- Cisco Community
- Technology and Support
- Service Providers
- Service Providers Knowledge Base
- ASR9000/XR Understanding Route scale
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 06-28-2012 07:17 AM
- Introduction
- Do I have a Trident or a Typhoon linecard?
- What is the difference between the L/B/E type of the cards?
- What about these hw-module scale profile commands on Trident ?
- Understanding IPv4 and IPv6 route scale
- Understanding Subtrees
- Monitoring L3 Scale
- Using the ASR9000 as a Route Reflector
- Related Information
Introduction
In this document we'll discuss how the route scale of the ASR9000 linecards work. There is a significant difference between the first generation linecards known as Trident based vs the next gen linecards that are Typhoon based.
In this article you'll find guidance to identify if you have a Trident or Typhoon linecard, what the scale type really means and what it affects, how the rotue scale parameters work on Trident and how the route scale is different on Typhoon.
Do I have a Trident or a Typhoon linecard?
The following linecards are Trident based:
40G series:
A9K-4T
A9K-8T/4 (8 port 10GE oversubscribed linecard)
A9K-2T20G
A9K-40GE
80G series:
A9K-8T
A9K-16T/8 (16 port 10GE oversubscribed linecard)
Regardless of the scale version denoted by the suffix -L, -B, -E
The following linecards are Typhoon based:
A9K-24x10GE
A9K-100G
A9K-MOD80
A9K-MOD160
and the ASR9001
Regardless of the scale version denoted by the suffix -TR, -SE
SIP-700 is CPP based
What is the difference between the L/B/E type of the cards?
All ASR9000 linecards come in different scale versions with different price points. The scale version does NOT affect the route scale.
Also the architectural layout of the linecard is the same and all features supported on one type of the linecard is supported on other scale versions also.
So what is precisely different then between these line card scale types?
The following picture gives a layout of the Network Processor (NP) and the memory that is attached to it.

The lookup or Search memory is used for the L2 MAC table (in IOS terms "CAM" table) and by the FIB (Forwarding Information Base, eg where the CEF table puts the forwarding info).
The L/B/E cards change the Stats, Frame and TCAM size and therefore derive a different scale based on:
Stats memory:
Interface counters, QOS counters, EFP counters.
The more stats memory I have, the more QOS Policies I can have, the more interfaces/EFP's/Xconnects etc I can support on this card.
Frame memory:
Used for packet buffering by QOS
The more frame memory I have allows me to buffer more packets in the queues
TCAM:
Used by vlan to interface matching (eg I get a vlan/combo in and to which subinterface does that match the closest), ACL scale and QOS matching scale.
The SEARCH memory is not changing between L/B/E hence the Route or MAC scale remains the same between these cards.
To Sum up: The difference between L/B/E (for Trident) or TR/SE (for Typhoon) mainly affects the:
- QOS scale (Queues and Policers)
- EFP scale (L2 transport (sub)interfaces and cross connects)
What does not change between the types is:
MPLS label scale, Routes , Mac , Arp , Bridgedomain scale
What about these hw-module scale profile commands on Trident ?
The Trident linecards provide a great amount of flexibility based on the deployment scenario you have.
As you could see from the above description, the search memory is not affected by the scale type of the linecard.
Considering that the ASR9000 was originally developed as an L2 device, it divided that search memory shared between MAC and Route scale
in "favor" of the MAC scale leaving a limit route capability.
With the ASR9000 moving into the L3 space we provided scale profiles to effectively adjust the sharing of the Search memory between L2 and L3 in a more user defined manner. So by using the command
RP/0/RSP1/CPU0:A9K-BOT(admin-config)#hw-module profile scale ?
default Default scale profile
l3 L3 scale profile
l3xl L3 XL scale profile
You can move that search memory in favor of L2 or L3:
"default" or L2 mode l3xl mode


Which inherently means that the increase FIB scale goes as the cost of the MAC scale and in the following manner:

Notes:
1) This scale table is Trident specific.
2) Some values are testing limits eg IGP routes, some are hardware bound
3) The EFP number is dependant on the scale type of the linecard (E/B/L), which this tries to show is that the EFP scale is not affected by the HW profile scale command.
Typhoon Specific
Typhoon has a FIB capability of 4M routes. Typhoon uses separate memory for L2 and L3 and therefore the profile command discussed above is not applicable to the Typhoon based linecards.
Understanding IPv4 and IPv6 route scale
As you can see in the scale table above the number of IPv6 routes is half of the number of ipv4 routes. v6 routes consume more space in the FIB structures and the system calculates in this manner that the number of v6 routes consumes twice as much as the number of v4 routes.
Now when we state that we have 1M FIB scale in the L3 mode. We should read it as 1M credits.
Then knowing that a v4 route consumes 1 credit and an ipv6 route consumes 2 credits, we can compile the following formula:
Number of IPv4 routes + 2 * the number of IPv6 routes <= Number of credits as per scale profile
Typhoon Specific
This logic of v4/v6 scale is the same for Typhoon, but with the notion that Typhoon has 4M credits
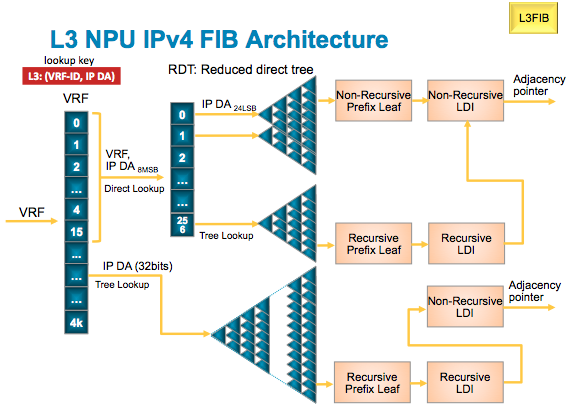
Understanding Subtrees
One concept that was referenced in the scale table is the SUBTREE. Subtree is a method of implementing a Forwarding Information Base. Trident uses this implementation methodology.
While the route scale in say the L3 profile is 1M ipv4 routes, it depends which VRF the routes are in based on their tableID and what the subtree size is.
Table ID's 0 to 15 have a subtree assigned per /8. That means that they can reach a 1M route scale individually as long as you don't exceed the number of routes per subtree size. In L3 mode the subtree size is 128k. That means in order to reach the 1M route scale I need to assign 8 /8's filled with 128K each to reach that one million routes.
Note the route scale mentioned is the sum of all routes together combined of all vrf's
VRF table ID's higher then 15 to the max vrf scale only have one subtree total which means that the route scale for those VRF's is 128k tops in L3.
IPv6 routes have one subtree period, meaning that V6 cannot have more then the subtree size as directed by the scale profile configured.
The following picture visualizes the subtree.
Each subtree can point to either a non recursive leaf (NRLDI) or a recursive leaf (RLDI)
- You can have 4 (or 8, requires admin config profile and has some pps implications) recursive ECMP (eg BGP paths)
- Each of those recursive can point to 32 non recursive paths (eg IGP loadbalancing)
- Which in turn can be a bundle path with 64 members max.
How to find the tableID of a vrf
Note that tableID's are assigned only when you enable an IP address on one interface that is member of the vrf.
RP/0/RSP0/CPU0:Viking-Top#show uid data location 0/0/CPU0 gigabitEthernet 0/0/0/2 ingress | i Table
Fri Apr 9 16:24:32.878 EDT
Table-ID: 256
RP/0/RSP0/CPU0:Viking-Top(config)#vrf GREEN
RP/0/RSP0/CPU0:Viking-Top(config-vrf)#address-family ipv4 unicast
RP/0/RSP0/CPU0:Viking-Top(config-vrf-af)#commit
RP/0/RSP0/CPU0:Viking-Top(config-vrf-af)#int g0/0/0/12
RP/0/RSP0/CPU0:Viking-Top(config-if)#vrf GREEN
RP/0/RSP0/CPU0:Viking-Top#show uid data location 0/0/CPU0 gigabitEthernet 0/0/0/12 ingress | i Table
Fri Apr 9 16:22:40.263 EDT
Table-ID: 512
RP/0/RSP0/CPU0:Viking-Top#
Table ID assignment:
1) when an RSP boots, tableID assignments start at 0. (verified in labs)
2) ID zero is reserved for the global routing table. (given)
3) The first 15 tableID’s can carry > 128K* routes, given that no more than 128k* routes per subtree(/8) (given limitation)
4) Understanding that reconfiguring a VRF would increment the tableID values (verified in lab), and might eventually push it out of the preferred table space.
5) No more than a total of 1M routes per system (or as defined by the scale profile), regardless of in which tableID these routes are.
6) In order to reach that of 1M route scale, the command hw-module profile l3 or l3XL needs to be configured.
If you have <15 VRF’s configured, reloading would still result in the fact that these tableID’s will get in the larger table space (tableID assigned <15).
Although one vrf may not get assigned the same tableID value after reload, but this is not interesting from a user perspective.
NOTE1: table ID is a 16 bit value, that is byte swapped. So tableId 1 has value 256, table id 2 has value 512 etc
NOTE2: We're working on an enhancement to make a vrf "sticky" to a particular tableId so you can make sure that this vrf will always get the higher route scale. Track: CSCtg2546 for that.
*NOTE3: 128k or 256k depending on the scale profile used. Some older pre 401 releases had a smaller subtree size of 64k.
Typhoon Specific
Typhoon uses the MTRIE implementation for the FIB and therefore the above Subtree explanation and its associated restrictions do NOT apply to linecards using the Typhoon forwarder.
Monitoring L3 Scale
You can use SNMP for this by pulling the route summaries for EACH vrf or using the CLI command as follows:
RP/0/RSP0/CPU0:A9K-TOP#show route vrf all sum
VRF: RED
Route Source Routes Backup Deleted Memory (bytes)
connected 1 1 0 272
local 2 0 0 272
bgp 100 0 0 0 0
Total 3 1 0 544
VRF: test
Route Source Routes Backup Deleted Memory (bytes)
connected 0 1 0 136
local 1 0 0 136
bgp 100 1 0 0 136
Total 2 1 0 408
VRF: private
Route Source Routes Backup Deleted Memory (bytes)
static 0 0 0 0
connected 1 0 0 136
local 1 0 0 136
bgp 100 0 0 0 0
dagr 0 0 0 0
Total 2 0 0 272
The number of routes is provided per source (IGP/BGP etc) and for the FIB that doesn't matter.
Also the memory that is presented is XR CPU memory and is not the memory that is used by the hardware.
Because of the Trident subtree implementation, if you want to be accurate you need to count the number of routes in the VRF table ID's
0-15 (and tableID0 being the global routing table) on a per /8 bases.
Show commands
This is the global view as to how things are implemented.
- The RIB, routing information base solely resides on the RSP and is fed by all the routing protocols you have running.
- The size of the RIB can grow as far as memory scales.
- The RIB compiled a CEF table which we also call the FIB, forwarding information base which is distributed to the linecards
- The linecards complete the FIB entries with the L2 Adjacencies (eg ARP entries which are isolated to the linecards only, UNLESS you have BVI's when those L2 ADJ's are shared on all LC's)
- The complete entry is then programmed into the NPU.




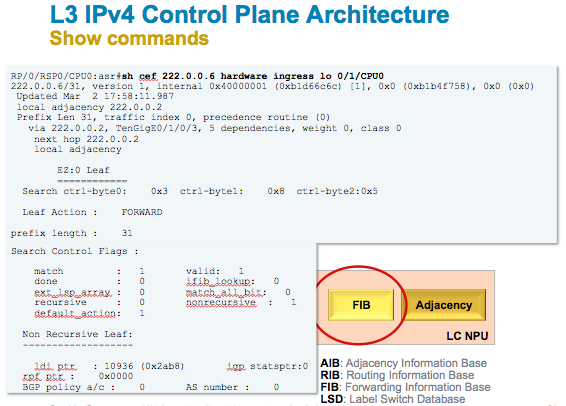
Summary view
The easiest way to verify and validate resources for the linecard is via this command:
RP/0/RSP1/CPU0:A9K-BOT#show cef resource loc 0/1/CPU0
Thu Jun 28 11:02:41.855 EDT
CEF resource availability summary state: GREEN
CEF will work normally
ipv4 shared memory resource: GREEN
ipv6 shared memory resource: GREEN
mpls shared memory resource: GREEN
...
Using the ASR9000 as a Route Reflector
This can be done no problem. A route reflector is generally never in the forwarding path of the traffic. This means that we can put all the routes in the RIB and not install them in the FIB based on a policy.
We can use the table-policy under the BGP config to pull in an RPL that denies the installation of routes into the FIB.
Then we can use the RP CPU memory for reflecting routes as far as memory scales.
How far we can go?
Depends on the Paths, attributes, size of the attributes and whether you have the high or low scale RSP memory version.
Numbers can be anywhere from 7M to 20M, depending.
ARP vs MAC scale and understanding adjacencies
This is a topic I noticed leading to some confusing. It is important to understand the difference between MAC vs ARP scale.
MAC vs ARP
While MAC refers to what we know in switches as the "CAM" table, so basically the mac learning forwarding table, ARP scale refers to the number of ARP adjacencies that an L3 router can hold to complete the mac rewrite string to forward traffic to its L3 peers.
MAC scale is defined by the L2 bridging tables and is subject to scale differences on Trident LC's depending on the hw-module profile ran, whereas on typhoon the MAC scale is in a separate forwarding table (switching table) that is limited to 2M macs tops.
ARP scale
The ARP scale is something tricky, while the hardware forwarder has lots of mem available to complete the forwarding adjacency, the software may not. Few details:
ARP is local to the linecard, e.g. it serves no purpose for an ingress linecard to know what the ARP entry for a destination is that lives on another linecard. Since the ingress linecard would just forward the traffic over to the destination LC, it doesn't need to know the ARP/mac address of the destination interface.
This allows for a great scale improvement! ASR9000 has been tested with 128k of those ARP adj per LC! that is massive already, but not bound by that number.
There are a few stipulations when it comes to:
-BVI
-Bundle/Etherchannel
You can figure that if the egress interface is a bundle-E or a BVI the arp adj needs to be present on multiple linecards and specifically those that hold members in that bundle or carry EFP (Ether flow points or l2transport interfaces in a say Bridge domain) in the scenario of BVI.
SW processing of ARP
XR software stores the ARP table in what we call shared memory, this is basically a RAM disk (if you're familiar with the old DOS technology) that can technically grow as far as memory goes on the LC. It means that the limit of 128k ARP entries is a "soft limit" and can go farther, but requires the right amount of memory on the LC to be avaiable. Some deployment profiles take more LC memory and therefore may not grow as far as we'd like.
ARP is received by the NPU as a "for me" packet and punted by LPTS to the LC CPU for processing.
There is a single queue which holds all of the arp requests and replies.
The CPU utilization is a factor also to determin the processing capability and scale for ARP.
Packet forwarding with BVI and Bundle
When forwarding over a L3 (routed) adjacency, we obviously need to know the destination mac address to complete the layer 2 header. When the router port is connected to a server, the dmac will be the server's mac address, in the case of a peering router, it will be the mac address of the remote interface. That is all standard and simple. Because an egress linecard does all the encap for this layer 2, there is no need for an ingress linecard to know what the arp entry is for a destination interface, that increases the scale.
When it comes to bundle and bvi, the ARP entry has to be replicated to those locations that have members in the bundle for instance. The following pictures explain:
BVI processing with EFP's on different linecards:
Here you can see that every linecard that has a routed port, needs to know the ARP entry, so in BVI all linecards will see the ARP entry tied to a BVI (that means L2 destinations -> EFP's).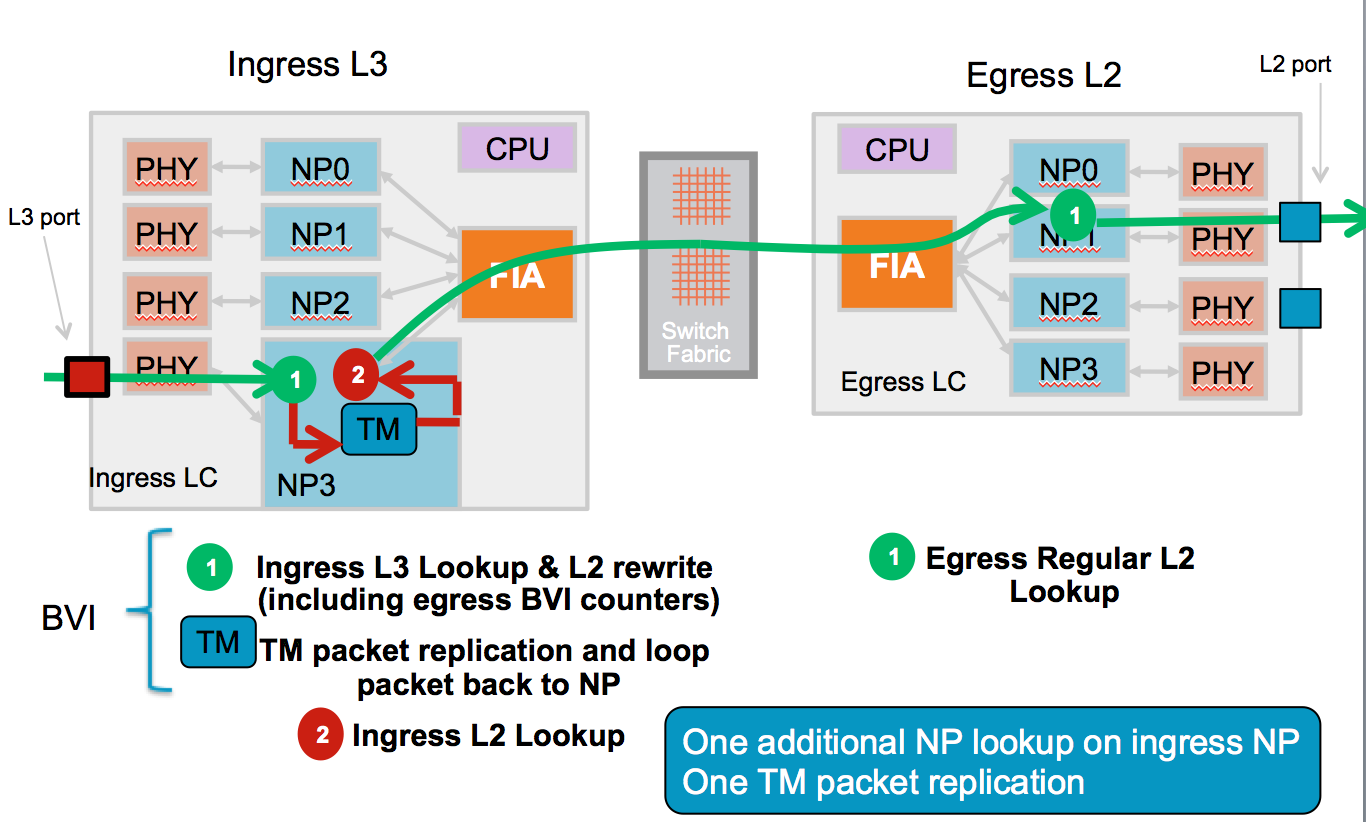
Bundle forwarding with members on multiple linecards
In bundle when running as a L3 routed interface the ingress linecard does the processing as normal, determines the egress interface, which is a bundle in this example and then determines that the member to be selected can be on either one or the other LC. It forwards that packet to the fabric and to the destination linecard that holds the member of the bundle.
In this case, all inecards that have a member in the bundle need to know the ARP address to complete the forwarding mac rewrite and L2 headers.
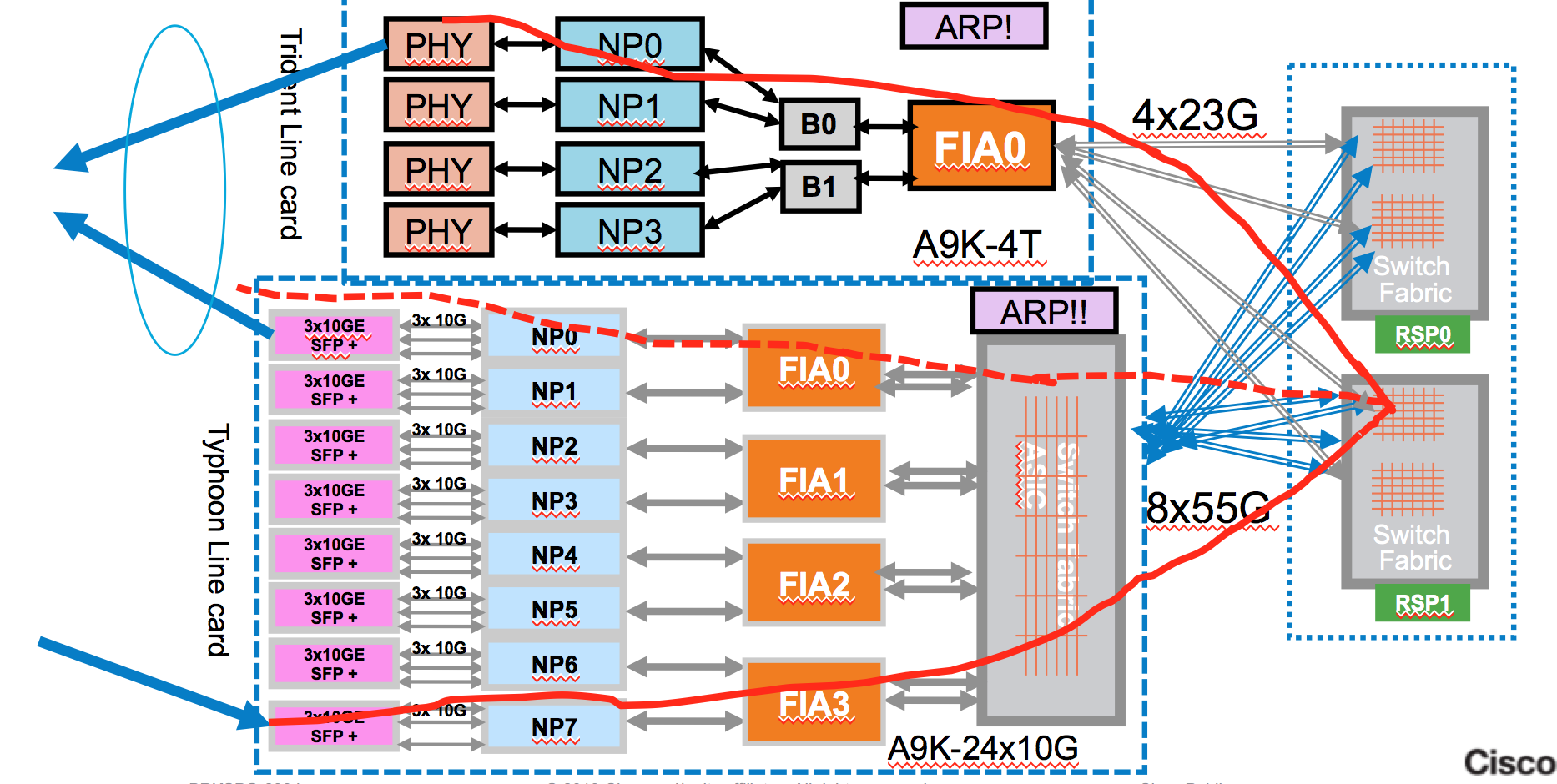
How to verify
To verify how many ARP entries a linecard holds we can use this command:
RP/0/RSP0/CPU0:A9K-BNG#show adj summary location 0/0/cPU0
Wed Jan 27 17:10:56.465 EDT
Adjacency table (version 1284) has 66 adjacencies:
28 complete adjacencies <<<< learnt adj's from remote destinations
0 incomplete adjacencies
38 interface adjacencies <<<< local adj's that are bound to my interfaces
0 deleted adjacencies in quarantine list
19 adjacencies of type IPv4 <<< by AFv4 address family
19 complete adjacencies of type IPv4
0 incomplete adjacencies of type IPv4
0 deleted adjacencies of type IPv4 in quarantine list
14 multicast adjacencies of type IPv4
4 adjacencies of type IPv6 <<<< and here for ipv6
4 complete adjacencies of type IPv6
0 incomplete adjacencies of type IPv6
0 deleted adjacencies of type IPv6 in quarantine list
4 multicast adjacencies of type IPv6
Ultimately
Ultimately the ARP scale for an asr9000 device or XR in general is dependent on a few things:
- the number of L2 devices attached (which will grow in bridge domains)
- if there are bundle or BVI in play (that will need to hold AND replicate entries across linecards)
- how much free memory is available on the linecard
ARP scale *can* grow, but there is another factor: LPTS. LPTS defines a policer for ARP requests (and learning). XR does passive learning meaning that if we see a request FROM a host, we "learn" that host and add it to our table. This is awesome because now we don't need to ask for the hw-addr for that host that we learnt and saves messaging. However that will increase the table size. And then we're back with the stipulations mentioned earlier; how much memory do we have available.
Although ARP has significant improvements in XR 5.3.1, since it is a single threaded process more can be done, which we are planning for. For instance, making ARP multi-threaded (though work), or applying queue management for handling better the volume of incoming requests.
Remember that LPTS policers values are set per NPU, so if you have an LC with multiple NPU's, the total forwarded rate can be a multiplication of the configured value byt he number of NPUs on that LC.
Tuning of LPTS policers may be necessary to help XR deal better with the volume of ARP requests.
Related Information
N/A.
{kind=link}
{kind=link}
{kind=link}
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
what is in a mixed environment meaning a trident and a typhoon line card in the same chassis. how is this affecting the route scale? does the route scale remains at 1M?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Alexander,
Can you please tell me the difference between A9K-MOD80-SE and A9K-MOD80-TR in details?
Thanks
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
If you mix both trident and typhoon and knowing that the FIB is loaded to all cards, then you run into the lowest common denominator scenario whereby effectively you're limited by the trident route scale. When you exceed trident fib scale, typhoon will hold the routing info just fine, but trident will have an incomplete FIB.
You could leverage selective-vrf-download to limit the routes on edge facing trident cards that only hold those routes for those vrf's it serves.
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
The major difference between TR and SE cards is the size of the memory attached to the NPU.
SE cards have more STATS memory, TCAM and FRAME memory. So on SE cards you can support more (sub)interfaces/EFP's, QOS policies, buffering, larger ACL's and more QOS classes.
The TR card is the equivalent to the Trident -L card, and the SE version is equivalent to the -E card. (there is no -B type for typhoon).
TR cards have also a limit of 8 queues per interface.
Note that the FIB and MAC scale is the same for both TR and SE cards.
regards
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Alexander,
What about XR version (P and PX) does it influence route scale? Or the RSP? I’m asking this, because while doing some tests with a Trident based scenario (and “old” RSP) and a Typhoon + Trident scenario (with RSP440) I found different limits for the Trindent LCs.
On Trindent only scenario I was able to reach 256K IPV6 routes in CEF. On Trident + Typhoon scenario only 128K IPv6 routes was installed in CEF.
Thanks!
Cheers,
Pedro
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
hi pedro,
hte RSP version (which determines p vs px) doesnt affect the route scale (other then the RIB scale size, which is always higher then what the hardware can support anyway).
Trident is bound by subtree's and the subtree size is defined by the hw-module scale command. You will need the L3XL
to get the 256k per subtree.
Typhoon doesn't have subtree's so you are not limited by that, nor does the hw scale profile apply to these cards.
Depending on your version you may be running in a lowest common denominator limit here, which is a sw limit whereby typhoon is limtied to 128k because that is the trident default and l3 scale sizes. So you may need to override that.
regards
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
Thanks for your prompt reply.
So the rule "Number of IPv4 routes + 2 * the number of IPv6 routes <= Number of credits as per scale profile" doesn't apply to Trident LCs in default profile?
Cheers,
Pedro
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Pedro, that forumula applies for both trident (regardless of scale profile) and typhoon.
the subtree limitation is trident specific, and the subtree size is dependent on the scale profile ran on it.
That subtree situation does not apply to typhoon (as it uses mtrie)
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi alexander,
Regarding the use of the ASR9001 as a route-reflector isn't it much easier to overload all of the router self-generated routes ? So this RR will never be in the transit path. RR only reflect the routes whithout influencing BGP path selection process. And This scenario is true if we're using a dedicated RR to reflect only VPNv4 routes.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Several options for RR;
using XRVR (the xr virtual router) running on a blade, has no forwarding, just control plane, with dedicatd functionality of RR mainly as of now.
For a RR not in the forwarding path there is no need for the FIB routes, just how to get to the BGP speakers (so IGP only I would say).
You can use the table policy in RPL to prevent route installation in the RIB and just contain it in the BGP table for reflecting.
I have an article on route policy language also discussing that, let me know if you can't find it.
thanks
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
hi Xander,
quick question regarding resource allocation. say i'm using the default profile and basically the number of MACs learned is close to 0. does that mean that the box will use the L2 memory to learn L3 routes as long as that memory is free and claim it later if needed?
another question is regarding L3, what if i'm not running ipv6, do get to learn more than 512 k ipv4 routes in default mode?
i'd appreciate it if you'd elaborate further regarding this use case.
in 7600 there is a command 'show platform hardware capacity' that allows you to see more specific memory use statistics. is there such a command in asr9k?
thanks in advance!
c,
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
hey carlos, the memory for L2 and L3 is shared, and is precarved at system boot time.
so if you are in default profile mode, then both L2 and L3 have 512k mac and 512k routes.
the routes cant take the memory from L2 in this case as it is not its region.
if you put the profile mode into L3 or L3XL, in that case the precarved mem allows for more routes at the expense
of L2 mac table size.
Know the command you ref, but dont have that. I think there is a show l2vpn capability command, but not sure how well it updates in the profile modes, also it doesnt show you how far a long you are in the usage of the actual mem tables.
it is a "manual" effort by counting (or using utility wc -l to count hte lines = macs etc or use show route summary to get a route impression)
regards
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thank you very much, Xander.
Just to be clear, behavior would be the same regarding v4/v6 routes, correct? (Like you explained L2/L3 entries)?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Correct when we state L3 scale it is v4 and v6 combined as per formula mentioned above.
so L3 profile with 1M credits, v4 taking one credit, v6 taking 2. Typhoon having 4M credits.
Note that typgoon has dedicated L2 and L3 memroy and no carving is necessary, hence profile config doesnt apply there.
cheers!
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thank you very much, Xander. Got it.
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: