Cisco IOS-XE 17.14.1 for Catalyst Switching
Great news! Our newest software release, Cisco IOS-XE 17.14.1, has arrived. Filled with improvements and hardware support, this update guarantees smooth networking with our Catalyst 9000 switch lineu...

Great news! Our newest software release, Cisco IOS-XE 17.14.1, has arrived. Filled with improvements and hardware support, this update guarantees smooth networking with our Catalyst 9000 switch lineu...
What is CDN service?? It is web service that speeds up distribution of static and dynamic data.n Dynamic data includes .html, .css , .js and Image files.n CloudFront plays vital role to deliver conten...

Basic Overview :-BGP is a Path vector protocol.It uses TCP port no. 179.BGP use path vector attributes such as AS path length, local preference, origin type, and other optional attributes to determin...

There are most happening trends and there are must happen trends, we can see EVs and Smart Buildings very much in that synchrony. let me tell, why...

In Formula 1, milliseconds matter, and that’s why McLaren Racing partners with Cisco to put the team ahead on race day.

At Cisco Live Amsterdam, ThousandEyes introduces innovations for deeper visibility, streamlined tests, and improved data access. This includes Experience Insights, a new integration with Cisco Secure ...

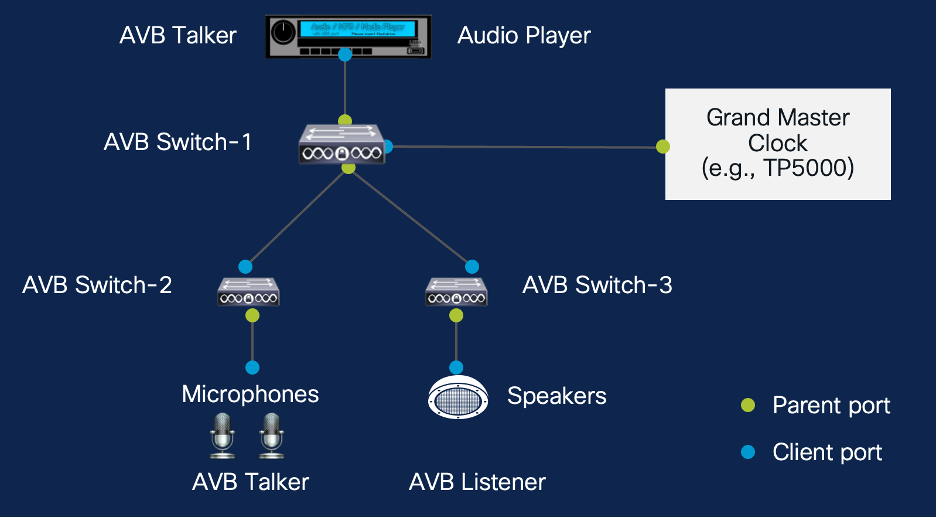
Audio Video Bridging (AVB) is a feature built on top of Precision Time Protocol (PTP). The purpose of this blog post is to discuss about AVB and its capabilities, and not to dive into PTP. Having clar...
Organizations are distributing IT infrastructure, applications, and data between on-premises, Data centers and Cloud-based environments. Applications and workloads can now reside on Private, Public o...

Read more about the recently announced ENNA specialist certification!

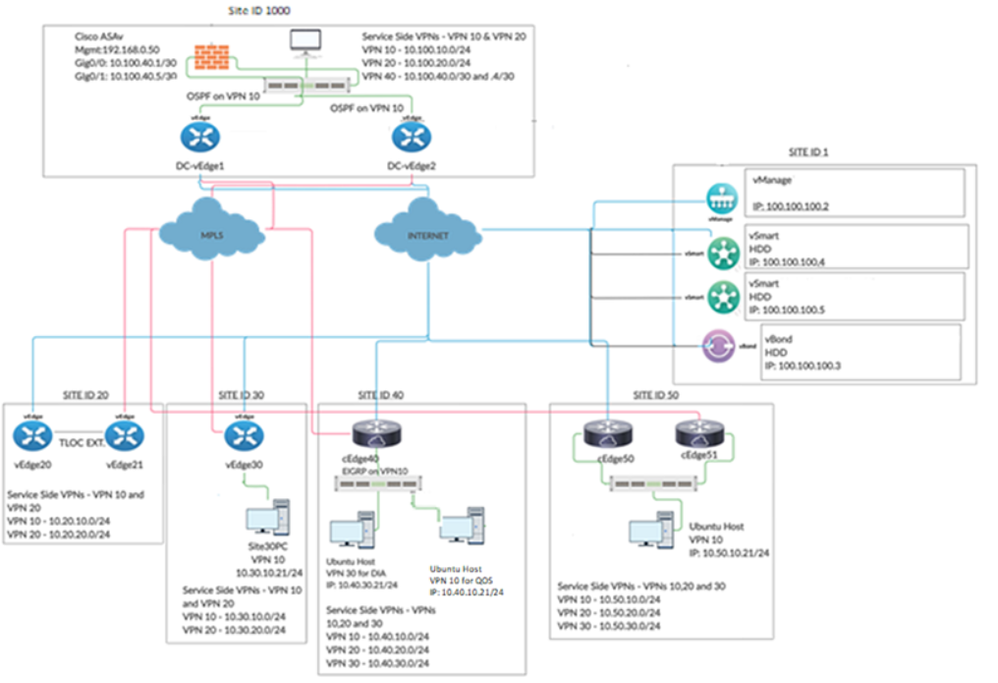
Comprehensive Lab Cisco SD-WAN on Cisco DCLOUD including Security with Umbrella, and deployment and Configuration (Full SD-WAN Lab Experience) includes a pre-deployed topology (imported on POC Tool), ...
Study Details: 15-20-minute unmoderated sessions Thank-you rewards for eligible participants: US$30 or local equivalent

Exciting news! The latest Cisco IOS-XE 17.13.1 software release is here, packed with feature enhancements and hardware enablement. This update ensures a seamless networking experience within the Catal...

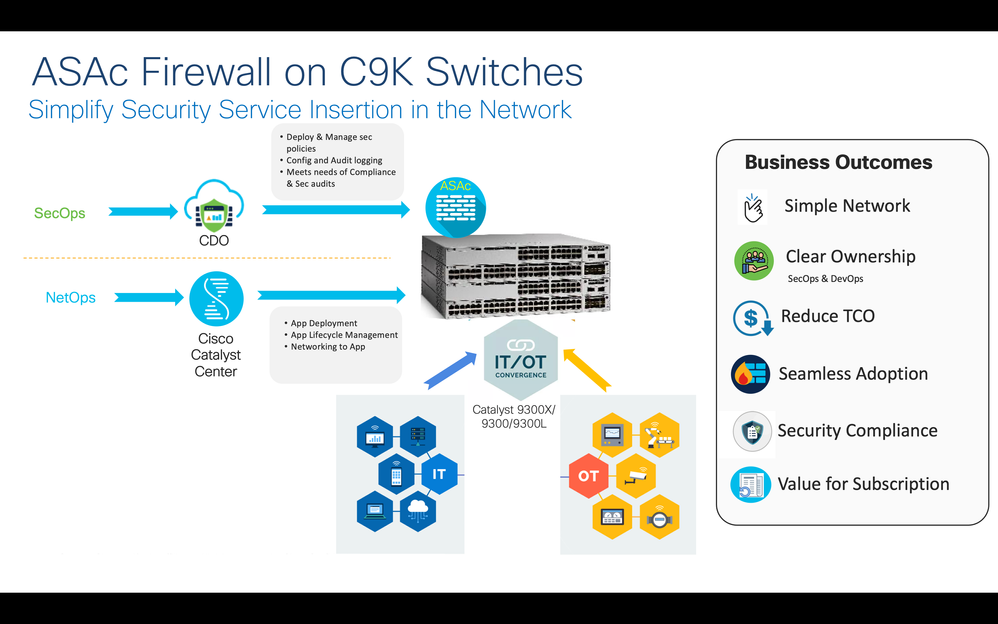
Network security refers to the practice of implementing measures to protect the integrity, confidentiality, and availability of data and resources in a network. Firewalls, such as Cisco ASA firewalls,...
Join the ranks of some of the best, brightest, and most passionate technologists. The 2024 Cisco Champion application is now open. Apply by January 12, 2024. As a Cisco Champion, you will: Get early...

As Campus Access ‘downlink’ speeds (e.g., 2.5G, 5G and 10G) and the number of Access switches continue to grow, this forces Enterprises to also increase the ‘uplink’ speeds and number of links to Core...