Cisco Champion 2024 Application is now open!
Join the ranks of some of the best, brightest, and most passionate technologists. The 2024 Cisco Champion application is now open. Apply by January 12, 2024. As a Cisco Champion, you will: Get early...

Join the ranks of some of the best, brightest, and most passionate technologists. The 2024 Cisco Champion application is now open. Apply by January 12, 2024. As a Cisco Champion, you will: Get early...
Hello all, Starting today we are pleased to announce that TAC powered triage scripts are available for customer use. The first release only has a small number of features supported but we want to ge...

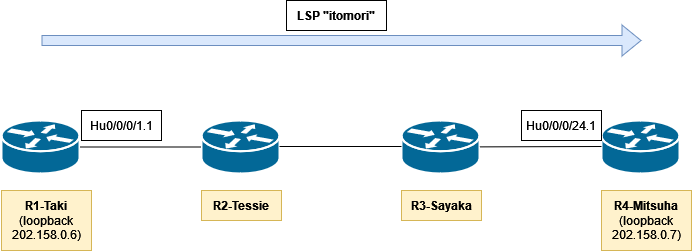
Introducing MPLS-TE Self-Ping feature in IOS XR 7.5.3:Start using reoptimized LSP in miliseconds instead of seconds!
Listen: https://smarturl.it/CCRS9E19Follow us: https://twitter.com/CiscoChampionNetworks can be complex and often unpredictable. Traffic from over-the-top applications, automated systems, malicious a...

Listen: https://smarturl.it/CCRS9E15 Follow us: https://twitter.com/CiscoChampion Standing up and operating a mobile 5G network can be a challenging task, but Private 5G doesn’t need to be. Now, th...

Listen: https://smarturl.it/CCRS9E7Follow us: twitter.com/ciscochampion Routed optical networking, part of the Converged SDN Transport Architecture, is a new network paradigm that delivers improved o...

The IT Blog Awards, hosted by Cisco, aims to recognize all of the amazing technology content creators who contribute to our community all year long. Now it's up to you to weigh in. Be sure to vote fo...

The Cisco Champion 2022 program is accepting applications. Members are recognized for their social engagements, content creation and private advocacy. You will have access to ongoing and exclusive eng...

Listen: https://smarturl.it/CCRS9E2 Follow us: https://twitter.com/ciscochampion The internet has grown exponentially for over 30 years and will soon surpass 30 billion connected devices. Yet, even fo...

Listen: smarturl.it/CCRS8E48 Follow us: twitter.com/CiscoChampion One word describes the life of network operations, and that word is complex. It’s no wonder when your responsibility is to maintain mu...

The 2021 IT Blog Awards, hosted by Cisco, is now open for submissions. Submit your blog, vlog or podcast today. For more information, including category details, the process, past winners and FAQs, ch...

Listen: https://smarturl.it/CCRS8E39 Follow us: twitter.com/CiscoChampion5G and Wi-Fi 6, the next generation of mobile wireless technologies are here! But what does that mean? Where and how is 5G bein...

IOS-XR MPLS TE Auto Tunnel Backup Bandwidth Protection Current Implementation of MPLS TE Auto Tunnel BackupPotential issue with current implementation of MPLS TE auto tunnel backupEnhancement to MPLS ...

we are trying to monitor the Cisco 9148s SFP status, and have get the Sensor's dBm value from the CISCO-ENTITY-SENSOR-MIB table, meanwile , it has an Index value like "30000xxxx",such as "30001773", e...

Check out our latest release on Cisco Routed Optical Networking solution. Listen: https://smarturl.it/CCRS8E24Follow us: https://twitter.com/ciscochampion Disruptive network transformation may only h...





