- Cisco Community
- Technology and Support
- Networking
- Routing
- Redundant OSPF over an unreliable subnet
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Redundant OSPF over an unreliable subnet
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-25-2013 04:03 AM - edited 03-04-2019 07:43 PM
Good morning specialists,
We are facing a challanging design to provide a redundant link between two networks.
The diagram below shows the Internet at the left with two edge routers. At the right side there are two demarcation routers that provide access to customer subnets. The customer needs to connect these subnets to the service provider in a redundant way. Our intention was to use OSPF, but it proves to be more challenging than expected.
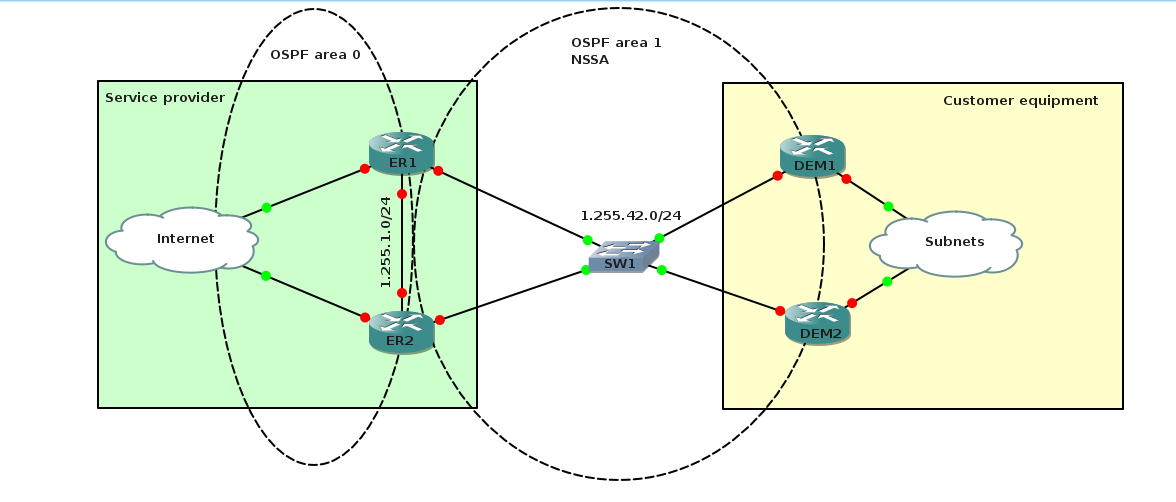
All routers are connected to the same subnet. The subnet however can't be trusted. What on the diagram appears as a single switch, can be a complex switched network including transparent firewalls and other devices. That means that the interface towards the subnet can be up, but traffic can't reach the other routers.
The question is now if OSPF can be used to provide a robust, redundant connection between the customer and service provider.
Assume that something is wrong along the path between ER1 and the subnet. The interface of ER1 is still up, but traffic can't reach the other routers over this interface.
Issues we faced up to now:
* When there is a link between ER1 and ER2 in area 1, then the dem routers learn a default route from ER1 even when the link between ER1 and the subnet is not functional. When the link between ER1 and ER2 is in area 0, then the dems learn the default route only from ER2.
* The dems advertise the customer subnets using type 7 LSA, but they include the forward address. ER1 learns the customer subnets as a type 5 LSA from ER2, but ER1 sees that the forwards address is in the range 1.255.42.0/24 which is a local subnet for ER1 and ER1 will attempt to use the interface towards the subnet while it fails.
Is there a more easy way to make OSPF robust with four routers on an unreliable subnet?
- Labels:
-
Routing Protocols
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-25-2013 10:34 AM
Disclaimer
The Author of this posting offers the information contained within this posting without consideration and with the reader's understanding that there's no implied or expressed suitability or fitness for any purpose. Information provided is for informational purposes only and should not be construed as rendering professional advice of any kind. Usage of this posting's information is solely at reader's own risk.
Liability Disclaimer
In no event shall Author be liable for any damages whatsoever (including, without limitation, damages for loss of use, data or profit) arising out of the use or inability to use the posting's information even if Author has been advised of the possibility of such damage.
Posting
Have you considered reducing OSPF hello intervals or using fast-hellos?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-25-2013 11:42 PM
This main issue is regarding to convergence time, isn't it?. At the end, does the topology work fine?.
As previous post suggests reducing hello intervals could be fine. Remember that the timer to consider
a neihbor down (and flush its routes) is the hold time (by default 4xHellotimer -> 40 seconds).
There is another solution uses mainly when a link fail but the interface does not go down (MPLS). It it
Bidirectional Forwarding Detection. You can detect in millisecond the link problem and OSPF adjacencies fall down automatically. Besides you can explicit tell OSPF process to use it in the interfaces you want. Check your IOS to find
out if this feature is supported.
Regards.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-25-2013 11:57 PM
The problem is not about the convergance time.
The problem is that the topology in the end doesn't work.
When the connection from ER1 to the subnet is broken somewhere along the path, ER1 will not detect this and the OSPF topology database will still contain a route to the customer subnets via the broken subnet. So the network is broken.
I think the solutions can be found in your second remark regarding Bidirectional Forwarding Detection. I never heard of this feature before, but a quick glance at the topic looks promising. Thanks for that suggestion.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-26-2013 02:47 AM
Disclaimer
The Author of this posting offers the information contained within this posting without consideration and with the reader's understanding that there's no implied or expressed suitability or fitness for any purpose. Information provided is for informational purposes only and should not be construed as rendering professional advice of any kind. Usage of this posting's information is solely at reader's own risk.
Liability Disclaimer
In no event shall Author be liable for any damages whatsoever (including, without limitation, damages for loss of use, data or profit) arising out of the use or inability to use the posting's information even if Author has been advised of the possibility of such damage.
Posting
Pieter Lauwers wrote:
The problem is not about the convergance time.
The problem is that the topology in the end doesn't work.
When the connection from ER1 to the subnet is broken somewhere along the path, ER1 will not detect this and the OSPF topology database will still contain a route to the customer subnets via the broken subnet. So the network is broken.
Could you clarify a broken subnet/path, that doesn't pass data traffic, but still passes OSPF hellos? Normally, if a path breaks where it doesn't pass data, OSPF hellos fail too, and when they do, OSPF will stop directing traffic across it.
There are situations where the path being crossed doesn't fail 100%, but lots of packets are lost across it, so you want to stop using it. By default, in this situation OSPF might keep the link up or flap. A possible solution is to allow OSPF to fail on one or two lost hellos and then "dampen" the interface so it doesn't immediately come back up when the next hello succeeds to pass.
Other complex solutions might use some form of EEM scripting, to analyze a hop and take some action.
I think the solutions can be found in your second remark regarding Bidirectional Forwarding Detection. I never heard of this feature before, but a quick glance at the topic looks promising. Thanks for that suggestion.
BFD, on some platforms also works with OSPF hellos. Most useful in you have lots of links with low hello intervals, especially if trying to support sub-second hellos.
There's also object tracking, using a form of SLAs, that will detect loss of connectivity, but those are only normally used when the routing protocol doesn't support a logical failure method (e.g. static routes) or the routing protocol doesn't natively have a high speed logical break detection (e.g. BGP).
If your routers support it, PfR (w/PIRO) can analyze end-to-end performance, and change (override) routes on the fly.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-26-2013 04:17 AM
To clarify the broken subnet:
ER1 is connected to the 1.255.42.0 subnet, but there is a tranparent firewall in between ER1 and the switch. In the case that the firewall is no longer connected to the switch, ER1 can't send any traffic over the 1.255.42.0 subnet (so no OSPF hello's), but it's interface towards the subnet remains operational.
The problem is that DEM1 advertises the cutosmer subnets in an LSA that contains the field:
Forwarding Address = 1.255.42.101 (The address of DEM1 in the subnet).
ER1 still receives this LSA, not directly from DEM1 over subnet 1.255.42.0, but via ER2. So ER1 learns that it can reach the customer subnet via 1.255.42.101. And since ER1 has an active interface in that subnet, it will try to route all packets to the customer subnet over it's interface in 1.255.42.0. And that doesn't work.
So I need a technique to force OSPF to ignore the link in subnet 1.255.42.0 when it can't find any neighbors on that subnet.
An alternative I found is to configure the DEM in such a way that it puts one of its loopback addresses as the "Forwarding Address". This could also help.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-26-2013 04:57 AM
Hello again,
I understand the problem, next-hop is reached by a link that does not work. I like the advanced solutions but
I prefer designs with simpler solution. Your solution is simple. Divide the link with VLANS to bypass the problem
of nexthop to a directed connected link next-hop. Tune the hello and dead timer until your opinion is a good
converge time. After dead time, ER1 adjancencies using failed link will be down. The nexthop learned by ER2
won't be directed connected (another subnet an VLAN).
Regards.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-26-2013 11:10 AM
Disclaimer
The Author of this posting offers the information contained within this posting without consideration and with the reader's understanding that there's no implied or expressed suitability or fitness for any purpose. Information provided is for informational purposes only and should not be construed as rendering professional advice of any kind. Usage of this posting's information is solely at reader's own risk.
Liability Disclaimer
In no event shall Author be liable for any damages whatsoever (including, without limitation, damages for loss of use, data or profit) arising out of the use or inability to use the posting's information even if Author has been advised of the possibility of such damage.
Posting
I don't believe OSPF should work exactly as you describe, but I could be mistaken.
In any case, I can see the issue you describe for ER1 trying to reach hosts on a subnet it believes it has a valid up/up interface on.
The issue really then is don't have a router with an interface that may show up/up when in fact it doesn't have reachability, yet there's another valid path.
The solution might be as simple as using a different subnet for transit connectivity between your ER routers and your DEM routers. It's not as efficient, as it forces traffic to make an extra L3 hop, but it will guarantee reachability if there's a valid path.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-26-2013 01:10 AM
Hello again,
I supposed than BFD could be the best features because interface is down and then the connected subnet should
dissapear from routing table.
If your IOS does not support this feature, and if you L2 topology supports it, you can use VLAN's to create differents
subnets (perhaps point-to-point links). In this topology, the problem in ER1, after the link fails (and the interface is still
up), should be bypassed. The next-hop would not be directly connected.
BFD is a good solution but in my experience the best solutions are the simplest.
Regards
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide
