thanks
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community:

{kind=link}
{kind=link}