We have been busy these past months in polishing the current version of TRex, the open source, low cost, stateful and stateless traffic generator and working on some new big features. The main new features are:
- Stateful scalable TCP support
- Wireless support used for testing WLC
- Stateless L2 emulation frameworks for control protocols
This blog will focus on the upcoming TCP support, but before that, let's glance at what's new in v2.15-v2.27
What's new in TRex v2.15-v2.27
- A services framework was added to support L2 emulation protocols, for example DHCP/IPv6ND. The framework is written in Python (3/2.7) and it has an event driven model using SimPy. Packet crafting is done using Scapy. The framework was designed to be easy to extend.
- The scale of the number of streams with per-stream statistic property was increased from 128 to 16K. JSON-RPC API was adjusted in order to support this scale change, leading to a release of a new v4.0 GUI version.
- Support for IP configuration on top of 802.1Q (VLAN)and 802.1AD (QinQ) port configuration was added.
- mlx5 driver stability issues were fixed - thanks to Mellanox DPDK team
- Stateless packet capture was added
- Improved Stateless GUI - port configuration/charts/latency/per-stream statistics support
figure 1 shows charts of latency and per stream statistic information.
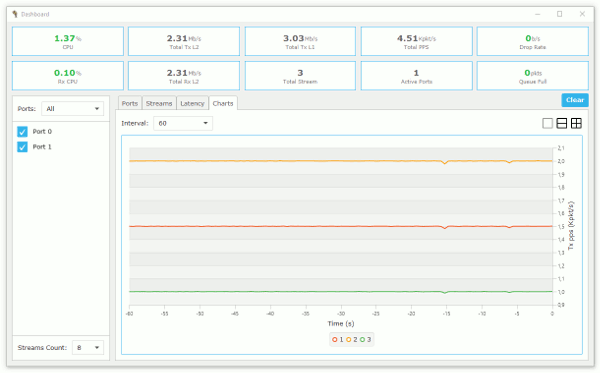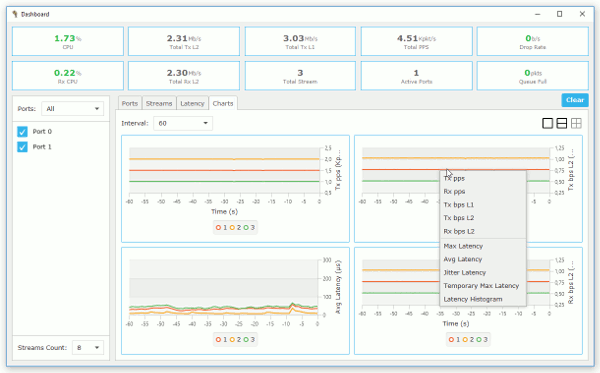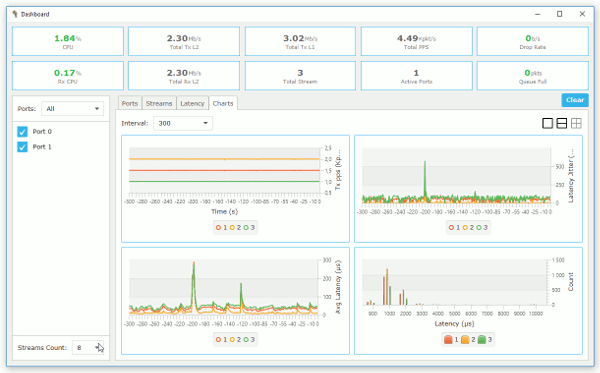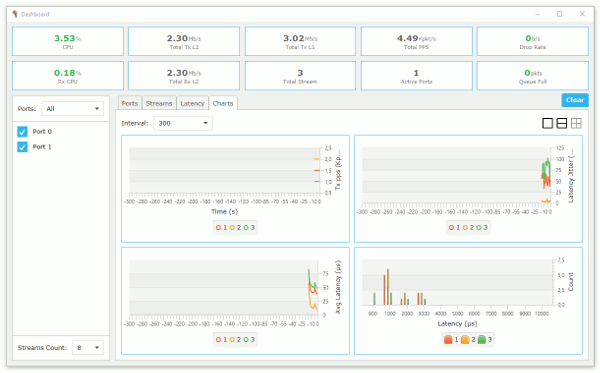
Figure 1
And now back to scalable TCP support.
Stateful scalable TCP support
The following TCP related use-cases will be addressed by the upcoming version.
- Ability to work when the DUT terminates the TCP stack (e.g. compress/uncompress, see figure 2). In this case there is a different TCP session on each side, but L7 data are *almost* the same.
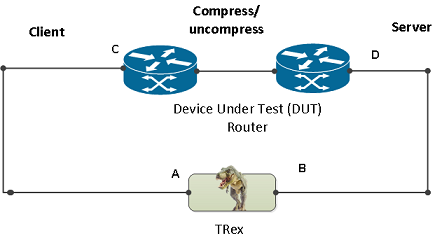
Figure 2
2. Ability to work in either client mode or server mode. This way TRex client side could be installed in one physical location on the network and TRex server in another. figure 3 shows such an example
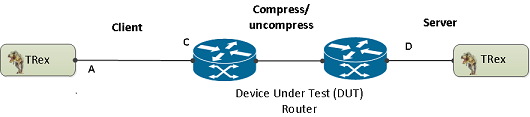
Figure 3
3. . Performance and scale
High bandwidth - 200gb/sec with many realistic flows (not one elephant flow )
High connection rate - order of MCPS
Scale to millions of active established flows
4. Simulate latency/jitter/drop in high rate
5. Emulate L7 application, e.g. HTTP/HTTPS/Citrix- there is no need to implement the exact protocol, but more about that later.
6. Simulate L7 application on top of TLS/TCP where each side runs real TLS
7. Accurate TCP implementation (at least BSD based)
8. Ability to change fields in the L7 application - for example, change HTTP User-Agent field
Can we address the above requirements using existing DPDK TCP stacks?
There are many good DPDK TCP stacks out there, the mainstream DPDK TCP stacks are:
NetBSD Based Rump Kernel - github.com/rumpkernel
FreeBSD Based
Libplebnet - github.com/opendp
Libuinet - github.com/pkelsey/libuinet
DPDK_ANS - github.com/opendp/dpdk-ans Linux
Linux Based Linux Kernel Library - github.com/lkl/linux
Non-OS
fd.io TLDK https://wiki.fd.io/view/TLDK
origin VPP TCP - git.fd.io/vpp
OpenFastPath - www.openfastpath.org (is this based on FreedBSD).
mTCP - shader.kaist.edu/mtcp
Seastar - www.seastar-project.org
Can we leverage one of the above TCP stacks for our need? The short answer is no. We chose to take a NetBSD original code base with FreeBSD patches and improve the scalability to address our needs. More on the reasons why in the following sections, but let me just say the above TCP DPDK stacks are optimized for real client/server application/API while in most of our traffic generation use cases, *most* of the traffic is known ahead of time allowing us to do much better.
let's take a look into what are the main properties of TRex TCP module and understand what were the main challenges we tried to solve.
The main properties of scalable TCP for traffic generation
- Interact with DPDK API for batching of packets
- Multi-instance - lock free. Each thread will get its own TCP context with local counters/configuration, flow-table etc
- Async, Event driven - No OS API/threads needed
- Start write buffer
- Continue write
- End Write
- Read buffer /timeout
- OnConnect/OnReset/OnClose
- Accurate with respect to TCP RFCs - at least derive from BSD to be compatible - no need to reinvent the wheel
- Enhanced tcp statistics - as a traffic generator we need to gather as many statistics as we can, for example per template tcp statistics.
- Ability to save descriptors for better simulation of latency/jitter/drop
Figure 4 shows the block diagram of new TRex TCP design
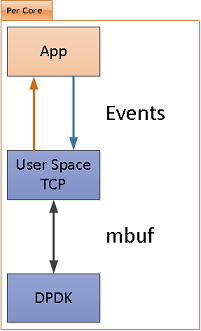
Figure 4
And now lets proceed to our challenges…
Let me just repeat the objective of TRex, it is not to reach a high rate with one flow, it is to simulate a realistic network with many clients using small flows. Let's try to see if we can solve the scale of million of flows.
Tx Scale to millions of flows
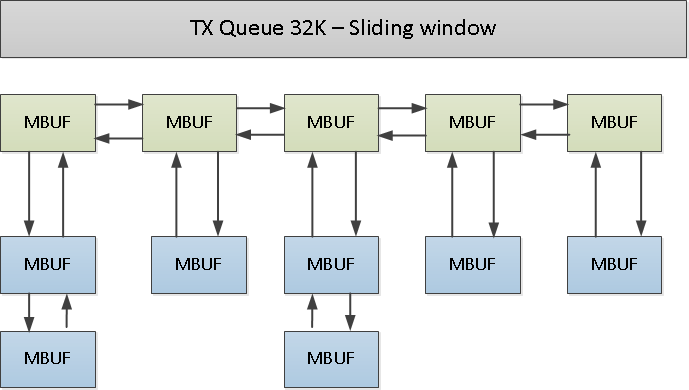
Figure 5
Most TCP stacks have an API that allow the user to provide his buffer for write (push) and the TCP module will save them until the packets are acknowledged by the remote side. Figure 5 shows how one TX queue of one TCP flow looks like on the Tx side. This could create a scale issue in worst case. Let's assume we need 1M active flows with 64K TX buffer (with reasonable buffer, let's say RTT is small). The worst case buffer in this case could be
1M x 64K * mbuf-factor (let's assume 2) = 128GB. The mbuf resource is expensive and needs to be allocated ahead of time.
the solution we chose for this problem (which from a traffic generator's point of view) is to change the API to be a poll API, meaning TCP will request the buffers from the application layer only when packets need to be sent (lazy). Now because most of the traffic is constant in our case, we could save a lot of memory and have an unlimited scale (both of flows and tx window).
Notes: this solution won't work with TLS since constant sessions will have new data
Rx Scale to millions of flows
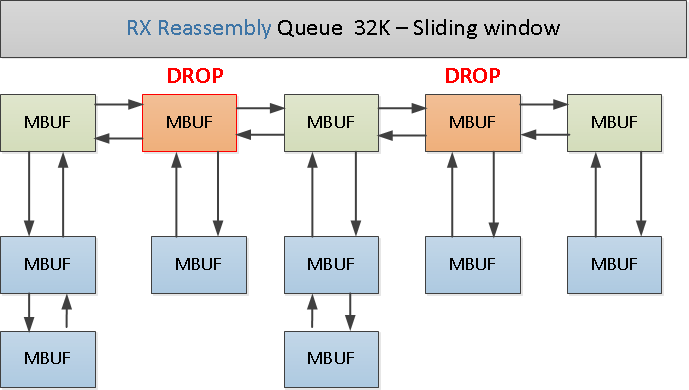
Figure 6
The same problem exists in the case of reassembly in the rx side, in worst case there is a need to store a lot of memory in reassembly queue. To fix this we can add a filter API for the application layer. Let's assume that the application layer can request only a partial portion of the data since the rest is less important, for example data in offset of 61K-64K and only in case of restransmission (simulation). In this case we can give the application layer only the filtered data that is really important to it and still allow TCP layer to work in the same way from seq/ack perspective.
Simulation of latency/jitter/drop in high scale
There is a requirement to simulate latency/jitter/drop in the network layer. Simulating drop in high rate it is not a problem, but simulating latency/jitter in high rate is a challenge because there is a need to queue a high number of packets. See figure x.
A better solution is to queue a pointer to both the TCP flow and the TCP descriptor (with TSO information) and only when needed (i.e. when it has already left the tx queue) build the packet again (lazy). The memory footprint in this case can be reduced dramatically.

Figure 7
Now let's discuss how we emulate L7 application (for example HTTP)
Emulation of L7 application
To emulate L7 application on top of the TCP we can define a set of simple operations. The user would be able to build an application emulation layer from Python API or by a utility that we will provide that will analyze a pcap file and convert it to TCP operations. Another thing that we can learn from pcap is the TCP parameters like MSS/Window size/Nagel/TCP options etc
Let's give a simple example of a L7 emulation of HTTP Client and HTTP Server
HTTP Client
send(request,len=100)
wait_for_response(len<=1000)
close()
HTTP Server
wait_for_request(len<=100)
send_ response(data,len=1000)
wait_for_close()
close();
This way both Client and Server don't need to know the protocol, they just need to have the same story/program. In real HTTP server, the server parses the HTTP requeset, learns the Content-Length field, waits for the rest of the data and finally retrieves the information from disk. With our L7 emulation there is no need. Even in cases where the data length is changed (for example NAT/LB that changes the data length) we can give some flexibility within the program on the value range of the length
Please register to our TRex sessions (learning and Python API) that will be presented in the devnet zone Cisco Live Las Vegas 2017 in order to learn more on our latest enhancements and advanced capabilities.

see here https://trex-tgn.cisco.com/trex/doc/
Resources
[1] SimPy https://simpy.readthedocs.io/en/latest/
[2] TRex services https://trex-tgn.cisco.com/trex/doc/trex_stateless.html#_services
[3] TRex Stateless GUI https://github.com/cisco-system-traffic-generator/trex-stateless-gui
[4] TLDK https://wiki.fd.io/view/TLDK
[5] VPP https://wiki.fd.io/view/VPP
thanks,
Hanoch
