- Cisco Community
- Technology and Support
- Data Center and Cloud
- Application Centric Infrastructure
- one EPG, multiple IP subnets
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 06:05 AM - edited 03-01-2019 05:05 AM
Hi gang,
the learning curve continues!
In our environment, we have a collection of tenants, and each tenant has a collection of subnets. The subnets are defined at the EPG level.
Some of the teams using this environment need to be able to have multiple subnets on an EPG. For example, if Tenant1 has an EPG called EPG1, and that EPG1 has a defined subnet of 10.10.10.1/24, any end points in that EPG have a 10.10.10.x/24 IP address. However, in addition, in the same EPG1, they sometimes need to use a 192.168.1.x/24 IP address. This is because one of the products we use comes with a default IP address of 192.168.1.1 and it needs to be reachable for initial configuration - including setting an IP address on the 10.10.10.0/24 network.
This is where it gets confusing (for me).
the 10.10.10.0/24 subnet works fine. The gateway (at .1) works fine, and all is good. Now, when someone adds a secondary IP on their system of 192.168.1.2 so they can reach a device on 192.168.1.1, this works most of the time, but sometimes, the device with the 192.168.1.1 address is not reachable. It appears as if ARP is not working. This is literally 1 out of 20 times or less. In this state, the "controller" system at 192.168.1.2 is unable to ping (or otherwise reach) the device with the 192.168.1.1 address. the MAC address for the 192.168.1.1 system never appears in the ARP cache on the 192.168.1.2 system.
There are some things that make it work though.
1.) if you initiate comms FROM the 192.168.1.1 device, then it begins to work.
2.) if you add a second subnet of 192.168.1.0/24 (say, 192.168.1.254/24) to the EPG, it begins to work.
I expected that tenants could assign any IP to any system within any EPG that they wanted to. Obviously, only IPs on the same subnet as the fabric's gateway address would be routable out of the EPG, but I still expected that they could use the 192.168.1.0/24 network within the EPG even though it's not configured through the fabric.
So, what am I misunderstanding here? Should a tenant be able to use any IP space (notably IP space that is not assigned to the fabric) and have IP connectivity to other systems on the same subnet within the EPG? Do I have to add the 192.168.1.0 subnet to every EPG that is going to need to work on these devices?
Any insights you guy have would be very much appreciated. I'm pounding my head against the desk right now trying to figure out why this doesn't work.
Thanks!
Joel
Solved! Go to Solution.
- Labels:
-
Cisco ACI
Accepted Solutions
")
")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 08:01 AM
Ok, did some further research and had to confirm a few things.
When you 192.168.1.x/24 host sends his ARP, the Leaf receives it as unknown unicast - so we proxy it up to the Spine. The Spine does a looked up and sends it back to all Leaf switches with the corresponding BD. When the Leaf receives this packet it does a subnet lookup - If the Leaf & BD does not have the subnet defined we drop it. This is a security mechanism to stop ARP DDoS attacks in a way.
If the Leaf & BD have the subnet configured, it will forward (flood) the packet to all ports under within the BD.
So contrary do my initial advice - your secondary subnet does indeed need to be defined within the BD.
Here's the two scenarios to help you understand.
ARP to BD Endpoint without Subnet IP Defined
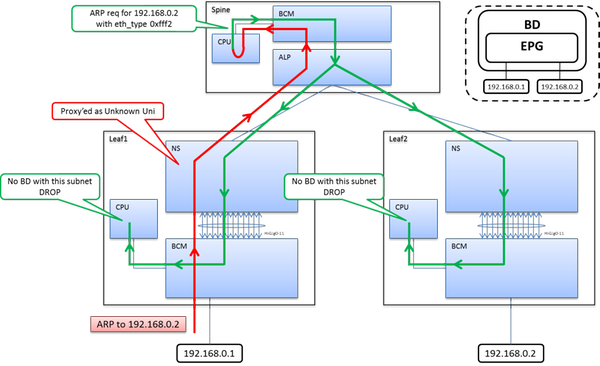
ARP to BD Endpoint with Subnet IP Defined
Robert
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 06:13 AM
Hey Joel,
Firstly, unless you're doing Inter-VRF contracts or route leaking, you should really define the subnet at the BD level, rather than the EPG. There's no issues running multiple subets within a single EPG.
Can you elaborate on your hosts a bit more.
1) Do they have dedicated interfaces for each subnet, or are you using a single interfaces with VLAN trunking?
2) Are you using physical domains (static path bindings) or VMM domains?
Also, please post the configuration of the bridge domain(s) your EPGs are using. (You can right click on the Bridge domain - Save As - "Only Configuration", Subtree, JSON) and post the .json file to this thread.
Robert
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 06:24 AM
Thanks Robert!
I'd love to get a better understanding of why creating subnets at the BD level is better than at the EPG level. This is something else I've been curious about, but I really don't understand the pros/cons or reasons.
In any event, back to the issue.
The device is an appliance VM. It has several virtual network interfaces, but in it's initial state, only one is active and assigned an IP address of 192.168.1.1. There is no bonding, no vlan trunking, etc. just a plain jane VM with a vmxnet3 NIC. By default, it comes up with a 192.168.1.1 IP address, and in small deployments, you'd typically just get on the vmware console and configure the device with the IP address you want/need. In our case, we are doing fairly large scale deployment and testing of these appliances, so we are automating the process. What we'd like is a "controller" system that's on the EPG subnet (10.10.10.x) and reachable outside of the tenant. it has a secondary NIC attached to the same EPG (port group in vmware) with 192.168.1.2. We then clone an appliance, boot it up, ssh into it on the 192.168.1.1 IP address and run a configuration script that configures the IP for the 10.10.10.0 network, then moves on to the next one. I was totally expecting this to be easy.
Here's the BD configuration.
{"totalCount":"1","imdata":[{"fvBD":{"attributes":{"arpFlood":"no","descr":"Bridge Domain for systest","dn":"uni/tn-systest/BD-systest-bd","epMoveDetectMode":"","ipLearning":"yes","limitIpLearnToSubnets":"no","llAddr":"::","mac":"00:22:BD:F8:19:FF","mcastAllow":"no","multiDstPktAct":"bd-flood","name":"systest-bd","ownerKey":"","ownerTag":"","type":"regular","unicastRoute":"yes","unkMacUcastAct":"proxy","unkMcastAct":"opt-flood","vmac":"not-applicable"},"children":[{"fvRsBDToNdP":{"attributes":{"tnNdIfPolName":""}}},{"fvRsCtx":{"attributes":{"tnFvCtxName":"systest-vrf"}}},{"fvRsIgmpsn":{"attributes":{"tnIgmpSnoopPolName":""}}},{"fvRsBdToEpRet":{"attributes":{"resolveAct":"resolve","tnFvEpRetPolName":""}}}]}}]}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 06:54 AM
Is there any reason you're not using two separate EPGs for each interface? Also, since you're cloning the VMs, you're going to temporarily have duplicate addresses. Shouldn't be an issue, but the fabric might see this as a flap event. I'd suggest leaving the VMs interfaces in a "Disconnected" state (at the VM Edit-settings level) when doing the cloning, and re-enable them once the correct IPs have been assigned.
Another idea is that perhaps the default 192.168.1.x address is silent. Trying to ping this device from your controller may not work until we get some communication from the host.
I'd try this test - When the newly cloned VM Appliance is "unreachable" are you able to initiate traffic from the Appliance? This will allow the fabric to learn the MAC info. Then retry reachability from the controller to this Endpoint.
You could also try to enable ARP Flooding on the BD and see if that helps.
Robert
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 07:14 AM
Hi Robert,
thanks for the feedback. No reason in particular other than that we want the appliance to end up on in the given EPG on the 10.10.10.0 network. We can't leave the interface on this appliance disconnected because that's the only way we can get onto the device to do the initial configuration. We can't, for example, set an IP address through vmware tools because the appliance will overwrite any configuration we do on first boot - including setting the IP address back to 192.168.1.1... so while we can push an IP into the VM through vm tools, it gets overwritten at first boot. So the only way we can do this somewhat automatically is to be able to reach the appliance on that default 192.168.1.1 IP address and configure it through a command shell over SSH. We are also toying with a vmware virtual serial port, but that has other complexities.
Your second idea sounds like what we're seeing. When the appliance boots up, we try to reach it from the "controller" vm (192.168.1.2) but are unable to. While troubleshooting, we found that if we initiate some comms FROM the appliance, then everything works. So, as you suggest, the appliance appears to be "silent" until some network activity from it (the appliance) is created. We may be able to inject something into the template that causes the appliance to create some network activity on first boot I guess if that's the only way... I just don't understand why ARP doesn't just work. We tried ARP flooding, but that didn't appear to work either.
OK, so at least I'm not crazy. We'll keep chipping away at this and trying to find a way to make it work.
....if you have any pointers to more info about why subnets on the BD are better than on the EPG, I'd gladly take them!
cheers, and thanks for your help!
Joel
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 07:38 AM
I provided some on the BD vs. EPG subnet question higher in the thread.
One thing you hadn't mentioned yet was if you're doing static path bindings or VMM integration (vDS or AVS).
Other than leaving the VM NIC disconnected after cloning, have you just tried flapping it? Disconnect/Connect? This might be enough to generate traffic from the host so ACI can learn about the EP.
I'll keep researching this for you.
Robert
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 07:41 AM
Can you try creating a dummy BD Subnet for the 192.168.1.0/24 subnet? The Endpoints don't need to use this address as a GW or anything, it will just create the subnet on the Leafs.
You can use any used address in the subnet (ie. .254)
Robert
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 07:46 AM
Creating a second BD for the 192.168.0 subnet makes it work - as does adding a second subnet to the EPG (noted above - looks like we crossed paths).
it's just not how the teams automating this stuff are working... but we may be able to (i.e. have to) change the way they're approaching this if that's the only way to make it work.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 07:44 AM
Thanks! I somehow missed that earlier reply.
FWIW, we have a single shared L3out that all tenants use. on each EPG, we Consume the contract interface that was Provided by the common tenant. This allows all networks within a tenant to route to each other (well, not the shared L3out, just the fabric), and allows us to selectively enable route leaking for individual EPGs. For intertenant communications, we route out via the L3out to a firewall and handle the policy there.
One other thing on the appliance issue. Do you have any thoughts on why adding a second subnet (192.168.1.254/24) to the EPG makes it all work?
For example: in the default setup, the EPG has 10.10.10.1/24 assigned and everything is great. An appliance boots up and is unreachable. we add a second subnet to the EPG with 192.168.1.254/24, and now the appliance is reachable. If we delete the subnet, the appliance is still reachable while the MAC address is in the controller's cache. Once the MAC is removed from the controller's ARP cache (whether timed out, or forcefully expunged), the appliance is again no longer reachable.
it's strange.
Really appreciate any other insights you come up with on this one.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 08:01 AM
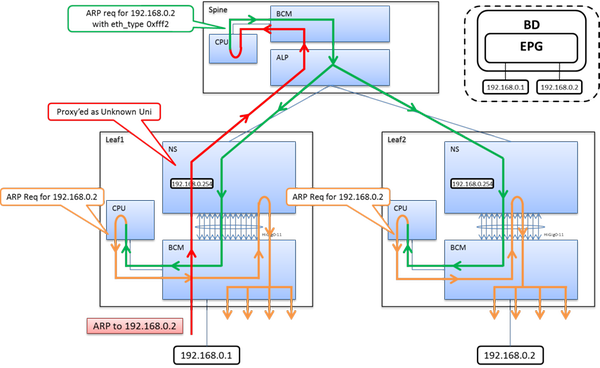
Ok, did some further research and had to confirm a few things.
When you 192.168.1.x/24 host sends his ARP, the Leaf receives it as unknown unicast - so we proxy it up to the Spine. The Spine does a looked up and sends it back to all Leaf switches with the corresponding BD. When the Leaf receives this packet it does a subnet lookup - If the Leaf & BD does not have the subnet defined we drop it. This is a security mechanism to stop ARP DDoS attacks in a way.
If the Leaf & BD have the subnet configured, it will forward (flood) the packet to all ports under within the BD.
So contrary do my initial advice - your secondary subnet does indeed need to be defined within the BD.
Here's the two scenarios to help you understand.
ARP to BD Endpoint without Subnet IP Defined
ARP to BD Endpoint with Subnet IP Defined
Robert
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 12:56 PM
This seems to explain the behaviour that we are seeing, so at least it's expected behaviour and not something we're doing wrong.
it sounds like the options at this point are:
1.) get the "silent" VM to not be silent. create *some* sort of network activity at first boot.
2.) add a secondary subnet to the EPG(s) where this capability is required.
I guess we could add
3.) create a separate BD with no Layer 3 unicast routing and do all the prep work there, then move the appliance VMs to the correct EPG after initial configuration (through automation).
Thanks for all your help Robert!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2016 07:21 AM
The route leak between L3 VRFs is driven by the contract relationship between two EPGs (each residing under a different VRF). Given that there could be multiple EPGs (class IDs) under same BD, to ensure proper contract enforcement the subnet for provider EPG is configured under EPG so that we can carry the class ID for that EPG along with the subnet when route leak takes place. If you're not using shared services (leaking) then just stick with the BD subnet config.
Use the following as a guide:
1. Define subnets under EPG with "shared" option if you want to route leak to other Tenants in fabric.
2. Define subnets under BD with "public" option if you want to share with a L3 out.
3. Define subnets under BD with "private" option if you want them to only be used in that Tenant.
Robert
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide

