- Cisco Community
- Technology and Support
- Networking
- Switching
- Interesting STP Issue
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-12-2013 08:16 AM - edited 03-07-2019 02:22 PM
All,
We ran into an interesting situation the other day with STP, and wanted to get some thoughts from the community.
While prepping for a maintenance, we noticed inbound traffic on an STP forwarding link from our dist layer, but this link was in the blocking state on the access switch side. (so forwarding toward the access layer switch on the link from the distribution's perspective, and blocking toward the distribution layer switch from the access switch's perspective).
We were learning no MAC's on this link (in either direction) and CEF and the adj tables plus ARP clearly showed that layer 2 was mapped to the link between the dist and access that was in the forwarding state for *both* dist and access.
We took a wireshark cap for both tx and rx on the link that was in the blocking state, and clearly had traffic on that link.
I labbed this up with two 3560's ( representing the dist layer) and a 4948 (as the access switch) to replicate our environment, and noticed the same results.
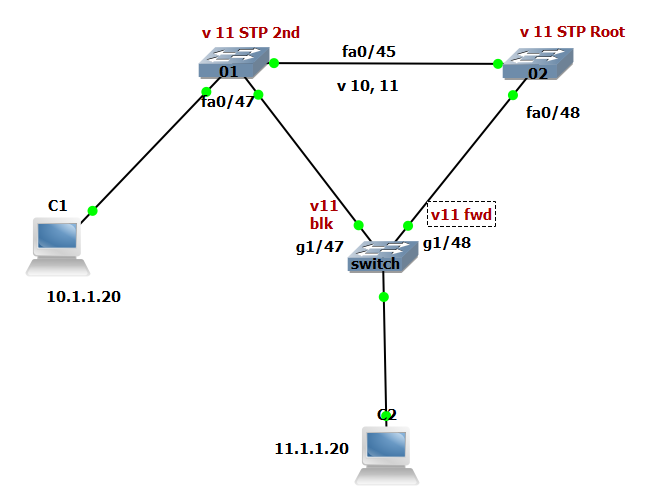
Below is my lab topo, and this represents the same physical topo as well as the logical flow of data (when compared to our live production environment):
Here is the output from the ports:
3560-01#sh spanning-tree vlan 11
VLAN0011
Spanning tree enabled protocol ieee
Root ID Priority 4107
Address 000a.b815.2a80
Cost 19
Port 49 (FastEthernet0/45)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 8203 (priority 8192 sys-id-ext 11)
Address 001d.4530.a080
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 300
Interface Role Sts Cost Prio.Nbr Type
---------------- ---- --- --------- -------- --------------------------------
Fa0/45 Root FWD 19 128.49 P2p
Fa0/47 Desg FWD 19 128.51 P2p
3560-02#sh spanning-tree vlan 11
VLAN0011
Spanning tree enabled protocol ieee
Root ID Priority 4107
Address 000a.b815.2a80
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 4107 (priority 4096 sys-id-ext 11)
Address 000a.b815.2a80
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 300
Interface Role Sts Cost Prio.Nbr Type
---------------- ---- --- --------- -------- --------------------------------
Fa0/45 Desg FWD 19 128.49 P2p
Fa0/48 Desg FWD 19 128.52 P2p
Switch#sh spanning-tree vlan 11
VLAN0011
Spanning tree enabled protocol ieee
Root ID Priority 4107
Address 000a.b815.2a80
Cost 19
Port 48 (GigabitEthernet1/48)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 32779 (priority 32768 sys-id-ext 11)
Address 001d.a2a5.e840
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 300 sec
Interface Role Sts Cost Prio.Nbr Type
------------------- ---- --- --------- -------- --------------------------------
Gi1/45 Desg FWD 4 128.45 P2p
Gi1/47 Altn BLK 19 128.47 P2p
Gi1/48 Root FWD 19 128.48 P2p
GigabitEthernet1/47 is up, line protocol is up (connected)
Hardware is Gigabit Ethernet Port, address is 001d.a2a5.e86e (bia 001d.a2a5.e86e)
MTU 1500 bytes, BW 100000 Kbit, DLY 100 usec,
reliability 255/255, txload 1/255, rxload 44/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Full-duplex, 100Mb/s, link type is auto, media type is 10/100/1000-TX
Media-type configured as RJ45 connector
input flow-control is off, output flow-control is off
ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:00, output never, output hang never
Last clearing of "show interface" counters never
Input queue: 0/2000/0/0 (size/max/drops/flushes); Total output drops: 0
Queueing strategy: fifo
Output queue: 0/40 (size/max)
30 second input rate 17467000 bits/sec, 1462 packets/sec
30 second output rate 0 bits/sec, 0 packets/sec
3274124 packets input, 4870576976 bytes, 0 no buffer
Received 10136 broadcasts (9431 multicasts)
0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored
0 input packets with dribble condition detected
400 packets output, 72495 bytes, 0 underruns
0 output errors, 0 collisions, 2 interface resets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier
0 output buffer failures, 0 output buffers swapped ou
Switch#sh int g1/48
GigabitEthernet1/48 is up, line protocol is up (connected)
Hardware is Gigabit Ethernet Port, address is 001d.a2a5.e86f (bia 001d.a2a5.e86f)
MTU 1500 bytes, BW 100000 Kbit, DLY 100 usec,
reliability 255/255, txload 4/255, rxload 173/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Full-duplex, 100Mb/s, link type is auto, media type is 10/100/1000-TX
Media-type configured as RJ45 connector
input flow-control is off, output flow-control is off
ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:00, output never, output hang never
Last clearing of "show interface" counters never
Input queue: 0/2000/0/0 (size/max/drops/flushes); Total output drops: 0
Queueing strategy: fifo
Output queue: 0/40 (size/max)
5 minute input rate 67883000 bits/sec, 5703 packets/sec
5 minute output rate 1718000 bits/sec, 3052 packets/sec
9849861 packets input, 14683807717 bytes, 0 no buffer
Received 8769 broadcasts (8761 multicasts)
0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored
0 input packets with dribble condition detected
5250548 packets output, 367686172 bytes, 0 underruns
0 output errors, 0 collisions, 0 interface resets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier
0 output buffer failures, 0 output buffers swapped out
Switch#sh monitor session 1
Session 1
---------
Type : Local Session
Source Ports :
Both : Gi1/47
Destination Ports : Gi1/40
Encapsulation : Native
Ingress : Disabled
Learning : Disabled
Filter Pkt Type :
RX Only : Good
Switch#sh vlan id 11
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
11 VLAN0011 active Gi1/45, Gi1/47, Gi1/48
VLAN Type SAID MTU Parent RingNo BridgeNo Stp BrdgMode Trans1 Trans2
---- ----- ---------- ----- ------ ------ -------- ---- -------- ------ ------
Thoughts?
Solved! Go to Solution.
- Labels:
-
Other Switching
Accepted Solutions
")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-14-2013 03:16 PM
Hi James,
Allow me to comment on both your responses in my single post here.
I would agree with this, but if this was the scenario, wouldn't the traffic from the 'dist' layer be intermittent, and only fire off when the MAC table lost it's entries
It will indeed fire off when the MAC table contents for the particular MAC address table expire. However, the appearance of unicast traffic flooding may not be intermittent at all. If for C1, the 01 is the default gateway while for C2, the 02 is the default gateway, then the traffic from C1 to C2 is routed on 01 and flows to C2, however, replies from C2 to C1 flow through 02. Because of this, 01 actually never receives unicast frames from C2 (as they are addressed to the default gateway on 02) and after 5 minutes (or even sooner in case of STP topology change), the MAC address of C2 expires from 01. Unless C2 sends itself an unknown unicast/multicast/broadcast frame or a frame that has to pass through 01, this switch will not know the MAC address of C2, resulting into flooding of unicast frames indefinitely.
Also, do you happen to know if the timers for CEF and the adjacency table mirror the ARP and MAC timers?
To my knowledge, the CEF FIB and ADJ tables should not be timer-driven, rather, they should be event-driven and updated whenever the routing table or the ARP table is updated. The timers in show cef timers are, in my personal opinion, timers for processes that perform consistency checks, however, immediate changes to FIB/ADJ are the result of routing or ARP table change event and not the result of waiting for a timer to expire.
I believe this confirms that asymmetric routing is taking place. If you concur, I will mark the question as answered.
It looks to me that this is exactly the case. What I can suggest is lowering the ARP refresh interval down to roughly 4 minutes (slightly shorter than the CAM expiration time which is 5 minuts by default) using the arp timeout 240 interface level command. Thanks to this, your switches will refresh their ARP tables before the CAM tables expire, and refreshing them in the process. Please verify whether this change helps you.
Best regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-12-2013 01:48 PM
Hello James,
Receiving traffic on a Blocking/Discarding port is normal if the traffic is considered unknown unicast/multicast/broadcast by the very switch that has the Designated port for the link.
The traffic you have captured here appears to be unicast traffic from 10.1.1.20 to 11.1.1.20. Such a traffic should not leak out a Designated port towards a Blocking/Discarding port. The fact that it is leaking suggests that for some reason, it is considered to be unknown unicast by your switch.
The 10.1.1.20 and 11.1.1.20 are not in the same VLAN, are they? Can you please describe in more detail how is the inter-VLAN routing accomplished in your network? What is the STP topology of the other VLAN (here, you've described the STP in VLAN 11)? Would the scenario for unicast flooding described in the following document apply to your situation?
http://www.cisco.com/en/US/tech/tk648/tk362/technologies_tech_note09186a0080094afd.shtml#t8
Best regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2013 04:41 PM
Peter,
So, yes, we are familiar with the way that frames are forwarded in the network with regard to broadcast, multicast, and unknown unicast, and this is the cause of the confusion. This all started with our production network, and when I first looked at the capture, the 'unknown unicast' was my first guess b/c we didn't see that much multicast, or broadcast in the capture. However, when I labbed this up with my switches, I received the same behavior, and figured something else was going on.
To answer your questions about my lab topo, V10 is STP root on 3560-01, and secondary on -02, and with regard to HSRP, they follow the STP topo, so V11 is active on -02 and standy on -01, and V10 is standby on -02 and active on -01. V10 is not allowed on the trunks down to 'switch', it is only on the -01 to -02 link.
I've read through that document you provided, and I plan on turning the lab up again to see what happens with the timers, but in the doc, it seems to suggest that the CAM table is aging out before the ARP table, which can cause this behavior?
I would agree with this, but if this was the scenario, wouldn't the traffic from the 'dist' layer be intermittent, and only fire off when the MAC table lost it's entries (actually, this may be happenning, but i'd have to do a capture for the entire MAC aging time to see this behavior)?
Also, do you happen to know if the timers for CEF and the adjacency table mirror the ARP and MAC timers?
I've looked at some documentation so far, and from the output of the 'show cef timers' those values look to be substantially smaller than the ARP and MAC timers.
James
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-14-2013 06:12 AM
Peter,
As a follow up to my earlier post, I wanted to let you know the results of my lab tests.
I began a 10 GB transfer from 10.1.1.20 to 11.1.1.20, and noticed no output traffic on fa0/47 when looking at the interface from 3560-01, but did see output on fa0/48 and input on g1/48 on 3560-02 and switch respectively. This was expected.
To test the theory of asymmetric routing from the doc you provided, I issued a 'clear mac-address' command for V11 on 3560-01 and I could immediately see output traffic increase dramatically on fa0/47 for 3560-01. I then sent a ping from 11.1.1.20 to 11.1.1.11 (the SVI for V11 on 3560-01) and noticed output traffic begin to decrease on fa0/47.
I believe this confirms that asymmetric routing is taking place. If you concur, I will mark the question as answered.
Thank you for your assistance.
James
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-14-2013 03:16 PM
Hi James,
Allow me to comment on both your responses in my single post here.
I would agree with this, but if this was the scenario, wouldn't the traffic from the 'dist' layer be intermittent, and only fire off when the MAC table lost it's entries
It will indeed fire off when the MAC table contents for the particular MAC address table expire. However, the appearance of unicast traffic flooding may not be intermittent at all. If for C1, the 01 is the default gateway while for C2, the 02 is the default gateway, then the traffic from C1 to C2 is routed on 01 and flows to C2, however, replies from C2 to C1 flow through 02. Because of this, 01 actually never receives unicast frames from C2 (as they are addressed to the default gateway on 02) and after 5 minutes (or even sooner in case of STP topology change), the MAC address of C2 expires from 01. Unless C2 sends itself an unknown unicast/multicast/broadcast frame or a frame that has to pass through 01, this switch will not know the MAC address of C2, resulting into flooding of unicast frames indefinitely.
Also, do you happen to know if the timers for CEF and the adjacency table mirror the ARP and MAC timers?
To my knowledge, the CEF FIB and ADJ tables should not be timer-driven, rather, they should be event-driven and updated whenever the routing table or the ARP table is updated. The timers in show cef timers are, in my personal opinion, timers for processes that perform consistency checks, however, immediate changes to FIB/ADJ are the result of routing or ARP table change event and not the result of waiting for a timer to expire.
I believe this confirms that asymmetric routing is taking place. If you concur, I will mark the question as answered.
It looks to me that this is exactly the case. What I can suggest is lowering the ARP refresh interval down to roughly 4 minutes (slightly shorter than the CAM expiration time which is 5 minuts by default) using the arp timeout 240 interface level command. Thanks to this, your switches will refresh their ARP tables before the CAM tables expire, and refreshing them in the process. Please verify whether this change helps you.
Best regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-14-2013 03:52 PM
guys, dont mean to derail your thread but something has confused me...if a switch sends traffic on its DESG port, and the other end of the link is connected to a port that is in the BLK state, what does the switch with the BLK port do with the received traffic? It should totally ignore it and kill it, no?? And anyway, I thought that because it is a BLK port, it should be denying/filtering/blocking all traffic but STP BPDUs and multicast control plane traffic in the first place....
HELP! 🙂
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-14-2013 05:10 PM
Visitor,
The way i've always read the BLK on a port is that the switchport that is in this state will not forward traffic, but will (as you mention) process BPDU's as it has to for STP.
Since the capture shows that the port is receiving traffic, I would say that if it's dropping it, it's happening after the port processes it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-14-2013 11:38 PM
Hello,
James is correct. A port in the STP Blocking or Discarding state must receive and process BPDUs because it is precisely because of these BPDUs that the port knows it should be blocked. If a Blocking/Discarding port in STP started dropping all traffic including BPDUs, it would be throwing away exactly those messages that inform it that it is supposed to remain blocked. This is one of fundamental things in STP to keep in mind: a port always processes received BPDUs, no matter what role and state it is in. If it stopped processing received BPDUs, it would have no information to decide what role and state it should place itself into.
So a Blocking/Discarding port truly discards normal data traffic but it continues to receive and process, even transmit, Layer2 management traffic that is processed in a hop-by-hop fashion and thus is not flooded, thereby not capable of creating a switching loop. This management traffic includes CDP, LLDP, VTP, DTP, STP, LACP, PAgP. You have surely noticed that in show cdp neighbor, for example, you keep on seeing neighboring switches, even if their port towards you is in the Blocking/Discarding state. Note that each of these protocols has its frames processed exactly by the very neighboring device. They are not flooded, rather, they are received by the neighbor and processed in the operating system.
Best regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-15-2013 06:21 AM
Peter, i agree - all you did was reiterate exactly what I wrote in my post. As I stated, BLK ports receive and process BPDUs and control plane traffic - for obvious reasons. My question was regarding unknowns/multicasts/broadcasts...etc..please take another look. thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-15-2013 11:52 AM
Hello,
I apologize - I am afraid I indeed do not understand your post correctly. You wrote:
what does the switch with the BLK port do with the received traffic? It should totally ignore it and kill it, no?? And anyway, I thought that because it is a BLK port, it should be denying/filtering/blocking all traffic but STP BPDUs and multicast control plane traffic in the first place....
If you are writing: "A BLK port should be denying/filtering/blocking all traffic except STP BPDUs and multicast control plane traffic" than basically, we're on the same terms. What is your question, then?
Best regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-14-2013 05:08 PM
Peter,
Awesome. Again, thanks. As far as adjusting the timers, we have hundreds of SVI's in our production environment, and since you can't adjust ARP globally, it seems the best bet would be to increase the MAC aging time to a value equal to or slightly greater than the 4 hour ARP timeout? (the doc you mentioned recommends this)?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-14-2013 11:44 PM
Hi James,
Modifying the MAC aging time would surely be a workable approach as well. Honestly, I do not know which approach is better in terms of system resources consumption. Lowering the ARP timeout would lead to increased ARP traffic and slightly increased CPU load, as the ARP is processed in IOS and CPU. Increasing the MAC aging time could lead to stale MAC addresses of disconnected stations to lurk in your CAM tables for extended periods of time. I guess this depends on how loaded your CPUs and CAM truly are.
In fact, you should be able to modify the ARP timeout on multiple SVIs simultaneously - simply by using interface range vlan lower upper where the lower argument is the number of your first SVI you want to modify, and the upper is the last number of the SVI you want to modify. SVIs both for lower and upper must exist, however, SVIs between these ranges do not need to - and they won't be created if they do not already exist. So this command really applies to the existing SVIs.
Best regards,
Peter
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide