- Cisco Community
- Technology and Support
- Networking
- Switching
- Yes, this showed slightly
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Uploading Slows Download Speed (and vice versa) behind Cisco 2901 NAT
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-19-2017 02:58 AM - edited 03-08-2019 11:22 AM
Hi there,
We have recently had a new leased line installed. It comes in over fiber with an NTE which converts to a 100Mb Ethernet connection (straight into the router).
We are guaranteed 100Mb up and 100Mb down from our provider.
We are running NAT on the router to provide Internet connectivity to clients private side.
We noticed that when downloading, we can achieve full throughput as this example shows:
The same is vice-versa; when we upload (without running a parallel download) we can obtain full throughput for the upload.
However, when we run both at the same time (upload and download) we notice that throughput is limited (for both).
See an example of an upload with a parallel download taking place:
... notice the decreased throughput.
We checked the CPU on the router and it's running at about 58% with both upload/download threads running at the same time. I don't think CPU is the issue here.
Perhaps it's simply the overheads of TCP/IP?
The inside interface (connected to our switch) is running at 1Gbps / full duplex.
The outside interface (connected to the NTE) is running at 100Mbps / full duplex.
Here is some of our configuration:
NAT/Routing
ip nat inside source list 100 interface GigabitEthernet0/1 overload
ip nat inside source static tcp 192.168.0.160 51413 interface GigabitEthernet0/1 51413
ip nat inside source static 192.168.0.210 x.x.x.x
ip nat inside source static 192.168.0.250 x.x.x.x
ip route 0.0.0.0 0.0.0.0 x.x.x.x
Interface
interface GigabitEthernet0/0
ip address 192.168.0.1 255.255.255.0
ip nat inside
ip virtual-reassembly in
duplex auto
speed auto
no mop enabled
interface GigabitEthernet0/1
ip address x.x.x.x 255.255.255.248
ip nat outside
ip virtual-reassembly in
duplex auto
speed auto
We are also running CEF
ip cef
Thoughts around queueing
Perhaps running some kind of fair-queue on the interface will improve throughout but I was under the impressions that it was for slower links that have trouble like this. I am also under that impression that it uses lots of CPU.
Currently, both interfaces are running default FIFO.
Any thoughts, suggestions,
- Labels:
-
Other Switching
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-21-2017 01:23 AM
Indeed, we already have a support case open with them. I think some reconfiguration of the NTE should be possible. If we can negotiate with the NTE access port at 1000Mb/s then that would become the bottleneck, not our router or Firebox.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-21-2017 04:20 AM
From everything seen so far, there doesn't appear to be an ISP issue.
If you do move up to gig, your bottleneck will become the 2901.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-21-2017 04:08 AM
We've seen part of the problem appears to be TCP ACKs delayed in a FIFO queue as we saw a huge jump when we implemented FQ on one side.
You might further confirm that by decreasing the 2901's egress tx-ring-limit and then perhaps creating a class just for ACKs and providing it as much class bandwidth as possible and/or placing that traffic in LLQ. (NB: I would not do the latter, i.e. the ACK class, for production, but you might see how the tx-ring-limit reduction works and possible retain that.)
Understand, TCP self clocks its steady state transmission rate to its received ACK rate.
BTW, supporting VoIP traffic, I've never found any QoS settings that preserves VoIP traffic on a loaded port as well as an unloaded port. Other traffic packets are going to create interface serialization delay, even if you get your VoIP packets between every such packet. What helps with that, though, is either a higher bandwidth link and/or smaller packets. NB: you can find additional information on this issue for low bandwidth WAN links, say half meg and under, where you may need to enable packet interleave fragmentation to preserve VoIP SLA needs.
For testing purposes, you might much reduce the WAN's interface MTU.
Also BTW, I believe this is also a main reason why ATM chose a small cell size.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-21-2017 05:34 AM
Thank you for that information Joseph, it's very interesting.
Why does it seem that we are having this issue? It doesn't seem like a common issue as I couldn't find anything similar on the discussion forum here. We have a very common and basic setup - leased line --> NTE --> Router --> Internal clients. Is it only us that have noticed this behavior?
Do you think tweaking settings on the NTE could provide the desired result?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-21-2017 07:58 AM
Why does it seem that we are having this issue?
To recap, your "issue", a single up or down flow can obtain 11 MB/s, but with both an up and down flow, the best you've been able to obtain, each only gets about 10.5 MB/s, correct?
I.e. why don't we obtain the other half MB/s?
Something I forgot to mention, I noted issues with getting each flow's TCPs ACKs, in a timely manner, but I didn't mention the bandwidth those ACKs consume. It's not a lot, maybe around 2%, but its bandwidth taken from your stats on the file transfer rate.
Also with both a data flow and TCP ACKs competing for bandwidth, increases the change of drops for both. Such drops could slow a transfer rate and/or increase overall bandwidth consumption for re-transmissions. Such drops could also create more drops as TCP "bursts" during a catch up.
What you might also check, if you haven't already, what do your port stats show for transfer rates for both an up/down flow vs. up and down flows?
An interesting test would be if you could run an up or down test vs. an up and down test, but in both cases insure the TCP ACKs don't share the same media. I suspect if you did that, you would see the same transfer results. I.e. I suspect your "issue" is due to when you run an up and down test, the up's ACKs compete with the down's data and the converse.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-21-2017 09:05 AM
Thank you for your reply, Joseph.
Yes, I am aware that overheads also take up bandwidth.
These are the stats for a parallel up/down test running for 10 minutes:
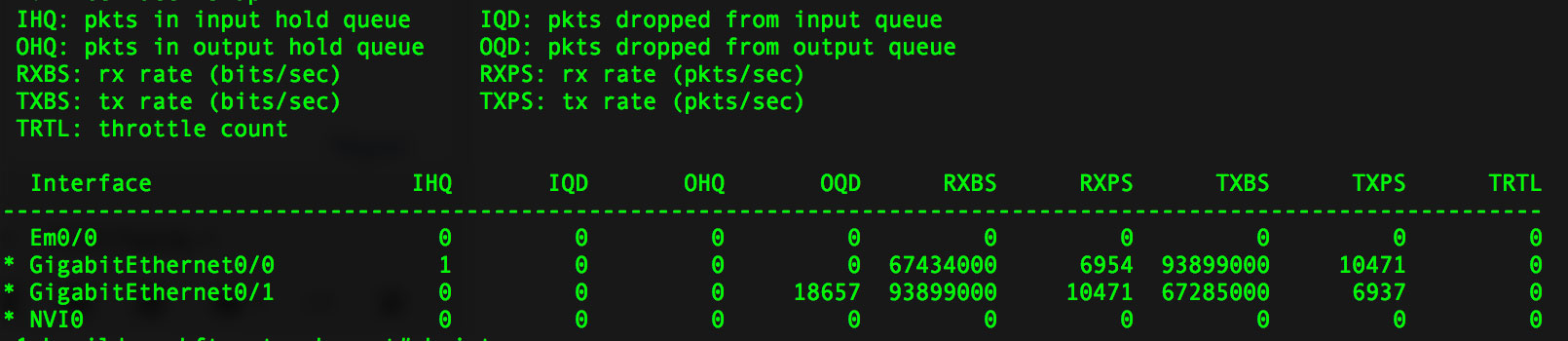
I then cleared counters and ran a single download test for 10 mins (no upload). We achieved 11.7MB/s as reported by the FTP software:
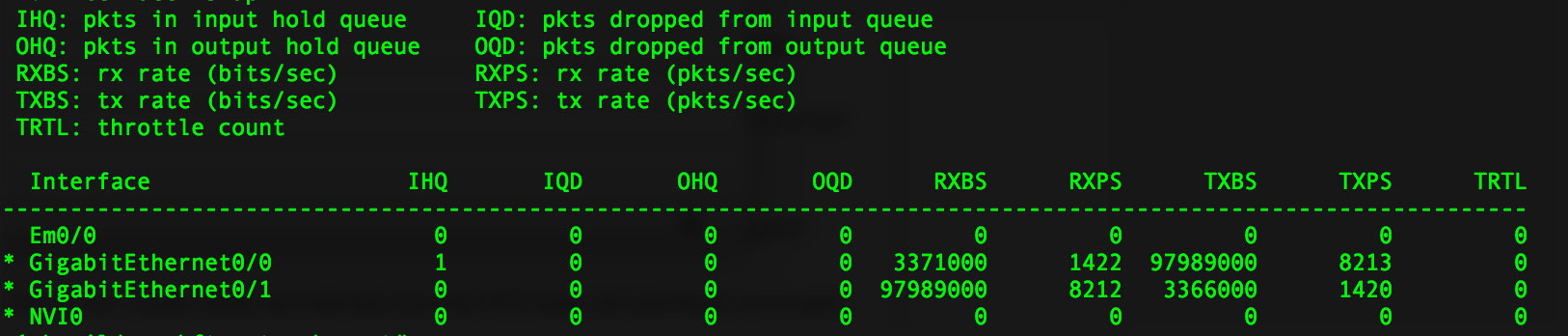
I then ran a single up test for 10 mins (with no download). We achieved only 9.3MB/s by the end of the test (but it started off
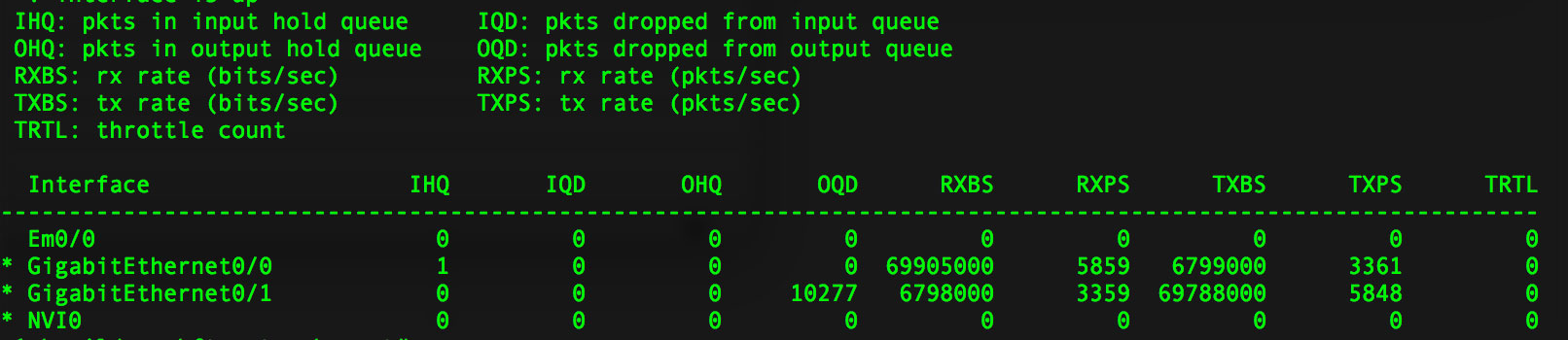
0/1 is the WAN link.
... for some reason, we just can't push data upstream that fast even with no download thread running.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-21-2017 10:44 AM
I then ran a single up test for 10 mins (with no download). We achieved only 9.3MB/s by the end of the test (but it started off about 10.2MB/s). We also noticed lots of output queue drops (counters were cleared prior):
I thought you've seen higher up rate before, after increasing the egress queue depth. I.e.:
Since applying the hold-queue, I have noticed:
When running an upload/download on separate machines, I can get ~11MB/s upload and the download stays 5-7MB/s.
What config were you using for this most recent test?
The above seems to negate:
... for some reason, we just can't push data upstream that fast even with no download thread running.
Correct?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-21-2017 11:10 AM
Yes, this showed slightly different results this time. The download started off at around 10.2MB/s and slowed down to 9.3MB/s - possibly net congestion.
The config I used (the latest is):
policy-map CBWFQ_test
class class-default
fair-queue
interface GigabitEthernet0/1
ip address xxx.xxx.xxx.xxx 255.255.255.248
ip nat outside
ip virtual-reassembly in
duplex auto
speed auto
service-policy output CBWFQ_test
hold-queue 1024 out
Yes, the above test showed poor upstream even with no download thread running. On the stats, we couldn't push 69788000 bps (66.5 Mbps) on the upstream test but the downstream thread (with no upload running) reached 97989000 bps (93.4 Mbps).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-22-2017 04:25 AM
Ok, we're likey back to your egress queues being too shallow.
CBWFQ, I believe, ignores the hold-queue setting. Its default might only be 64 packets.
As I've posted earlier, whether you can adjust CBWFQ sizes depends on the implementation. You'll need to examine your devices options looking for CBWFQ commands that allow you to adjust queue sizes. You might find a global setting and you might also find a per queue setting too.
If those commands are not available, your stuck with performance dictated by the device's QoS support features.
That aside, from your various tests, I believe you've shown what's impacting much of your test results. Which are, queue depths are too shallow for your needs and/or FIFO queuing delays, under load, delays TCP ACKs.
Also in regards to "missing" bandwidth when running up and down, some of that is due to bandwidth from TCP ACKs (your most recent posting show that as over 3 Mbps and/or likely the interaction of TCP ACKs sharing bandwidth with a heavy load flow. I.e. TCP behaves a bit differently when dealing with a fixed amount of bandwidth that a single flow overruns vs. a variable amount of available bandwidth. The latter, I believe, will cause a lower overall transfer rate, than what the available bandwidth supports.
Only by having tuned host RWINs, to avoid TCP from trying to obtain more bandwidth than what's available, would you be able to use all the link bandwidth.
If you're not already aware of the subject, you might "research" TCP BDP (bandwidth delay product).
- « Previous
- Next »
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community:
