- Cisco Community
- Technology and Support
- Service Providers
- Service Providers Knowledge Base
- ASR9000/XR: Migrating from IOS to IOS-XR a starting guide
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 02-21-2012 06:29 AM
Introduction
This document tries to assist in an easy and smooth migration from IOS to IOS-XR. Because of the fundamental different nature of the IOS XR operating system and the way things have been implemented specifically by the ASR9000 platform, this article tries to collect a couple of key items to think about and providing some pointers that prevent issues down the road and prepare for proper planning to the great ASR9000.
In this article various topics are separated out per main topic.
- Operating System
- Monolithic for MicroKernel
Understanding the IOS-XR prompt and privilege levels/taskgroups
Memory architecture
- NETIO and "slow switching"
- Using show commands and the location keyword
- RIB, FIB and adjacencies
- Committing configurations and rollback points
- Commit options
- Rollback options
- OSPF
Processes and Using OSPF as a PE-CE protocol
- BGP
- Capability advertisement
- Using neighbor, peer and session groups
- RPL
- RPL and changes to the policy
- InterAS
- L2VPN
- Matching configuration from 7600 to ASR9K for L2 Services:
- Spanning Tree
- SVI and BVI
- EFP
- Converting IOS trunks into XR
- SNMP
This is a "living document", we'll add more and more items as we see questions coming in that have not been covered before, so watch the revision of the document to see if new items have been added. I realize that this document is not complete, but more to be added as we go.
Operating System
Monolithic vs Microkernel
One of the key differences between IOS and IOS-XR is the base operating system. Legacy IOS is known to be a "monolithic" operating system. Effectively it is a run to completion whereby some timesharing is done between processes. This model has proven to be working out very well for over 25 years given the success of Cisco IOS based routers and switches. Also IOS uses a complete shared memory space.
Of course there are also drawbacks which IOS-XR focusses on to address.
One of these enhancements is that XR is running on a microkernel (qnx based) and on top of that we are running the IOS XR processes.
These processes are running similar to a process on a linux based operating system. Effectively the QNX gives us a K-Shell from which we can do similar things as a unix based OS.
When seeing the IOS-XR prompt, if you type "run" it will give you access to the K-Shell. Although it is not supported officially, sometimes it is handy and useful to access the kshell to get hardware level counters or access the file system to copy things around etc.
The flexibility that IOS-XR gives with these processes are:
- ability to restart a process
- ability to patch a process (Via a SMU, the software maintenance update)
- complete control plane and data plane separation (if eg OSPF crashes it doesn't affect the forwarding)
- control plane distribution (some functionality can be offloaded to the linecards like netflow or BFD for scale increase)
Understanding the IOS-XR prompt and privilege levels/taskgroups
IOS has a very simple prompt with a host name followed by a sign that identifies the "mode" that you are in, whether that is privileged exec or regular exec etc.
For instance:
CPE#
or
CPE>
IOS-XR prompt looks like this:
RP/0/RSP0/CPU0:A9K-BNG#
The way to interpret it is as follows:
RP : We are looking at a route processor
0 : Currently we are attached to shelf 0. In the case of multichassis (CRS) or Clustering (ASR9000) we can link multiple chassis together functioning as a single entity, this number identifies which shelf from that same logical node we are looking at.
RSP0: Which RSP we are connecting to. In the case of dual RSP the lower slot ID is RSP0 and the higher slotID is RSP1. Generally you always logon to the active RSP via telnet which can then either be RSP1 or RSP0.
CPU0: today we only have a single (multicore) CPU on the RSP and linecards. This would identify the CPU we are working with in the case that we are adding CPU's on the system.
:hostname : this is the well known part, the hostname.
Note that the suffix of the complete prompt is always with a hash '#' sign. Which suggests that you are in privilige 15 mode.
IOS-XR does NOT have the concept of privilege levels but instead uses task group authorization.
To learn more about using task groups in IOS-XR check you can see in this picture.
Some key differences and highlights between 7600/IOS and ASR9000/XR
Matching configuration from 7600 to ASR9K for L2 Services

A very comprehensive overview of the EVC model is found on this link.
Spanning Tree
The ASR9000 only supports full MSTP and no other spanning tree protocol.
There is the possibility to use the PVST in PVST-AG mode or Access Gateway.
The "AG" version of the MST or PVST gives you the ability to run these protocols in an P2MP VPLS deployment without the need to run the full protocol set. It basically is designed around the 9K PE's being the root, advertising pre-canned BPDU's and receive the TCN's from the access switches to trigger MAC withdrawl.
More info on VPLS and ASR9000 is here.
Running Spanning Tree (not the AGG) version together with IOS requires you to be aware of the concept of VLAN pruning that IOS does and XR is not aware of.
Migrating spanning tree from 7600 to ASR9000 can be a complex task. IOS switches run STP by default, and you need to disable it explicitly if you don't want to run it. ASR9000 does not run any spanning tree protocol by default and you need to enable it explicitly.
Also the way that BPDU's are handled in XR/ASR9000 is dependant on your configuration.
The following scenarios cover a few of these design migrations you need to be aware of.
This section tries to cover both MSTP and PVST. The key difference for these 2 protocols is that MSTP sends BPDU's untagged and PVST sends tagged BPDU's on the vlans that are PVST enabled.
One of the first decisions you need to make is whether you want the A9K's to be part of the Spanning Tree design or be transparent to them.
There are pros and cons to each option.
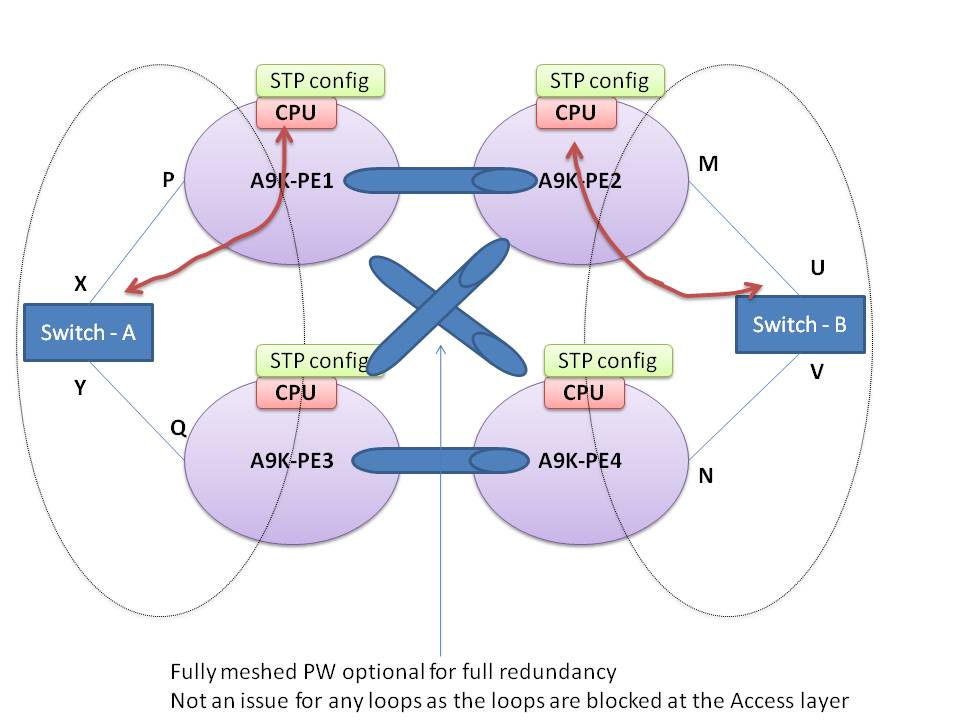
In this first picture below shows a design whereby the ASR9000's are NOT part of the spanning tree topology.
If you have defined an untagged EFP like this:
int Gig0/0/0/P.1 l2trans
encap untagged
you will capture the MSTP BPDU's and put them subject to the service that is attached to this untagged EFP.
This can either be a Cross connect (p2p) or a Bridge domain (p2mp). The difference between XCON and BD is that XCON transparently takes whatever comes in on the Attachment Circuit (AC) and send it to the other side (whether that is a phyiscal interface again or a PseudoWire). An Xcon can only have 2 interfaces.
A bridge domain can have multiple EFP's and also employs mac-learning. If the Destination MAC is not know or part of a broadcast/multicast mac address it will get "Flooded" over to all EFP's in the Bridge Domain, except for the originating EFP (split horizon).
Ok so in this design, with that knowledge from above, the BPDU's from switch X are sent via interfaces X and Y to PE1 and PE2.
PE1 would take the BPDU from the untagged EFPand sends them transparently to PE2 over interface M to Switch B's interface U.
In other words Switch A and B see each other as directly connected neighbors. The A9k's are completely transparent and acting as a transparent L2 wire.
This STP design will block one of the 4 (X, Y, U or V) interfaces to break the loop.
Design 1

If you were to have a bridge domain on PE1 and a pseudowire between PE1 and PE4, the BPDU *also* gets sent to PE4 and arriving on interface V.
This model whereby the 9k's are transparent to STP cannot be used with a full mesh of PseudoWires.
This design that you see above is generally seen by "accident" when it is forgotten that the switches run STP by default and the 9k would transparently pass everything on.
"Solutions" are to break to loop manually and using an L2ACL to block the MSTP BPDU's from traversing your 9K's.
In the scenario that you do want the 9k's to participate in spanning tree you basically create to STP "islands" on the left and right side.
The 9k's now terminate the spanning tree coming from the switches. A full PW mesh is possible and this is also one of the designs where the AG version of the STP protocol becomes very useful.
Switch A sees PE1 and PE2 as neighbor.
Design it such that the PE1 and PE2 are root and back up root.
The configuration for this design is to put the interface P into the STP Configuration so that BPDU's are sent and received.
Design 2
The effects of the design scenarios and the relation to the spanning-tree protocol in use are pretty much the same for both MSTP and PVST.
What happens when you follow design 1 or 2 in relation to the EFP configuration associated with it, will be discussed below separated out between the two key STP's.
More detailed configurations and VPLS designs are discussed in this article.
Let us evaluate the various configuration options that you have when defining your EFP's with and without Spanning tree.
MSTP
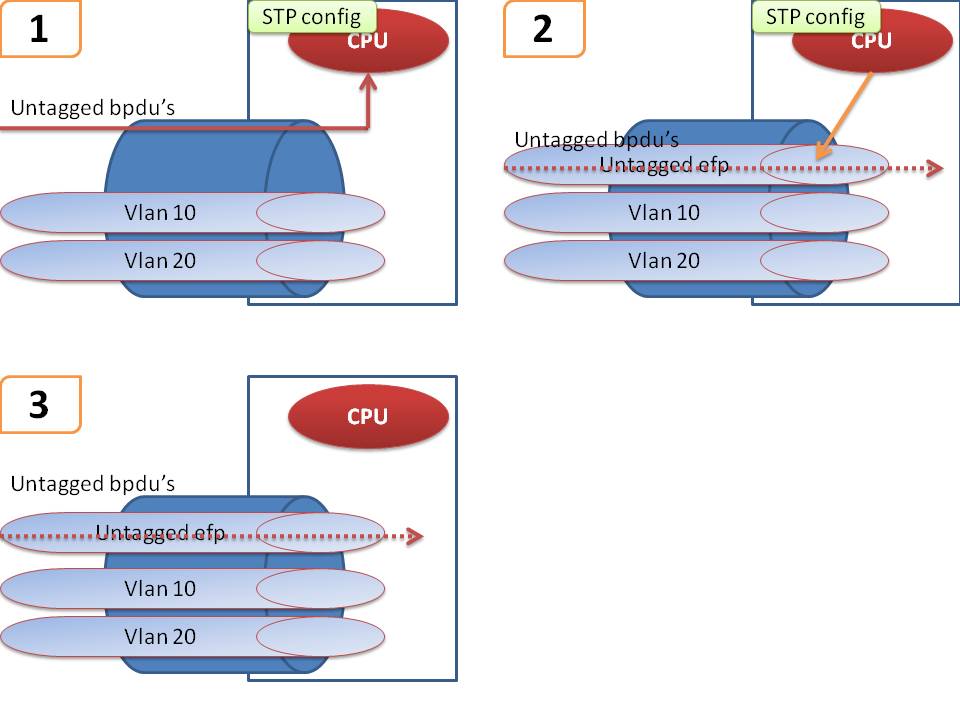
Scenario 1 in this picture above is the model that you want to use in the design option "2". There is no untagged EFP necessary in this case, and BPDU's received are punted and locally generated BPDU's are injected directly into the port to the switch.
Scenario 2 describes a situation whereby sometimes people want to peel out their untagged traffic and transport it while still running MSTP on the 9k as in design "2". This is problematic today for a few reasons:
1) received BPDU's are subject to the untagged EFP service defintion and will get forwarded. The local MSTP configuration injects BPDU's.
2) this causes the locally connected switch to see BPDU's from the VPLS remote side (switch B) as well as PE1.
3) it will cause MSTi mismatches and unexpected blocked ports.
Scenario 3 can be used for "design option 1". We don't have any local configuration for STP, so we're not injecting anything, we are sending the BPDU's across as per the EFP service definition.
Note:
Scenario 2 is however a design that is recognized as a design we need to support. Starting XR421 scenario 2 will work as follows:
If there is an untagged EFP *and* local STP config on the PE, THEN we will NOT forward the BPDU, but punt them for local STP handling.
We will continue to inject local BPDU's towards the locally connected switch.
In other words if you have untagged traffic that you want to transport but not the BPDU's this will work in XR421. Today, you will get the behavior as described above in scenario 2.
If your intend is to use design option 1, and you want to forward untagged traffic (config scenario 3), but you don't want to forward the BPDU's then you must apply an L2 ACL onto the untagged EFP to block and deny the DMAC used for (MSTP) BPDU's.
The ACL definition is discussed in this article in the related information section.
PVST
The story above doesn't change that much when we are considering PVST.
However there are some minor tweaks caused by the fact that PVST BPDU's are vlan tagged.
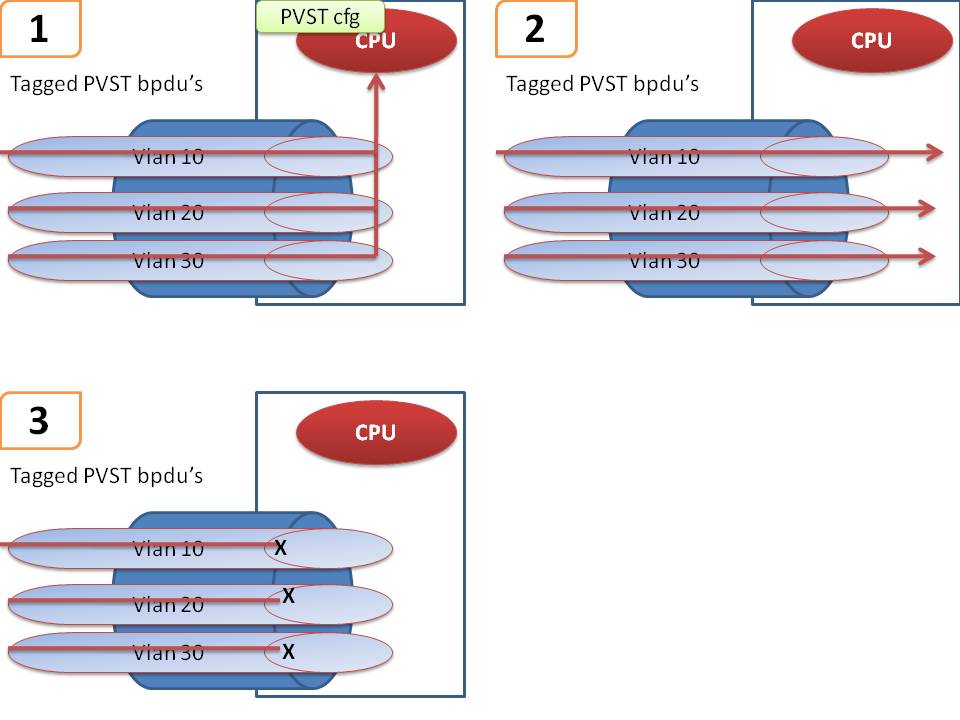
Scenario 1 is used in design option "2" whereby you want your A9K's to participate in PVST. Note that we don't do full PVST, but PVST-AG or access gateway, which means that we are sending the bpdu's on the EFP's for the respective vlans and take the BPDU's from these vlans and react on them with mac widthdrawl. The configuration scenario looks like this:
!EFP's
interface g0/0/0/P.10 l2trans
encap dot1q 10
...etc
!service definitions
l2vpn
bridge group VLANS
bridge-domain vlan-10
interface g0/0/0/P.10
bridge-domain vlan-20
interface g0/0/0/P.20
...etc
!spanning-tree config
spanning-tree pvst-ag
interface g0/0/0/P.10
interface g0/0/0/P.20
interface g0/0/0/P.30
HOT HOT HOT HOT
Scenario 2 is a common issue we see happening causing a lot of trouble. This config scenario does NOT have any local PVST configuration, but if the adjacent switches have PVST enabled (and that can be the default!!) then we'd be transparently passing on the vlans as part of the EFP's service definition! The PVST BPDU's are arriving at the remote side and what can be worse is that if we are doing vlan manipulation in terms of tag rewriting with pop or push operations, then the remote side received BPDU's meant to describe vlan 10, but received as VLAN X after the rewrite!
This scenario can be the intended design as described in design option "1" above.
Scenario 3 is a remedy for scenario 2. Basically we are using an L2ACL blocking any bpdu's on the EFP's received so that we are not confusing switches on either end. Alternatively you can also disable STP on the switches connected to the 9k PE's. We are applying L2 ACL's that are blocking a particular DMAC that is used for the PVST bpdu's (see
This issue described here above is something you MUST be aware of.
The ACL definition is discussed in this article in the related information section.
SVI and BVI
The concept between a Switch Virtual Interface and a Bridge Virtual Interface is the same: and L3 endpoint in an L2 environment.
The SVI is a switch concept and the BVI is an L3 concept generally seen on routers.
The BVI interface in IOS-XR/ASR9000 has some restrictions well documented in the CCO documentation for BVI.
Use this reference to setup IRB (Integrated Route Bridging) using the BVI.
EFP
When you set up your Ethernet Flow Point (EFP), especially the untagged one, it can make you run into unexpected scenarios.
For instance, when you have an untagged EFP and you are running full MSTP, the 9K will be able to inject BPDU's to the peer, but the peer's BPDU's are subject to the service of the untagged EFP and may get forwarded. This results in MSTP conflicts on your peer device.
With XR 4.2.1 we'll have the auto ability to peel out the BPDU's from the untagged EFP when MSTP configuration is present.
Also the forwarding of vlan traffic out of an EFP and vlans has a few things that you need to be aware of documented in this article
Converting IOS trunks into XR
Because the IOS-XR EVC model is not aware of trunks like IOS devices are, the conversion from an IOS trunk to an XR EVC based config can be a bit confusing at first. This configuration example documents how to convert an IOS trunk to an XR EVC model:
IOS:
interface TenGigabitEthernet13/3
description my-trunk
switchport
switchport trunk encapsulation dot1q
switchport trunk allowed vlan 4,130,133
switchport mode trunk
no ip address
interface Vlan 4
ip add 10.11.2.1 255.255.255.0
XR:
The translation will be:
interface TenGigabitEthernet 0/0/0/0
description my-trunk-like-xr-interface
Define the EFP's with their respective vlan tags. Because a BVI is used we need to pop the tag so that "inside" the bridge-domain we see untagged packets. On egress, the vlan tag will be slapped on as per EFP definition. Effectively, we create a bridge-domain per vlan.
interface ten0/0/0/0.4 l2transport
encapsulation dot1q 4
rewrite ingress tag pop 1 symmetric
interface ten0/0/0/0.130 l2transport
encapsulation dot1q 130
rewrite ingress tag pop 1 symmetric
int ten0/0/0/0.133 l2transport
encapsulation dot1q 133
rewrite ingress tag pop 1 symmetric
The L2transport command makes these switchports for L2 services
For the switchport trunk allowed vlans, and the interface vlan X, you need to do the following:
First create the bvi interface:
interface BVI4
ipv4 address 10.4.1.10 255.255.0.0
interface BVI130
ipv4 address 10.130.1.1 255.255.0.0
interface BVI133
ipv4 address 10.130.1.1 255.255.0.0
Note that the BVI interface number doesn't necessarily need to be the same as the VLAN identifier, same goes for the subinterface number of the l2transport interface. Though for this example, the practice is followed to make the BVI number, the same as the dot1q TAG value and the same as the EFP subinterface number for clarity.
Then you need to create the bridge group to tide all together.
l2vpn
bridge group MyTrunks
bridge-domain VLAN4
interface ten0/0/0/0.4
routed-interface bvi4
bridge-domain VLAN130
interface ten0/0/0/0.130
routed-interface bvi130
bridge-domain VLAN133
interface ten0/0/0/0.133
interface bvi133
The Bridge group is just a non functional configuration hierarchy to tie several bridge-domains together in part of the same functional group. It functionaly is no different then creating multiple individual groups with their domains, as opposed to one group with multiple domains.
SNMP
Because as you've seen throughout this document XR is heavily distributed, SNMP being a component that requests data from every feature or functioanlity potentially is very heavily relient on IPC's to get its info. Sometimes it feels that show commands or SNMP performs slower in a next generation OS like XR, but this is because of these IPC's.
Also because IOS-XR employs the concept of "SDR" or Secure Domain Routers (CRS specific), some restrictions apply to the way that SNMP operates.
Significant performance options have been put in place. For instance, when you get the stats for an interface, rather then sending an IPC for one interface, we collect a "bulk" of info for the next X interfaces also as you might do a getnext for the next if inline.
Some "standard" data like the Entity info is subject to the load of the MGBL pie that gives access to these MIBS as well as special config is needed to expose this info to the SNMP agent. See here for more detail on that.
Related Information
Xander Thuijs, CCIE #6775
Sr Tech Lead ASR9000
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi xander,
Regarding the number of ospf process, I can see a maximum of 10 ospf process can be configured in the box.
Is there a recomendation or best Practice with the maximum number of ospf process to be configured in the box?
For example if my design of a pe router with multiple routing instances in the global and vrf tables requires a total of 7 ospf process, is there a risk with the device resources consumption?
The next question is when we must stop adding vrfs under a single ospf process? Is there a kpi or resource to monitor? If we are close to exceed that kpi, an alternative could be to use another ospf process and new vrfs attach to that new process?
Thanks,
Carlos Trujillo
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Carlos: ASR9K supports 4 OSPF Processes as per testing limitations, while ospf can carry 10.
I couldn't justify a design requiring 7 processes really. you may need 2 for your CE's and one for your core.
You could monitor the OSPF process cpu and memory utilization.
OSPF supports 32 adj per interface, 1000adj per device but you can configure this to be higher with ospf max-interface
as this is just a testing limit and really depends on your routing activity dbase sizes etc.
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks for your reply,
So even if it let me configure 7 ospf process, once I enable them say for example add neighbors and start learn lsas by each process, just 4 of them start to do ospf dutyes? The rest wont establish Adjacencies and exchange lsas?
The 7 ospf process are the result of the conversion of an iOS device that will be replaced by an asr9k. Of the 7 process one is used for all the vrfs. The other 6 process are for services or domains attached to the default or global routing table + the core unicast/ multicast uplink process.
I know that it is possible to converge all the services (multiple domains) of the global table in a single process (single domain) but at the cost adding complexity like adding filters and in some cases even changing the entire area id of local and peer routers to keep the lsas away between services that with the asr9k will look as belonging to a single domain.
Maybe that could be the justification pf using 7 process in our particular scenario?
Thanks
Carlos Trujillo
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
They will run all 7 of them, but this is not an officially tested scenario by our test group, which means we can't officially support that scenario, however it will work just fine I am sure.
Yeah we have a lot of legacy situations from IOS (iOS, with lower case 'i' runs on apple's ). We see people thinking they need more then 1 or 2 ospf processes but realistically I have not seen a technical reason for that (hence the call out in this document).
regards
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Yeah spell checker in iPhone works fine ;)
Are there plans in the future for the test group to test a scenario with more than 4 process?
It yes, could you ask when?
Maybe is beyond the scope of this thread, want to know under what criteria the test was based in only 4 process? Why not more or even less?
Im asking this because we are soon to replace some pe's in a big mpls network, and because the support now is "officially" supported to 4 process, we have to make some long term global changes in our network to support that ospf process limitation. Im thinking if maybe test group is soon going to test more process and if the results succed, we could keep our existing design.
Mean our decission in how to continue depends of the answer of test group.
Thanks for your clarification,
Carlos Trujillo
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
At this point there are no plans to test more then 4 processes.
I am thinking Carlos that if your design requires more then 2 you could work with your Systems Engineer or Advanced Services rep to see what other design options there are.
If you still believe you need more then 4 procs you probably need to work with your account team to raise an "official" request to have this changed. It requires resource allocation and release targets that unfortunately we can't decide on this forum.
regards
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks xander, i think we will modify the existing design so we can use up to 4 process at maximumw which will be:
3 process for ospf v2 (ipv4)
1 process for ospf v3 (ipv6)
Achieving the maximum of 4 ospf process.
Last questions:
1. Is it possible and "officially supported" to use in the same process the vrfs and also the default global table? They will keep isolated?
2. Apart from this document it is there any other cco document where I can find the information about this ospf process maximum support for the asr9k?
Thanks,
Carlos Trujillo
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Carlos, correct indeed, although they are the same process, the vrf's and global are running in different "spaces" they will remain isolated.
Where it is documented, I don't think it is clearly called out explicitly in the documentation. Let me see if we can add that easily for the 9k ospf docs.
Also the ospfv3 for ipv6 doesn't count on the max of 4 supported v4 procs. So you have one extra
cheers
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
May I know how can I configure option-A inster-AS in ASR9k. Please guide me to configure it.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
its under the vrf config context/address family section.
vrf RED
address-family ipv4 unicast
maximum prefix 100
!
!
end
InterAS option B is a vpnv4 configuration between the ASBR's, so you just create that (labeled) path between the 2 asbr's as if these were 2 PE routers (but now in different AS's).
There is one gotcha over "classic" IOS when configuring option B, which I documented here:
https://supportforums.cisco.com/docs/DOC-22848
other than that it is "straight forward" BGP configuration that has some examples in the config guides for XR.
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
Thanks for your reply. Can't I configure Inter-AS option A in ASR 9 k? I couldn't find any documents for achieving it. Everywhere metioned about option-B and option-C. In addition to that how can I change the
change the service label-mode of the vpn packets like "per vrf or per nexthop". Please give me a reply.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
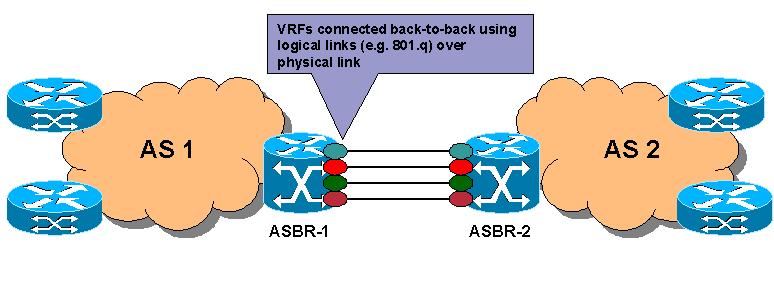
Yup of course that is not a problem. Inter-AS option A is merely a sort of "PE" configuration whereby the ASBR has vrf's towards the other-AS ASBR and there is no (MP)BGP between the aSBR's. Here is a good overview:
http://www.ciscopress.com/articles/article.asp?p=418656&seqNum=5
Few extra words from my TOI:
Each PE will treat other PE as a CE
Pros
No dependency of peering AS
Cons
Least scalable
Configuration overhead (need to configure sub-int for every customer that needed IAS service)
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
Thank you very much for your explanation I want to generate the MED in BGP for the corresponding value of hop count (metric) in RIP. Please give me a reply.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
You could use the AIGP attribute for that.
or you can use an RPL to set the MED to the IGP cost also.
RP/0/RSP0/CPU0:A9K-BNG#conf t
Fri Mar 8 14:22:15.874 EDT
RP/0/RSP0/CPU0:A9K-BNG(config)#route-policy testme
RP/0/RSP0/CPU0:A9K-BNG(config-rpl)#set med ?
igp-cost Internal routing protocol cost
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
Doesn't XR has any equivalent command of " redistribute bgp 1 transparent metric". ??
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: