- Cisco Community
- Technology and Support
- Networking
- Networking Knowledge Base
- Hitchhiker's Guide to Troubleshooting IPv6
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
05-29-2014 06:37 AM - edited 03-01-2019 05:03 PM
This article appears in the June 2014 Cisco TS Newsletter. Subscribe now to have Tech Insights, Services Updates, and TAC-inspired Technical Documents delivered to your inbox each month!
"But look, you found the notice didn't you?"
"Yes," said Arthur, "yes I did. It was on display
in the bottom of a locked filing cabinet
stuck in a disused lavatory with a sign
on the door saying 'Beware of the Leopard'."
Unlike the building plans in the great novel written by Douglas Adams, the building plans for current version of the IP protocol - IPv6 are there in the open – described in numerous Internet Standards track RFCs. However, the volume of information is daunting, and it may be hard to prioritize it. This article is by no means a replacement for a training course in IPv6, but rather an author’s answer to a question: “What makes troubleshooting dualstack and IPv6-only networks different from the legacy IPv4-only networks, and what are the tricky areas to watch out for?”
Probably every network has some public facing services – at least a Web server. These are the services that need the IPv6 first. The number of IPv6-enabled users is increasing every day, and you want to allow them to use native IPv6 connectivity, instead of relying on increasingly complicated IPv4 life support options.
The cleanest approach to enabling IPv6 is to dual-stack the servers – assign both an IPv4 and IPv6 addresses to them. As both address families are running in parallel, assuming it is the hosting provider providing you with IPv6 connectivity, you need to take care of only the secure connectivity from the server. Frequently ACLs (access control lists) are used to provide an easy means of firewalling the services. As you configure the ACL for IPv6, keep in mind that besides the application traffic, you might also need to permit at least some of the ICMPv6 messages, primarily those used for Path MTU Discovery and Neighbor Discovery. Let’s take a closer look at each of them.
Neighbor Discovery
Neighbor Discovery (ND, or NDP), besides other tasks, takes the role of ARP in doing address resolution, with the general approach being the same – request-response exchange, except the exchange of Neighbor Solicitation (NS – the request to resolve the address) and Neighbor Advertisement (NA – the reply to the address resolution) happens using ICMPv6, which runs on top of IPv6 itself – contrary to ARP using a separate ethertype 0x806. This implies that the NS and NA need to be permitted by the ACLs, and the IPv6 access-lists have an implicit permit entry in the very end before the implicit deny. While well intentioned, practically this has shown to cause issues, so it may save some hassle to add the lines to permit NS and NA explicitly, in the beginning of the ACL.
Another trait of ND is that a single NS-NA exchange allows both sides to learn the IP-MAC mappings for each other – the requestor that sends the NS includes its own MAC address as an option, thus avoiding an extra exchange. Given that the destination of the NS is the solicited-node multicast address, this may complicate troubleshooting if the multicast traffic works only in one direction.
Another behavior of ND that is different from IPv4 and is very relevant from troubleshooting standpoint is the Neighbor Unreachability Detection (NUD) mechanism. This is a mechanism to keep each neighbor entry “fresh” and able to detect when the corresponding host disappears from the link. This mechanism is illustrated in the drawing below:
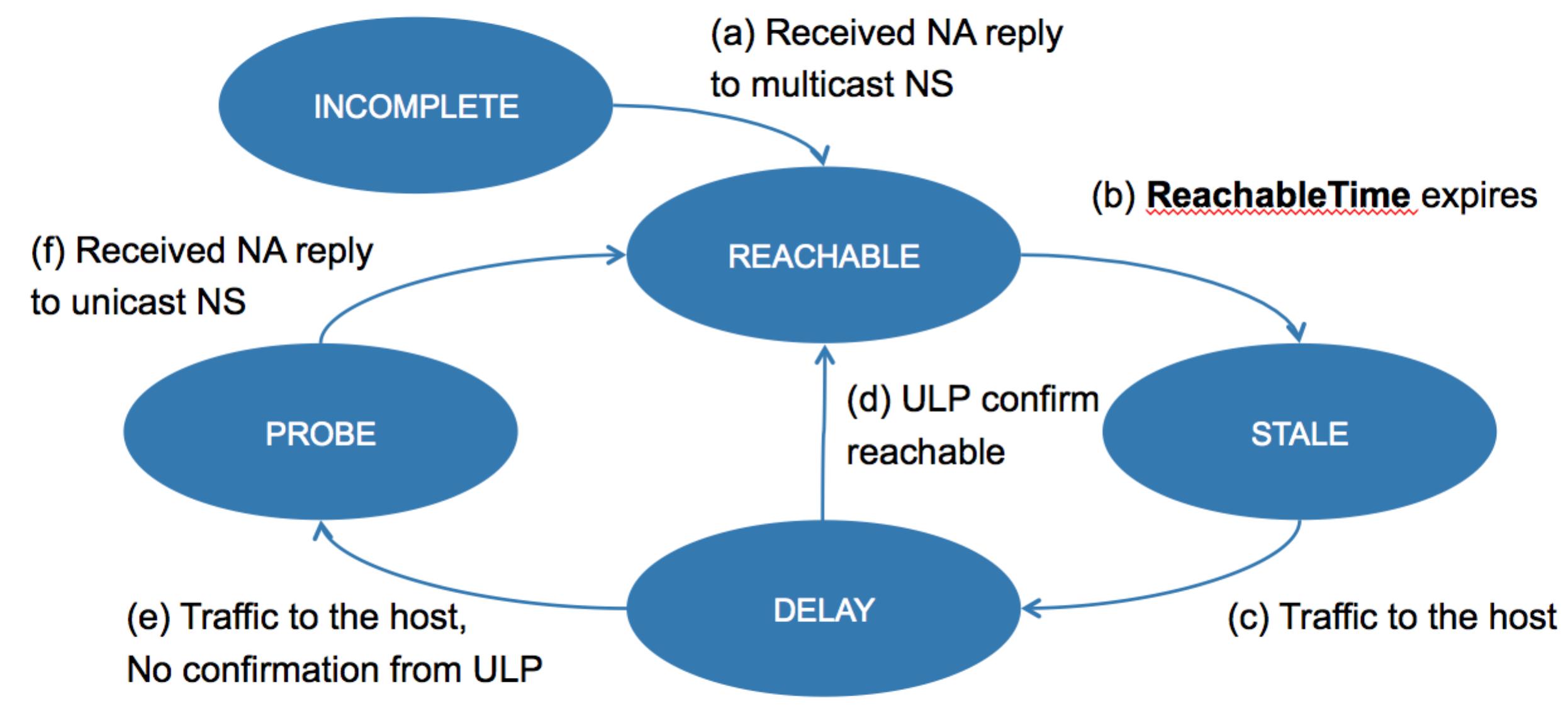
Upon resolving the address (a), the newly created entry is put into REACHABLE state, which means that we do have a confirmation of bidirectional reachability to that host (because we got the reply to our request). Upon expiry of the ReachableTime timer, the entry transitions into STALE state (b), – which means that we do not know for sure whether this host is reachable or not. However, any further verification is postponed until there is traffic to that host. This is why most of the entries in the neighbor cache would typically be in “STALE” state, and only some of them in REACHABLE.
When there is traffic destined to the host, first the entry transitions into a short-lived DELAY state (c), with the aim to try to get the confirmation of bidirectional reachability without explicit probing – and if there is such a confirmation, then the entry transitions back into REACHABLE state.
A perfect example of such a scenario might be a router having an eBGP session with the peer – the data sent on the TCP session will trigger the DELAY state, but then the received acknowledgements will allow transitioning from DELAY into REACHABLE state directly, with no extra packets. This behavior in conjunction with incorrectly configured ACL can make up for a pretty surprising “We did not change anything and it is not working anymore!” scenario upon session restart on one of the sides.
What happens if the device does not have an upper level protocol relation with the target? For a router, that’s most often the case – it just forwards the packets back and forth, and there is no protocol running to confirm the host’s bidirectional reachability. In this case there is no other choice but to try to explicitly verify the bidirectional reachability by sending a unicast NS for the target IP to the MAC address corresponding to the entry (e) and setting the entry into PROBE state – if the host is still there, it will reply with NA, and because that verifies the bidirectional connectivity, the entry will transition back to REACHABLE (f).
NDP Reachable Interval
From the above description, it is easy to see that in any active network, the router will receive a steady stream of NS messages as part of NUD. How often are the NS messages sent? This is obviously based on the initial value of ReachableTime. The router itself controls this to some extent, because this value is taken from the value BASE_REACHABLE_TIME sent in the RA messages:
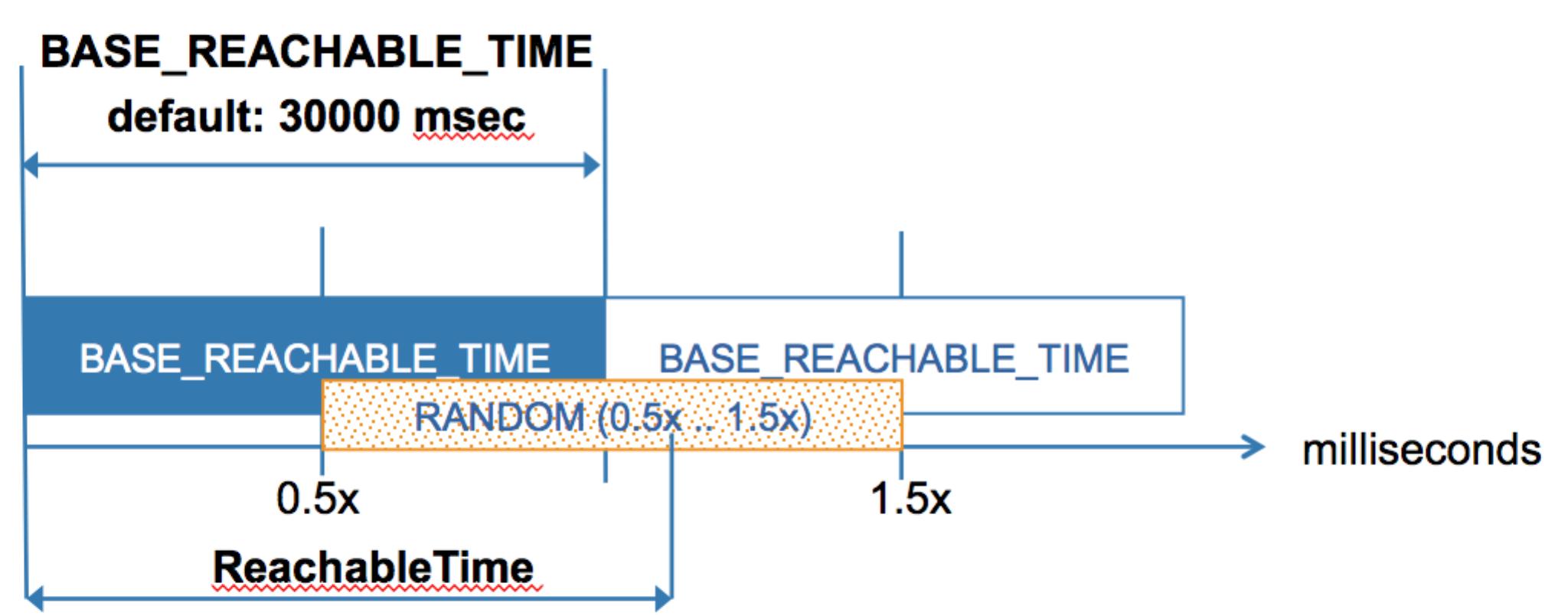
To configure the default value, use the following configuration command:
“ipv6 nd reachable-time 30000”.
Note, that this value, unlike a lot of other timers in IPv6 interface configuration, is in milliseconds. With the default values, each host with active traffic will send a NS to the router between every 15 and 45 seconds. If you are using large numbers of hosts on a single link (The IPv6 addressing of /64 per link readily allows you to do that), this may cause quite a lot of unnecessary traffic. If you only have a single router on the segment or are using a redundancy protocol like HSRPv3, you can decrease the amount of this traffic by increasing the value of the BASE_REACHABLE_TIME.
Are there consequences of doing so? Yes. First of all the neighbor table will grow larger – so you might need to experiment with a forced refresh/expiry of the entries in the neighbor table by using the command ipv6 nd cache expire <N> refresh, where a reasonable value for N might be 14400, which matches the default ARP cache timeout, and find the acceptable value for the network you have and your hardware platform.
Router Advertisements and Addressing
I mentioned the RA messages earlier without properly introducing them, so let me do it now. In IPv6, ND functions are not limited by those of address resolution – also router discovery and node configuration are important functions as well. Where in IPv4 you explicitly configure the router address on the host either manually or by using DHCP, in IPv6 each router sends a periodic message called Router Advertisement (RA) - which announces its presence on the link and allows the host to automatically configure the router.
Besides the mere presence of the router, the RA typically announces the prefixes served by the router on this segment. This information allows the hosts to automatically configure the addresses – they combine the prefix information obtained from the RA with the locally-generated interface identifier, and as a result, they get a globally routable address. This forms a basis of a pretty robust address configuration mechanism that is unique to IPv6 and is called SLAAC (StateLess Address AutoConfiguration).
Needless to say, giving the hosts such a control means they can create more than one address at once. In fact, the standard does not limit in any way the number of addresses that the hosts can create, leaving it to the particular implementation.
Can we keep using the DHCP protocol for the address assignment? Sure, the flags “Managed Address Configuration” and “Other Configuration”, when set, suggest that the host should use the stateful configuration protocol, namely DHCPv6.
However, just setting the Managed flag will not turn off the SLAAC. In order to perform DHCPv6-only address assignment, one must clear the “Autoconfiguration” flag on the prefixes advertised by the router.
Keep in mind though, that not all the devices currently support DHCPv6 – thus, a DHCPv6-only address assignment might leave some of the operating systems without IPv6.
Path MTU Discovery
The Path MTU Discovery (PMTUD) in IPv6 functions in a fashion similar to IPv4 – if a router cannot fit the packet, it sends back a Packet Too Big ICMP message, which triggers the sender to resend the message in a smaller part. However, here again there are a few details worth noting.
- First, there is no way to bypass the PMTUD – there is nothing similar to IPv4’s “Do not fragment” bit that can be cleared to perform the fragmentation on the intermediate nodes. This means that the “Packet Too Big” absolutely must make it through, or the connection might be black-holed.
- Second, IPv6 dramatically increases the minimum MTU on the link, let’s see what RFC2460 (http://tools.ietf.org/html/rfc2460) has to say about this: “IPv6 requires that every link in the internet have an MTU of 1280 octets or greater. On any link that cannot convey a 1280-octet packet in one piece, link-specific fragmentation and reassembly must be provided at a layer below IPv6.”
This is something that is almost never an issue in IPv4: in IPv4, the minimum MTU is 68.
Is there anything more to this? Yes, there is another wrinkle that you might encounter as you are troubleshooting various scenarios, especially involving address family translation: if a node sends a 1280-byte packet, and still receives back the ICMPv6 Packet Too Big with a smaller value, it will recreate the contents of this packet, but will add a Fragmentation Header – therefore, making the overall structure closer to the IPv4, (which had the packet identification, fragment offset and “More fragments” flag). The motivation for this is to allow the intermediate nodes to fragment the packets at the IP layer that they cannot otherwise fragment at link layer.
Why is this important? A fragmentation header is inserted between the IPv6 header and the upper layer protocol headers. Some of the networks might filter the fragments, for the reasons mentioned in http://tools.ietf.org/html/draft-taylor-v6ops-fragdrop-02 - so you should keep it in mind when troubleshooting, that such packets might be lost on the way.
This short article touches just a few aspects of IPv6 I deemed important to fit into the space I had available. Want to add something? Want to share some of your IPv6 troubleshooting experiences or questions? Add a comment, follow me on Twitter @ayourtch, or drop me an email at ayourtch@cisco.com.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Absolutely fantastic, as always, Andrew!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Great article. It expanded my understanding of the neighbor cache.
But your diagram of the finite state machine seems incomplete. How does an entry get purged? Does it ever move back to INCOMPLETE and then get purged? Clearly we don't want the cache to fill until the machine is rebooted?
Thanks for the article.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Dan,
excellent observation, indeed I did not include the transitions for deleting the entry, mostly to keep it simple (although I did mention it in passing when mentioning "ipv6 nd cache expire <N> refresh") . There's an excellent (short and well-written) RFC - https://tools.ietf.org/html/rfc7048 - which discusses both the way the currently implemented standard handles the deletion of the entry, as well as the proposed improvements to the standard, to increase the robustness in large-scale networks. Enjoy!
--a
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Andrew,
I am working toward passing the CCNA exam and I have some questions about the benefits of using Ipv6 from a website owner's perspective aside from enabling users to connect with newer technology.
What are the specific engineering or technical advantages to using systems that support IPv6 over IPv4? For instance, are layer 3 switches and NAT/PAT translations still required on a pure IPv6 network?
I still don't quite understand how routers make forwarding decisions based on IPv6 source and destination addresses. If I understand correctly, routers do not forward packets received on link-local addresses as these addresses are primarily used as the next-hop address for routing. Does this mean routers distinguish between control and data traffic by the ipv6 source address and can figure out whether or not to perform a lookup (ie. matching the destination IP to a route on the routing table) of where to send the packet by the ipv6 source address? Is this process exactly the same as in Ipv4?
Thanks,
Albert
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: