- Cisco Community
- Technology and Support
- Service Providers
- Service Providers Knowledge Base
- ASR9000/XR: Understanding QOS, default marking behavior and troubleshooting
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-07-2011 01:43 PM - edited 12-18-2018 05:19 AM
Introduction
This document provides details on how QOS is implemented in the ASR9000 and how to interpret and troubleshoot qos related issues.
Core Issue
QOS is always a complex topic and with this article I'll try to describe the QOS architecture and provide some tips for troubleshooting.
Based on feedback on this document I'll keep enhancing it to document more things bsaed on that feedback.
The ASR9000 employs an end to end qos architecture throughout the whole system, what that means is that priority is propagated throughout the systems forwarding asics. This is done via backpressure between the different fowarding asics.
One very key aspect of the A9K's qos implementation is the concept of using VOQ's (virtual output queues). Each network processor, or in fact every 10G entity in the system is represented in the Fabric Interfacing ASIC (FIA) by a VOQ on each linecard.
That means in a fully loaded system with say 24 x 10G cards, each linecard having 8 NPU's and 4 FIA's, a total of 192 (24 times 8 slots) VOQ's are represented at each FIA of each linecard.
The VOQ's have 4 different priority levels: Priority 1, Priority 2, Default priority and multicast.
The different priority levels used are assigned on the packets fabric headers (internal headers) and can be set via QOS policy-maps (MQC; modular qos configuration).
When you define a policy-map and apply it to a (sub)interface, and in that policy map certain traffic is marked as priority level 1 or 2 the fabric headers will represent that also, so that this traffic is put in the higher priority queues of the forwarding asics as it traverses the FIA and fabric components.
If you dont apply any QOS configuration, all traffic is considered to be "default" in the fabric queues. In order to leverage the strength of the asr9000's asic priority levels, you will need to configure (ingress) QOS at the ports to apply the priority level desired.

In this example T0 and T1 are receiving a total of 16G of traffic destined for T0 on the egress linecard. For a 10G port that is obviously too much.
T0 will flow off some of the traffic, depending on the queue, eventually signaling it back to the ingress linecard. While T0 on the ingress linecard also has some traffic for T1 on the egress LC (green), this traffic is not affected and continues to be sent to the destination port.
Resolution
The ASR9000 has the ability of 4 levels of qos, a sample configuration and implemenation detail presented in this picture:
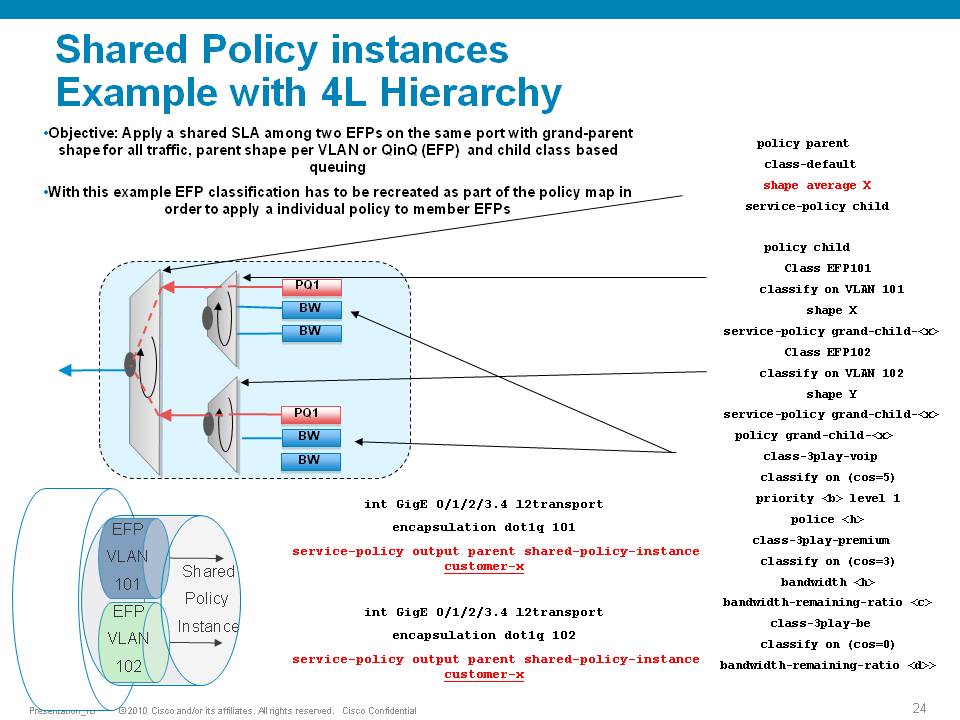
Policer having exceeddrops, not reaching configured rate
Set the Bc to CIR bps * (1 byte) / (8 bits) * 1.5 seconds
and
Be=2xBc
Default burst values are not optimal
Say you are allowing 1 pps, and then 1 second you don’t send anything, but the next second you want to send 2. in that second you’ll see an exceed, to visualize the problem.
Alternatively, Bc and Be can be configured in time units, e.g.:
policy-map OUT
class EF
police rate percent 25 burst 250 ms peak-burst 500 ms
For viewing the Bc and Be applied in hardware, run the "show qos interface interface [input|output]".
Why do I see non-zero values for Queue(conform) and Queue(exceed) in show policy-map commands?
On the ASR9k, every HW queue has a configured CIR and PIR value. These correspond to the "guaranteed" bandwidth for the queue, and the "maximum" bandwidth (aka shape rate) for the queue.
In some cases the user-defined QoS policy does NOT explicitly use both of these. However, depending on the exact QoS config the queueing hardware may require some nonzero value for these fields. Here, the system will choose a default value for the queue CIR. The "conform" counter in show policy-map is the number of packets/bytes that were transmitted within this CIR value, and the "exceed" value is the number of packets/bytes that were transmitted within the PIR value.
Note that "exceed" in this case does NOT equate to a packet drop, but rather a packet that is above the CIR rate on that queue.
You could change this behavior by explicitly configuring a bandwidth and/or a shape rate on each queue, but in general it's just easier to recognize that these counters don't apply to your specific situation and ignore them.
What is counted in QOS policers and shapers?
When we define a shaper in a qos pmap, the shaper takes the L2 header into consideration.
The shape rate defined of say 1Mbps would mean that if I have no dot1q or qinq, I can technically send more IP traffic then having a QIQ which has more L2 overhead. When I define a bandwidth statement in a class, same applies, also L2 is taken into consideration.
When defining a policer, it looks at L2 also.
In Ingress, for both policer & shaper, we use the incoming packet size (including the L2 header).
In order to account the L2 header in ingress shaper case, we have to use a TM overhead accounting feature, that will only let us add overhead in 4 byte granularity, which can cause a little inaccuracy.
In egress, for both policer & shaper we use the outgoing packet size (including the L2 header).
ASR9K Policer implementation supports 64Kbps granularity. When a rate specified is not a multiple of 64Kbps the rate would be rounded down to the next lower 64Kbps rate.
For policing, shaping, BW command for ingress/egress direction the following fields are included in the accounting.
|
MAC DA |
MAC SA |
EtherType |
VLANs.. |
L3 headers/payload |
CRC |
Port level shaping
Shaping action requires a queue on which the shaping is applied. This queue must be created by a child level policy. Typically shaper is applied at parent or grandparent level, to allow for differentiation between traffic classes within the shaper. If there is a need to apply a flat port-level shaper, a child policy should be configured with 100% bandwidth explicitly allocated to class-default.
Understanding show policy-map counters
QOS counters and show interface drops:
Policer counts are directly against the (sub)interface and will get reported on the "show interface" drops count.
The drop counts you see are an aggregate of what the NP has dropped (in most cases) as well as policer drops.
Packets that get dropped before the policer is aware of them are not accounted for by the policy-map policer drops but may
show under the show interface drops and can be seen via the show controllers np count command.
Policy-map queue drops are not reported on the subinterface drop counts.
The reason for that is that subinterfaces may share queues with each other or the main interface and therefore we don’t
have subinterface granularity for queue related drops.
Counters come from the show policy-map interface command
| Class name as per configuration | Class precedence6 | ||||||||
| Statistics for this class | Classification statistics (packets/bytes) (rate - kbps) | ||||||||
| Packets that were matched | Matched : 31583572/2021348608 764652 | ||||||||
| packets that were sent to the wire | Transmitted : Un-determined | ||||||||
| packets that were dropped for any reason in this class | Total Dropped : Un-determined | ||||||||
| Policing stats | Policing statistics (packets/bytes) (rate - kbps) | ||||||||
| Packets that were below the CIR rate | Policed(conform) : 31583572/2021348608 764652 | ||||||||
| Packets that fell into the 2nd bucket above CIR but < PIR | Policed(exceed) : 0/0 0 | ||||||||
| Packets that fell into the 3rd bucket above PIR | Policed(violate) : 0/0 0 | ||||||||
| Total packets that the policer dropped | Policed and dropped : 0/0 | ||||||||
| Statistics for Q'ing | Queueing statistics <<<---- | ||||||||
| Internal unique queue reference | Queue ID : 136 | ||||||||
|
how many packets were q'd/held at max one time (value not supported by HW) |
High watermark (Unknown) | ||||||||
|
number of 512-byte particles which are currently waiting in the queue |
Inst-queue-len (packets) : 4096 | ||||||||
|
how many packets on average we have to buffer (value not supported by HW) |
Avg-queue-len (Unknown) | ||||||||
|
packets that could not be buffered because we held more then the max length |
Taildropped(packets/bytes) : 31581615/2021223360 | ||||||||
| see description above (queue exceed section) | Queue(conform) : 31581358/2021206912 764652 | ||||||||
| see description above (queue exceed section) | Queue(exceed) : 0/0 0 | ||||||||
|
Packets subject to Randon Early detection and were dropped. |
RED random drops(packets/bytes) : 0/0 | ||||||||
Understanding the hardware qos output
RP/0/RSP0/CPU0:A9K-TOP#show qos interface g0/0/0/0 output
With this command the actual hardware programming can be verified of the qos policy on the interface
(not related to the output from the previous example above)
Tue Mar 8 16:46:21.167 UTC
Interface: GigabitEthernet0_0_0_0 output
Bandwidth configured: 1000000 kbps Bandwidth programed: 1000000
ANCP user configured: 0 kbps ANCP programed in HW: 0 kbps
Port Shaper programed in HW: 0 kbps
Policy: Egress102 Total number of classes: 2
----------------------------------------------------------------------
Level: 0 Policy: Egress102 Class: Qos-Group7
QueueID: 2 (Port Default)
Policer Profile: 31 (Single)
Conform: 100000 kbps (10 percent) Burst: 1248460 bytes (0 Default)
Child Policer Conform: TX
Child Policer Exceed: DROP
Child Policer Violate: DROP
----------------------------------------------------------------------
Level: 0 Policy: Egress102 Class: class-default
QueueID: 2 (Port Default)
----------------------------------------------------------------------
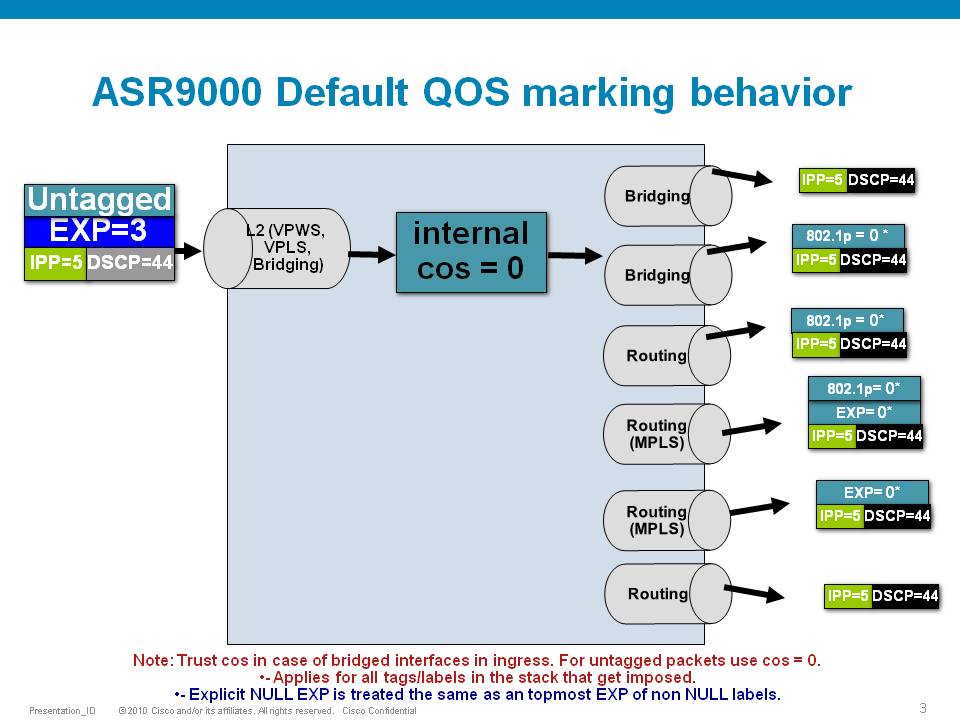
Default Marking behavior of the ASR9000
If you don't configure any service policies for QOS, the ASR9000 will set an internal cos value based on the IP Precedence, 802.1 Priority field or the mpls EXP bits.
Depending on the routing or switching scenario, this internal cos value will be used to do potential marking on newly imposed headers on egress.
Scenario 1

Scenario 2

Scenario 3
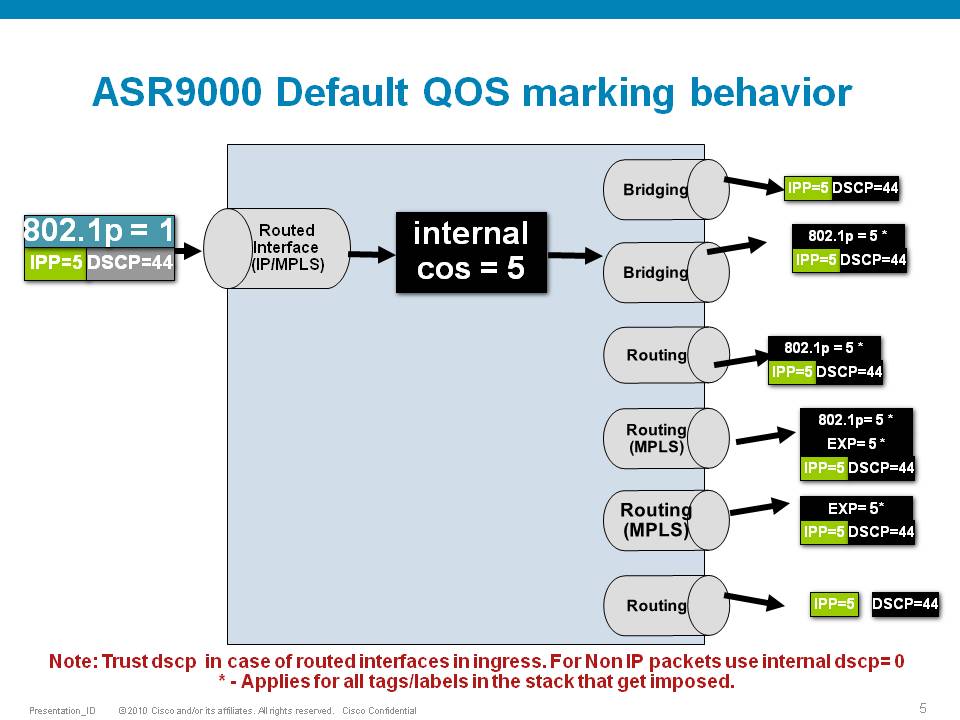
Scenario 4

Scenario 5
Scenario 6
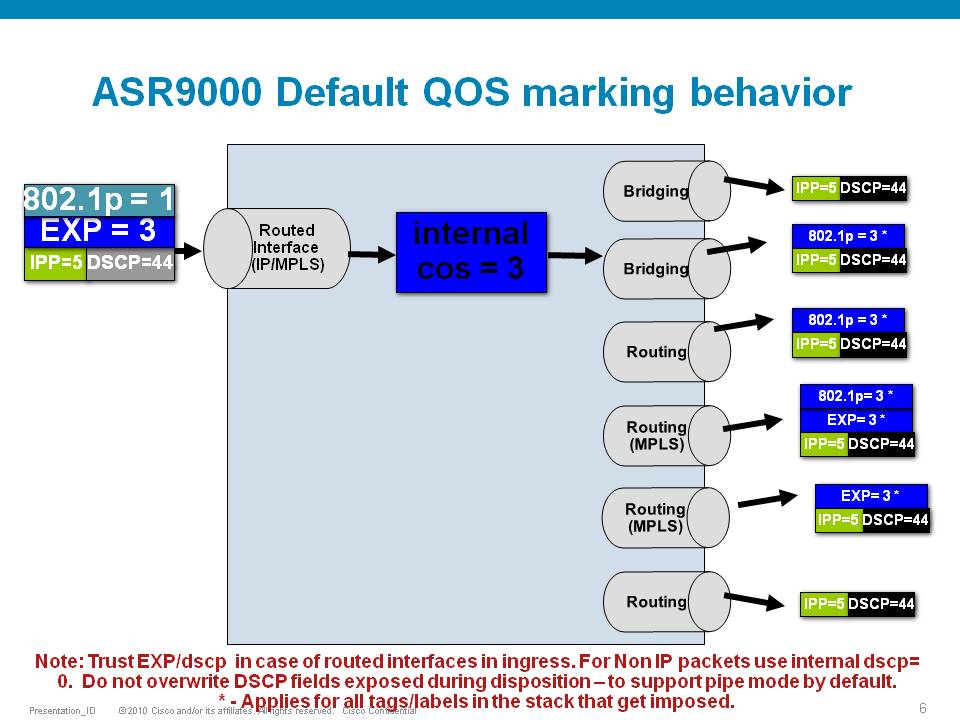
Special consideration:
If the node is L3 forwarding, then there is no L2 CoS propagation or preservation as the L2 domain stops at the incoming interface and restarts at the outgoing interface.
Default marking PHB on L3 retains no L2 CoS information even if the incoming interface happened to be an 802.1q or 802.1ad/q-in-q sub interface.
CoS may appear to be propagated, if the corresponding L3 field (prec/dscp) used for default marking matches the incoming CoS value and so, is used as is for imposed L2 headers at egress.
If the node is L2 switching, then the incoming L2 header will be preserved unless the node has ingress or egress rewrites configured on the EFPs.
If an L2 rewrite results in new header imposition, then the default marking derived from the 3-bit PCP (as specified in 802.1p) on the incoming EFP is used to mark the new headers.
An exception to the above is that the DEI bit value from incoming 802.1ad / 802.1ah headers is propagated to imposed or topmost 802.1ad / 802.1ah headers for both L3 and L2 forwarding;
Related Information
ASR9000 Quality of Service configuration guide
Xander Thuijs, CCIE #6775
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi
This information is great very, important, not to find elsewhere.
Short question, so if I have an interface bundle-eth 200.1 like
interface Bundle-Ether200.1
vrf 201
ipv4 address 192.168.2.2 255.255.255.0
the outgoing MPLS packet will copy over the IP packets QOS setting, IPP or DSCP to the EXP header of the outgoing MPLS packet.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thank you, appreciate it!
when this bundle ether receives a packet and egress's out with MPLS encap, you have scenario 4, which will result in the EXP being set to 5 by default.
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
Very good information and interesting. I have some questions. If my ASR9000 have two line cards (both Low Queue). One is ingress LC (customer facing) and the other egress LC (mpls core facing), and I want to configure H-QoS. Does the LC (type low queue) support H-QoS?, How many levels?, Can I set up two o more priority queues (PQ) on a port (LC type low queue)?. The data sheet said the LC Low Queue support 4K EFPs, Can I configure one QoS policy in each EFP/VLAN/SubInterface with one PQ?, or only I have 8 queues to setup H-QoS to alls 4K EFPs?. If I wan to configure a three-level H-QoS with the following profile: (Can I do it with LC type -L, and two PQs (one by each Vlan) ?)
The egress port should be configured with 2 VLANs each shaped at 1Gbps. Each VLAN should be configured with a 4 class Service Policy as shown in Table 1 below:

Traffic should be generated at 97% of contract; i.e., not oversubscribed.
Thanks in advance and best regards,
Edward.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
hi edward,
the Low Queue card has 8 queues per port. What consumes a queue on egress is the statements for priority, bandwidth and shape. For ingress, the priority statement will not consume a queue.
Policers and markers do not require a queue. Easy way to check it out is configure your desired pmap, apply it to the if and do the command show qos int <int>, you get the hw programming and if there is a (unique) QID then a queue is consumed.
What 8 per port means is that on any given interface eg G0/1/0/1, Te0/4/0/0 or G0/1/0/9 each of those have 8 queues. Those 8 queues are SHARED between the subinterfaces! For instnace, I can have a pmap using 4 queues, then I can apply that to 2 subinterfaces on the same port before I run out.
an EFP is an l2transport interface. Let me assume you have a 40 port Gig card. Then you'd have 1k EFP per NP, and 100 efp's per port. yeah as you can see, not all those port can have a unique queue...
With your example, you'd burn 4 queues. But you could only apply this on 2 EFP's per phy interface.
regards!
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander and thanks for your response. So the 8 queues are consumed when I apply the pmap on interfaces via egress way, and for ingress the 8 queues/port do not have meaning, or I´m wrong. And your assumption is correct the router has A9K-40GE-L and A9K-2T20GE-L line cards.
Best regards,
Edward
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
And only for your reference. My interest to know the capabilities of this Low Queue cards is because I´m typing a Test Plan about this ASR9000 and our Customer wants to know its H-QoS capabilities. I´m answering a RFP, and there are another vendors. My idea is design a test to verify H-QoS capabilities of these low queue cards, for that reason my wish and questions to know the QoS features supported. The idea is design a H-QoS test that this ASR9000 (with Low queue cards) can support and comply.
Regards,
Edward.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander
Is there a need for a QoS Queue, regarding Network protocol for incoming outing WAN CORE interface like for BGP and LDP, ISIS or is there a SPD feature like in the IOS world.
I thinking of designing a standard Wan Core interface, with a qos baseline config with qos for voip Priority level 1 and so on, do I need to build something especially for the routing protocols used in the ASR 9k or is there any by default in the box for those protocol coming into and going out of the ASR 9k.
/Ola
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
If you do ingress Q'ing then you'd also burn queues from the total of 8 per port that the L- cards have.
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Ola, traffic that the RP or LC is injecting is directly enq'd to the port and no acl or qos is needed/available for such packets (this is new behavior in 4.x, in 39x you were able to apply qos for locally originated packets)
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Alexander!
Thank you for the article. I will really appreciate if you can explain the following points:
1). When we are talking about VOQs; as explained in your post that the traffic destined to specific NP will be held if backup pressure is received from that specific NP. What i understood from it is that there will be a kind of tail drop on the ingress port for that specific NP as the NP is being congested i.e. I will have no control which type of traffic should be dropped in case of congestion. Please correct me if i am wrong. If this is the case, it completely destroyes the concept of bandwidth reservation by which we ensures and controls the packet drops for specific queues in case of congestion. Please explain.
2). As I see, there is network processor (NP) chip installed on the card for all L2 & L3 functionalities including ACL, QOS. Is it the exact same chip used in ES+ card of 7600 routers? Does it have the concept of WRED profiles, WFQ profiles of different levels for each TM inside each NP? Pleaes clarify on it.
3). Can you provide more details on QOS explaining specially the limitations and the (REAL) scalaiblity of the QOS features on ASR9000.
Best regards!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
hi atif,
few answers:
1) what you could do is define a policy-map on ingress classifying traffic and marking it as priority 1 or priority 2. This traffic will be put in the HP queues in the forwarding asics and when an egress NP initiates back pressure, it generally flows of the default, normal priority queue. That means that the HP queue will still continue to forward. In the absense of that ingress classification, indeed all traffic would be considered normal priority and would be subject to tail drop, because it has no knowledge of the egress policy-map, hence no notion what is priority on ingress.
2) the next gen cards from 7600 use a similar forwarding network processor, though different code and different functionality then the asr9000.
The A9K's forwarding processor also has the capability of doing WRED.
ASR9k supports 25 different unique WRED profiles per TM/NPU
3) Queues and policer scale: (this below is for the 40G cards, the 80G cards are pretty much double because they have twice as many NP's. (though for the L cards hte limit remains 8 queues per phy port)
Card type | L low queue | B medium/Base | E extended/High |
Queues (eg/in) | 8 per port | 64k/32k | 256k/128k |
Policers (in+out) | 8k | 128k | 256k |
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Dear Alexander,
Thanks a lot for explaining.
1). Lets assume the following scenario:
Egress interface is configured to have the following policy:
policy-map test
class voice
police percent 10
class high-critical-data
bandwidth percent 50
class low-ciritical-data
bandwidth percent 30
class class-default
bandwidth percent 10
!
On the ingress we can either put the traffic in high priority queue & low priority queue. Now lets assume that i configured the ingress policy to put voice and high-critical-data in the high priority queue & low-critical-data and best effort tarffic in the normal priority queue. So, we can have the following scenarios:
>Multiple ingress interfaces are sending all types of traffic to the same egress interface and causing congestion. So, the backpressure will make the normal priority traffic to be dropped at the ingress interfaces to avoid the congestion on the egress interface. This packet drop will be tail drop which means that all traffic falls into normal priority queue will not have the proper bandwidth reservation as configured on the egress interface.
>Multiple ingress interfaces are sending voice and high-critical-data on the same egress interface and causing congestion. So, what does the backpressure will do in this case? Will there be any backpressure? If it exist for high priority queue then will it cause tail drop on the ingress interfaces? If it does tail drop then i have no control which traffic (voice or high critial data) to drop first i.e. bandwidth reservation on the egress interface is not funtioning as i want it to be.
>Multiple ingress interfaces are sending traffic which only falls into normal priority queue on the same egress interface and causing congestion. Same as comment number two, that if the back pressure exist for normal priority queue (which you already have confirmed in your above post), then how will i control the bandwidth reservation on the egress as the low-critical-data and best effort traffic is falling into tail drop on multiple ingress interfaces.
2). There are total of three TMs in one NP. Two for egress traffic and one for ingress traffic. Are 25 WRED profiles is per egress TM? How many WFQ profiles per TM? Can you please comment on: WRED profiles usage depending on which parameters? Like on ES+, we can reuse the WRED profile as long as threshold values, marking (IPP or dscp values) and the mark-probability is same and we can resue WFQ profile as long as the bandwidth percent value inside the class is same (with some exceptions) etc.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Atif,
on question "1" your understandings are pretty much correct.
In case "a", on egress the allocation of bandwidth will be according to your policy-map, say for instance X amount of high priority traffic and Y amount of normal priority traffic. However if on ingress 2 interfaces are both sending Y (so 2*Y total), you'd lose some of that traffic obviously
In case "b", this is also an oversubscription scenario. if you are sending more then the allocated BW you will lose traffic obviously.
For case "c" you may want to consider ingress shaping then. On ingress without a pmap there is no notion as to what you consider higher or lower priority on egress. So if you have 2 best effort classes A and B and they are BW ratios 2:1, on ingress we don't know that you have 2A and 1B, so what ingress might send over the fabric is A+B rather then A+A+B.
As for question "2", also in 9k you can reuse WRED profiles. Hence me specifically stating "unique WRED profiles" in order words you can have 10 profiles reused multiple times on different (sub) interfaces on the same NP no problem.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Dear Alexander,
I really appreciate your reponse. It did help a lot in clarifying my confusions.
Definitely, during oversubscription of the egress interface, i will loose the traffic. The problems on controlling which type of traffic it should drop. What i mean is the following: lets assume on the egress, I have 1 priority queue + 5 normal queues on the egress interfaces. Out of these 6 queues, 4 of them (excluding the priority queue) falls into the normal priority queue on the ingress as i might not want data traffic to be put in the high priority on the ingress along with voice and telepresence traffic. However, among the 4 normal queues on the egress, one queue is more critical to me as compared to the other three queues and hence i did reserve more bandwidth percentage for the critical queue so that in case of congestion, this critical data should have less packet drops (if it oversubscribe the class bandwidth) as compared to the other three normal queues. But because on the ingress, all these 4 queues falls into the normal priority queue on multiple interfaces sending traffic to the same egress interface. all such traffic will face tail drop on all ingress interfaces and hence the bandwidth reservation i did on the egress will not do what i wanted i.e. all 4 (normal) queues of the egress will get equal treatement in terms of packet drop in case of congestion. Please recitify if i mis-understood anything. If this is true, it makes me think that egress policy can only do proper reservation between priority queue & normal queue configured on the egress interface i.e. i can't control the bandwidth reservation among the egress queues which falls into the normal priority queue on the ingress. However, the control we can have among such egress queues is to control the amount of buffers for each different class by which we can control the delay each class should not exceed.
Also, if the packet drops are happening on the ingress in case of egress congestion; how does the back pressure will react to WRED on the egress interface? WRED becomes active before the software buffers runs out of the memory. When will the back pressure kick in? Will it kick in after exceeding the configured maximum threshold.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
Appreciate your help in understand the following scenario:
The physical interface has two subinterfaces, one is L3 routed and the other one is an efp (L2) for only untagged traffic.
The linecard is a 40x1G low queue (8 queues per port) linecard. The policy map "FP-CORE" has 7 configured class-maps + the class-default. The first 6 classes have the "bandwidth" command, the sevent class has police and also priority command. The default class has random detect.
When trying to apply egress policy-map named "FP-CORE" directly on the physical interface. the following message appears:
!!% 'qos-ea' detected the 'warning' condition 'only 6 classes with normal-priority queue (including class-default) are supported per leaf-level of a queuing hierarchy'
As the linecard has 8 queues per port, and the policy FP_CORE is configured with 7 clasess + default class, do Im consuming 7 queues? What could be the reason of the log? Am I missing something?
Paste the config:
policy-map FP_CORE
class SIGNALLING
bandwidth percent 1
!
class MANAGEMENT
bandwidth percent 1
!
class INTRANET
bandwidth percent 4
!
class ROUTING
bandwidth percent 1
!
class VIDEO-ONDEMAND
bandwidth percent 4
!
class VIDEO-BROADCAST
bandwidth percent 10
!
class TOIP-RTP
police rate percent 20
!
priority level 1
!
class class-default
random-detect default
!
end-policy-map
RP/0/RSP0/CPU0:ios(config)#interface GigabitEthernet0/1/0/0
RP/0/RSP0/CPU0:ios(config-if)#description AAAAAAAAA
RP/0/RSP0/CPU0:ios(config-if)#carrier-delay up 10 down 10
RP/0/RSP0/CPU0:ios(config-if)#no shutdown
RP/0/RSP0/CPU0:ios(config-if)#load-interval 30
RP/0/RSP0/CPU0:ios(config-if)#mtu 9216
RP/0/RSP0/CPU0:ios(config-if)#service-policy output FP_CORE
RP/0/RSP0/CPU0:ios(config-if)#
RP/0/RSP0/CPU0:ios(config-if)#
RP/0/RSP0/CPU0:ios(config-if)#interface GigabitEthernet0/1/0/0.792 l2transport
RP/0/RSP0/CPU0:ios(config-subif)#encapsulation dot1q 792, untagged
RP/0/RSP0/CPU0:ios(config-subif)#
RP/0/RSP0/CPU0:ios(config-subif)#interface GigabitEthernet0/1/0/0.732
RP/0/RSP0/CPU0:ios(config-subif)#description XXXXXX
RP/0/RSP0/CPU0:ios(config-subif)#mtu 4470
RP/0/RSP0/CPU0:ios(config-subif)#ipv4 address 192.168.184.230 255.255.255.252
RP/0/RSP0/CPU0:ios(config-subif)#no ipv4 redirects
RP/0/RSP0/CPU0:ios(config-subif)#ipv4 unreachables disable
RP/0/RSP0/CPU0:ios(config-subif)#encapsulation dot1q 732
RP/0/RSP0/CPU0:ios(config-subif)#load-interval 30
RP/0/RSP0/CPU0:ios(config-subif)#commit
LC/0/1/CPU0:Jan 23 13:46:18.951 : ifmgr[173]: %PKT_INFRA-LINK-3-UPDOWN : Interface GigabitEthernet0/1/0/0, changed state to Down
LC/0/1/CPU0:Jan 23 13:46:18.951 : ifmgr[173]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line protocol on Interface GigabitEthernet0/1/0/0, changed state to Down
LC/0/1/CPU0:Jan 23 13:46:19.043 : ETHER_CTRL[156]: %L2-ETHERNET-6-MTU_NEAR_HW_LIMIT : The configured MTU of 9216 on GigabitEthernet0_1_0_0 is close to the H/W limit, and hence large 802.1Q or QinQ frames may be dropped as oversized frames
LC/0/1/CPU0:Jan 23 13:46:19.057 : ifmgr[173]: %PKT_INFRA-LINK-3-UPDOWN : Interface GigabitEthernet0/1/0/0.792, changed state to Down
LC/0/1/CPU0:Jan 23 13:46:19.058 : ifmgr[173]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line protocol on Interface GigabitEthernet0/1/0/0.792, changed state to Down
LC/0/1/CPU0:Jan 23 13:46:19.074 : ifmgr[173]: %PKT_INFRA-LINK-3-UPDOWN : Interface GigabitEthernet0/1/0/0.732, changed state to Down
LC/0/1/CPU0:Jan 23 13:46:19.075 : ifmgr[173]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line protocol on Interface GigabitEthernet0/1/0/0.732, changed state to Down
LC/0/1/CPU0:Jan 23 13:46:19.100 : ETHER_CTRL[156]: %L2-ETHERNET-6-MTU_NEAR_HW_LIMIT : The configured MTU of 9216 on GigabitEthernet0_1_0_0 is close to the H/W limit, and hence large 802.1Q or QinQ frames may be dropped as oversized frames
LC/0/1/CPU0:Jan 23 13:46:19.244 : ifmgr[173]: %PKT_INFRA-LINK-5-CHANGED : Interface GigabitEthernet0/1/0/0, changed state to Administratively Down
% Failed to commit one or more configuration items during a pseudo-atomic operation. All changes made have been reverted. Please issue 'show configuration failed' from this session to view the errors
RP/0/RSP0/CPU0:ios(config-subif)#
RP/0/RSP0/CPU0:ios(config-subif)#show conf failed
Mon Jan 23 13:46:24.671
!! SEMANTIC ERRORS: This configuration was rejected by
!! the system due to semantic errors. The individual
!! errors with each failed configuration command can be
!! found below.
interface GigabitEthernet0/1/0/0
service-policy output FP_CORE
!!% 'qos-ea' detected the 'warning' condition 'only 6 classes with normal-priority queue (including class-default) are supported per leaf-level of a queuing hierarchy'
!
end
Thanks,
Carlos Trujillo.
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: