- Cisco Community
- Technology and Support
- Networking
- Switching
- Datacenter outage. %ETHCNTR-3-LOOP_BACK_DETECTED
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Datacenter outage. %ETHCNTR-3-LOOP_BACK_DETECTED
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2012 06:15 AM - edited 03-07-2019 05:09 AM
Hi
This is big, i have a problem in one datacenter, and i really need some help. I already open a TAC case but meanwhile i want to discuss this problem that i`m facing. Come on guys, this is big. I have a datacenter like in the diagram, in the diagram i have only two rack but in reality there are more . We are migratig some machines from phisical to virtual (vmware). This is the diagram 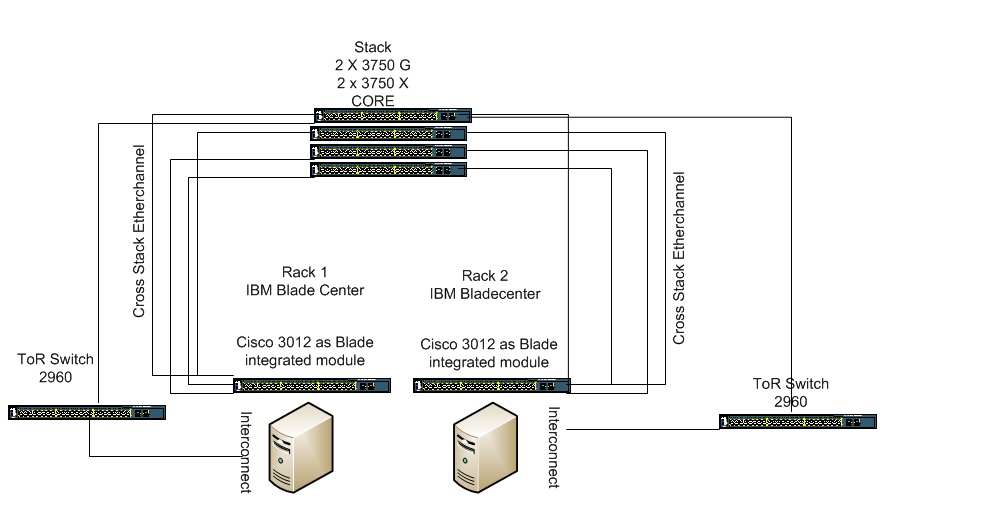
I have a core of mixted 2X3750G and X using the latest IOS. One of the G switches is the master of the stack.
The design worked ok for some weeks then suddenly almost all the 3012 etherchannel uplinks goes into Err-disable with this error.
%ETHCNTR-3-LOOP_BACK_DETECTED: Keepalive packet loop-back detected on FastEthernet0/3.
%PM-4-ERR_DISABLE: loopback error detected on Fa0/3, putting Fa0/3 in err-disable state
%ETHCNTR-3-LOOP_BACK_DETECTED: Keepalive packet loop-back detected on FastEthernet0/3.
%PM-4-ERR_DISABLE: loopback error detected on Fa0/3, putting Fa0/3 in err-disable state
(of course i`m using gigabit ,the error message is copy paste from some documentation but the error is the same)
The only workaround was to disable the keepalives on that interfaces. I run some testing on cables all the test were fine. I looked into spanning tree problems/logs everything is fine.As soon as i put the keepalives back on 3012 etherchannel interfaces the port enters err-disabled state.
Any ideeas ?
PS I`m no vmware guy but is there any chances that some virtual machines caused this ?
- Labels:
-
Other Switching
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2012 08:31 AM
Hi,
This from the error decoder tool
1.
%ETHCNTR-3-LOOP_BACK_DETECTED:
, Loop-back detected on [chars]. The port is forced to linkdown.
This message means that a loopback condition might be the result of a balun cable incorrectly connected into a port. [chars] is the port.
Recommended Action: On non-PoE switches, check the cables. If a balun cable is connected and the loopback condition is desired, no action is required. Otherwise, connect the correct cable, and then enable the port up by entering the no shutdown interface configuration command.
Related documents- No specific documents apply to this error message.
Regards
Alex
")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2012 08:59 AM
Hi Adrian,
For an in-depth discussion of what are the LOOP frames that are activated/deactivated using the keepalive commands, see this (lengthy) thread:
https://supportforums.cisco.com/thread/2001389
What you are experiencing is caused by some devices sending the LOOP frames back to the switches and their ports where these LOOP frames were sent from. The hard question is - which device is doing this?
The most obvious reason would be a switching loop in your network but I assume you have double and triple checked the show spanning-tree outputs on all switches and verified with utmost scrutiny that all ports are placed in the exact STP role and state as they are supposed to be. If not then this is the first thing to do, and to do very, very carefully.
I see you are using cross-stack EtherChannels. What signalling protocol are you using? Are the Port-Channels configured with LACP or with just the "on" mode? Are all devices reporting all bundled ports as (SU), i.e. successfully bundled, in the show etherchannel summary output?
Are the servers and/or the VMWare configured to perform any kind of switching/bridging?
Best regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2012 11:17 PM
Thanks a lot for this brief and excelent explanation , the Port-channels are LACP and succesfully bundled. The spanning tree looks ok ,but i have to check it again. There are lots and lots of vlans and output, in need to do it again.
The thing that puzzlez me is why almost ALL the uplinks have gone in err-disabled in the matter of seconds. Looking at the logs in under 30 seconds more than 50 ports situated in different racks have failed. The root of the RSTP is the stack.The last change in the network infrastructure was adding to the stack the 2X 3750X switches , but for almost a month there was no problem. The only change in the infrastructure in the days were some migration of virtual machines.
Reading the link that you gave me my mind does not comprehend how ALL the uplinks were afected. I get it ...a loop condition, but on ALL the 3012 switches ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-25-2012 12:51 AM
The is a chance that there is a software error / bug / interoperability problems between 3750x and 3750G switches in the stack ? Have any of you experienced problems with mixed 3750 stacking ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-25-2012 02:09 AM
Hello Adrian,
I am not aware of any interoperability issues. Then again, I am not using them myself and I am merely reflecting upon my best knowledge and overview of what issues have been discussed on these forums so far.
The information about the ports going to err-disabled state in seconds means that the ports receive their own LOOP frames back in seconds which is quite interesting - the LOOP frames are sent infrequently, once every 10 seconds or so. Is the time between reactivating the keepalive and err-disabling the port shorter than 10 seconds?
Anyway, questions and suggestions to play with:
- What kind of STP are you using? Are there any special features, protections or guards implemented (PortFast, UplinkFast, BackboneFast, BPDU Loop Guard, UDLD, ...)?
- How are the uplinks between blade switches and the stack configured - are they trunks or access ports? Are the usual settings correct - encapsulation, native/access VLAN, identical list of allowed VLANs, ...?
- On the blade switch, look up the MAC address of the particular switchport that got err-disabled in the past (use the show interface command on the blade switch and look for the "bia" string). Then, on the switch stack, look up this MAC address in the CAM table. What port is it learned on? Is it pointing back to the correct port on the blade switch, or at least back the correct Port-channel interface?
- Using the MAC address of the blade switch' port that got err-disabled, enter the following command on the stack:
show platform forward INTERFACE M.M.M M.M.M
where INTERFACE is the physical switchport on the stack that is connected back to the formerly err-disabled port on the blade switch, and M.M.M is the MAC address of the blade switch' port. You may also verify using the show mac address-table address M.M.M that this MAC address is indeed learned on the physical interface or on a Port-channel interface that includes this physical switchport. The point of the show platform command is to verify if this switch is going to forward the frame or drop it - naturally, it should drop it. The switch should produce a rather lengthy output that should end with the following statement: "Dropped due to failed deja vu check.". If any other output is produced, I would need to see the output in its entirety. - Using the show mac address-table learning, verify on each switch that the learning of MAC addresses has not been disabled on any of your VLANs.
- Verify using the show controllers utilization if any of the ports shows excessive utilization - that would suggest a switching loop in progress.
- Consider activating UDLD Agressive on all physical switchports between the blade switch and the stack. UDLD is also capable of detecting a looped port and could perhaps provide additional information. You can implement UDLD gradually, on a per-port basis and see if it brings down the port, and if so, with what explanation.
Best regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-25-2012 03:20 AM
Peter , a simple thank you is not enough to express how gratefull i am for the advices that you are giving me. Hat off in front of you. Seeing that so much trobleshooting work i have to do maybe i won`t respond during this weekend to let you know how it worked out.
On the tehnical side of things, yes the interface goes down in matter of 2-3 seconds , almost as soon as i enter "no shutdown" The STP flavour is RSTP , no fancy configurations here, just the stack is set to be the root of the topology.
After this problems i put on some ports UDLD port but not agressive. The Network is live and mission critical , and it`s surving thanks to the " no keepalive" command for this i haven`t used the agressive atribute.I haven`t received aditional error from UDLD. To check the mac address of the switchport is a great ideea and i will let you know how things are working out. I already opened a TAC official case regarding this matter.
With great respect ,
Brunhuber Adrian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-25-2012 05:03 AM
Hello Adrian,
You are very much welcome!
Please keep me informed about the results of your tests. Also, if the TAC comes with something interesting, please do share that with us. This issue is quite intriguing and I would like to see it resolved
Best regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2015 10:27 AM
I recently had very similar problem when suddenly all uplinks on a switch in a datacenter went into err-disable state due to %ETHCNTR-3-LOOP_BACK_DETECTED.
After some research i discovered that the issue was created by a forgotten RSPAN session where a remote-span VLAN while non-pruned from a trunk interface injected back into a switch captured its ethernet keepalive packets.
The problem was apparently triggered by a RSTP topology change (say a port moved into forwarding state), when CAM tables is flushed and all keepalives flood the LAN for a short period of time, this is when they were captured by the forgotten RSPAN session and fed back into the switch tagged by remote-span VLAN.
HTH someone,
--fedya
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community:
