- Cisco Community
- Comunidad de Cisco
- Networking (antes R&S)
- Documentos Routing y Switching
- Introducción a MPLS
- Suscribirse a un feed RSS
- Marcar como nuevo
- Marcar como leída
- Favorito
- Suscribir
- Página de impresión sencilla
- Informe de contenido inapropiado
- Suscribirse a un feed RSS
- Marcar como nuevo
- Marcar como leída
- Favorito
- Suscribir
- Página de impresión sencilla
- Informe de contenido inapropiado
06-28-2018 10:20 AM - editado 03-21-2019 05:43 PM
Introducción a MPLS
Un término mencionado frecuentemente que causa zumbidos en algunos oídos e intriga en otros, es MPLS. Multi Protocol Label Switching es una tecnología compleja cuyas funciones dependen de mecanismos calibrados finamente y que trabajan en conjunto, asemejándose a la mecánica interna de un reloj suizo. En este artículo tengo el propósito de presentarles esta tecnología, no para reinventar la rueda, sino para hacerla tan simple como construir torres con bloques de plástico.
Antes de entrar en el meollo de MPLS, hablemos un poco acerca de quées, de donde vino, y por qué es tan popular.
Todo comenzó en los años noventa, cuando Frame Relay, ATM e IP-over-ATM estaban siendo usados por los ISPs (Internet Service Provider por sus siglas en inglés). La razón era simple: rendimiento más alto y menor latencia. Esas fueron épocas anteriores, en las que los equipos no rebosaban de recursos y ancho de banda con en la actualidad, y cada centímetro que pudiesen ganar a favor de la mejora en el uso de los recursos era bienvenido.
El método de transporte de ATM estaba basado en circuitos virtuales que eran identificados usando un par de valores simples, llamados Virtual Paths (VPs) y Virtual Channels (VCs). Cada switch tenia que revisar el encabezado de la celda (tipo de trama de ATM con longitud fija) para determinar el siguiente salto basado en valores de VPI/VCI. El proceso de decisión de reenvío era sencillo: por cada puerto, el switch ATM mantenía una tabla con cada línea diciendo: “si una celda viene con esta combinación particular de VPI/VCI, reescribe la siguiente combinación VPI/VCI y enviala por esta interfaz”. Era la tarea de la señalización en ATM de asegurar que por un par de dispositivos finales comunicándose, esas tablas de reenvío en switches ATM adyacentes se apuntarían entre ellas de manera ordenada - la combinación VPI/VCI saliente de un switch ATM anterior coincidiría con la combinación VPI/VCI esperada por el switch ATM siguiente (o adyacente) a lo largo de todo el camino. Frame Relay usaba DLCIs (Data Link Connection Identifiers - por sus siglas en inglés) en su lugar, los cuales eran, como con los VCs de ATM, valores localmente significativos para cada router. El transporte era posible emparejando y reescribiendo valores simples entre dispositivos, en lugar de crear algún tipo de mapeo o de asociación, o incluso cambiando el formato de la trama, lo hizo muy eficiente y atractivo.
Por otro lado, IP forwarding requería que un router recibiera la trama, abriese el paquete IP y comparase la dirección IP de destino con su tabla de enrutamiento, buscando por una entrada que pareara la IP de destino en su prefijo de mayor longitud posible. Sin embargo, la primera búsqueda podría no ser suficiente. La entrada en la tabla de enrutamiento podría contener solo la dirección del siguiente salto sin información alguna de la interfaz de salida, y entonces el router tendría que realizar otra búsqueda, esta vez por la dirección del siguiente salto. Este proceso de recursión podría tomar varias repeticiones hasta que alguna entrada apuntase hacia alguna interfaz de salida específica. Luego, el router tendria que consultar la tabla ARP (o algún otro mapping de capa 3 a capa 2) para entender que dirección de capa 2 deberá ser usada cuando se reenvíe el paquete a través de un siguiente salto. Sólo después de este proceso, el router era (finalmente) capaz de enviar un paquete. Esta forma de enrutar paquetes IP fue también llamada process switching, y era la forma básica de llevar a cabo funciones de enrutamiento IP.
¿Cuál fue la diferencia entre ATM o Frame Relay y enrutamiento IP? Reenviar simplemente realizando pareos exactos entre números enteros era más fácil que realizar un conjunto de operaciones para process switching que eran intensivas para el CPU, específicamente para IP y su pareo de prefijo más largo (longest prefix matching). Además de eso, el reenvío en IP generalmente se realizaba en software, ya que la construcción de un dispositivo para realizar estas operaciones en hardware era costoso y difícil. Para ATM y Frame Relay, sus valores de dirección eran de longitudes fijas, y se podían usar directamente sin ningún cálculo adicional. Esto los hizo considerablemente más fáciles de implementar en hardware y el proceso de reenvío global era rápido y menos doloroso. La implementación de esas tecnologías mostró en comparación: Reducción tanto del retraso como de los cuellos de botella en el CPU y sin procesos largos.
Hubo intentos de casar IP y ATM, y así fue como IP-over-ATM subió al escenario. Era ambicioso y prometedor, pero entrelazar dos protocolos que se encontraban en polos opuestos (cada uno tenía su propio stack) se volvió complejo. Más temprano que tarde, las restricciones de escalabilidad y la complicada interoperabilidad lo convirtieron en un desafío, y todo estaba sucediendo mientras el tiempo se les iba y la industria necesitaba una solución.
Varias soluciones fueron concebidas por diferentes fabricantes en los años siguientes, llamadas multilayer switching, que funcionan de forma similar a la predecesora que intentaban suceder. Pero ninguno de ellos fue capaz de alcanzar ese hito.
En 1997, la IETF decidió comenzar un grupo de trabajo para crear un estándar interoperable de multilayer switching. Fue creado empleando una idea astuta que se vio prometedora en el pasado y estuvo implementada de una forma similar por protocolos WAN anteriores: labels!
MPLS rápidamente se volvió necesario y su adopción fue incrementándose con el tiempo, hasta el dia de hoy, cuando es el estandard de facto para los proveedores de servicio. Hoy en día, gracias a los avances en ingeniería de hardware, no hay diferencia en el desempeño entre reenvío basado en IP o en labels, ya que todo se hace en hardware, el valor tangible real yace en lo que se puede construir usando MPLS y lo que puede soportar. Su escalabilidad e interoperabilidad, junto con los servicios e infraestructuras que puedes correr encima, como L3VPNs, lo hicieron una herramienta clave para conducir a negocios y redes hacia un nuevo horizonte.
Y ahora que sabemos por qué MPLS se volvió popular... ¿Qué tal si vemos cómo funciona?
MPLS funciona de una manera similar a los marcadores en los navegadores: le dice a los routers exactamente donde buscar en la tabla de enrutamiento por un prefijo específico. Usualmente, un router debe realizar una búsqueda línea por línea en su tabla de enrutamiento por una entrada específica para asi poder reenviar/enrutar apropiadamente un paquete, pero, ¿y si se pudiese evitar que este esfuerzo suceda más de lo necesario? ¿Y si un marcador estuviese disponible? Sí! Eso es lo que hace MPLS.
Cuando un router corre MPLS, asigna un número único a cada prefijo en su tabla de enrutamiento. Ese número será un factor clave para hacer mas rápida la comunicación, ya que identifica cada prefijo individualmente. Una vez que los números son asignados, los mismos son comunicados a sus vecinos, como gritando a viva voz. El mensaje sería algo como: “El prefijo X.X.X.X está en la línea Y en mi tabla de enrutamiento, asi que si quieres usarme a mí como tu siguiente salto hacia X.X.X.X, coloca una etiqueta (label) con el número Y encima del paquete para que pueda saltar a esa línea Y inmediatamente y reenvíe el paquete más rápido”.
¿Cuál es el resultado? Todos los routers vecinos sabrán que solo necesitan usar ese número Y para ese prefijo, y los paquetes etiquetados con Y serán enrutados apropiadamente cuando sean enviados a través de ese router. El reenvío puede darse gracias a la acción de pasar un número entero (llamado label) entre dos routers. En otras palabras: cada router anuncia a sus vecinos el número de label local asignado a cada prefijo en su tabla de enrutamiento.
Ilustrando lo anterior, obtenemos lo siguiente:
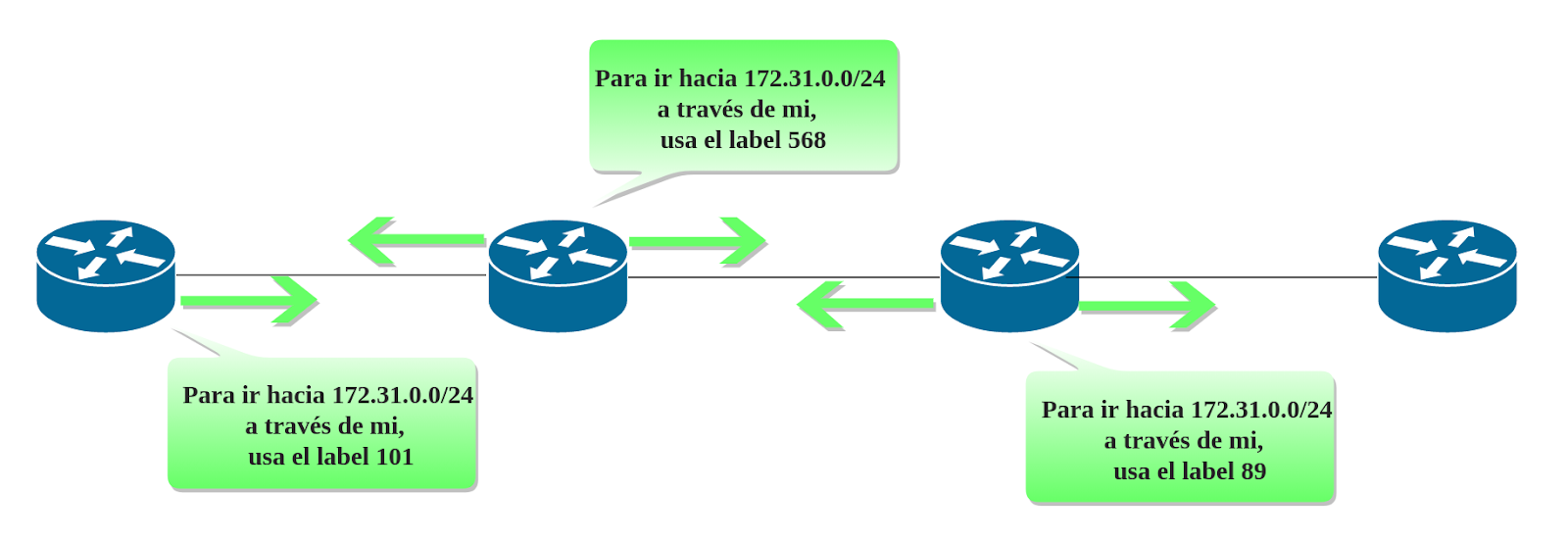
Como podemos observar, el mismo prefijo es asociado/atado a un número -localmente significativo- de label, y el mismo es anunciado a todos los vecinos indiscriminadamente.
Hasta ahora, hemos conversado sobre labels y routers anunciándose las mismas, sin mencionar como lo hacen. Existen varios protocolos capaces de anunciar labels, pero el esencial para este propósito es LDP (Label Distribution Protocol - por sus siglas en inglés).
LDP le permite a los routers establecer sesiones entre ellos, crear, anunciar y almacenar label bindings (asociaciones entre prefijos y labels), ayudando a rellenar el contenido del LIB (Label Information Base por sus siglas en inglés) y LFIB (Label Forwarding Information Base por sus siglas en inglés).
El orden aproximado de operaciones es descrito como sigue a continuación:
- Discovery de routers corriendo LDP (paquetes hello a la direccion 224.0.0.2 - UDP 646 )
- Establecimiento de sesión (TCP 646)
- Anuncio y recepción de labels
- Almacenamiento de labels en la LIB
- Construir el LFIB basado en contenidos de la LIB y RIB (similar a construir la FIB de la información de la RIB)
- Mantenimiento de la sesion (enviar keepalives, actualizaciones, y mensajes de error cuando sea necesario)
Entre sus funciones, construir la LFIB y LIB son piezas claves para minimizar el retraso en el reenvío (y para reenviar en primer lugar). Vamos a describirlas rápidamente, para que podamos tener una imagen clara de ellas:
Para definir la LIB, tenemos que recordar en qué forma los labels son anunciados, indiscriminadamente, sin prestar atención sobre que prefijo y label son anunciados y quien es o no el siguiente salto para el mismo. Cuando un router relaciona un prefijo con un número de label, esa asociación es llamada local binding para ese router. Cualquier bindingrecibido desde otro router, es llamado remote binding (porque viene de otro vecino, no es local). Entonces, en pocas palabras, con respecto a los bindings, desde la perspectiva de cada router: “lo que no es mío (local) es remoto”.
La LIB es un repositorio cuya función es almacenar redes destino/prefijos y sus respectivos bindings locales y remotos creados por un router y sus vecinos. La LIB en sí misma no es la base de datos usada para llevar a cabo decisiones de reenvío - más bien, es un almacenaje de todos los bindings conocidos del router y sus vecinos, el cual será usado luego para escoger a los candidatos apropiados y colocarlos en la LFIB.
Cuando los anuncios han sido realizados y cada router conoce y ha almacenado todas las labels, el reenvío puede ocurrir. Lo que nos falta ahora es: ¿Qué label se utiliza en cada caso? Debe haber una manera de que cada router pueda diferenciarlas.
Si jugamos un poco con las perspectivas, podrías colocarte a tí mismo encima del router y ver los labels viniendo y saliendo. Los números de label que recibes en los paquetes entrantes son tus incoming o ingress labels, y los números de label que usas para identificar los paquetes salientes son outgoing o egress labels. Esta perspectiva aplica para todos y cada uno de los routers individualmente.
Veámoslo en la figura debajo.
La manera en la que el reenvío sucede requiere conocer los bindings locales y remotos y pensar en perspectiva. Haciendo uso de LDP, los routers anuncian sus bindings locales a sus vecinos. Todos los bindings recibidos a través de LDP son almacenados como bindings remotos en la LIB. Por ejemplo: en la figura de arriba, luego de que R2 le anuncia el label 568 para 172.31.0.0/24 a R1, R1 almacenará ese binding como binding remoto en su LIB. Luego, R1 puede usar ese label cuando sea que vaya a enviar paquetes hacia 172.31.0.0/24 a través de R2. Por lo tanto, para un router, suoutgoing label (o label saliente) es el incoming label (o label entrante) de su siguiente salto, y tambien, tuoutgoing label es el label local de tu siguiente salto.
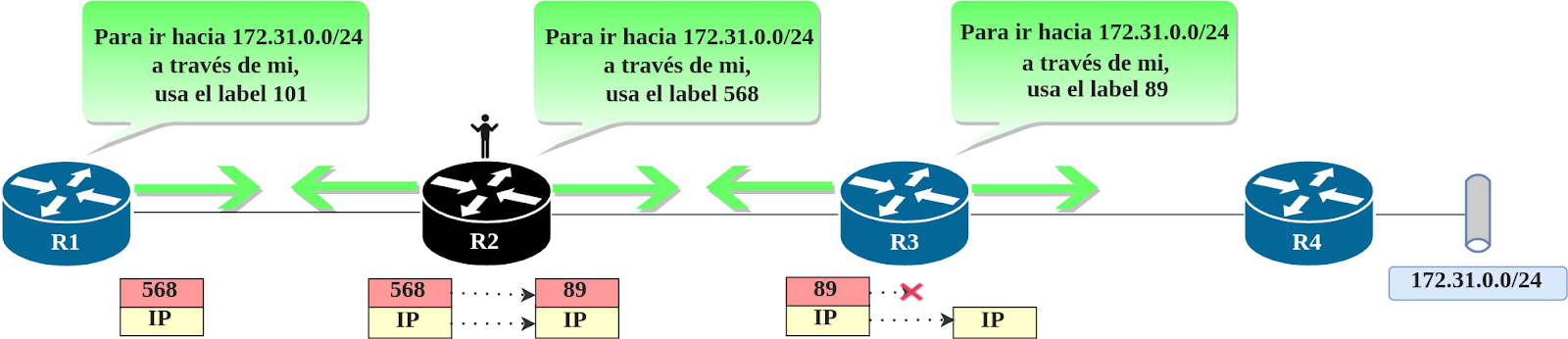
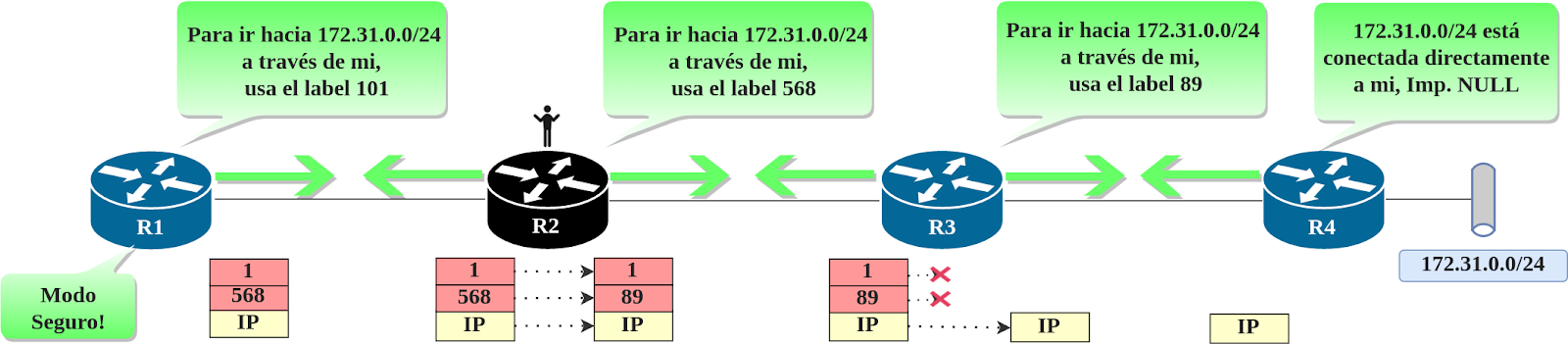
En el mismo escenario que usamos anteriormente para explicar anuncios LDP, algunos detalles nuevos han sido añadidos para ver mejor el panorama. Ahora que sabemos donde esta la red de destino y el camino que seguiremos: R1 -> R2 -> R3 -> R4.
Si te ubicas encima de R2, verás que el label local que R2 ha anunciado para 172.31.0.0/24 anteriormente (568) es el label que R1 usa para enviar los paquetes para hacia 172.31.0.0/24 a traves de R2. Ya que R2 no tiene a la red 172.31.0.0/24 conectada directamente, tiene que reenviar los paquetes a su siguiente salto, que es R3. Y como R3 ya había anunciado anteriormente que su propio label binding para 172.31.0.0/24 era 89, R2 cambiara el label entrante 568 encima de ese paquete por el label 89, y enviará el paquete reetiquetado a R3.
Podemos concluir que: los routers posteriores en el camino hacia la red destino anuncian los labels que los routers anteriores usan para enviar paquetes hacia ellos.
De manera análoga como en enrutamiento IP, no es eficiente poseer una lista enorme de redes destino y sus respectivosbindings y cuando el momento de reenviar paquetes llegue, saltar en ella como niño en una piscina de pelotas. Para hacer esa tarea más rápida y eficiente, la LFIB es construida.
Para construir la LFIB, se requiere que el router reúna y combine información de fuentes/tablas múltiples. Una entrada para una red específica en la LFIB sería creada en varios pasos. Primero, el router revisaría su tabla de enrutamiento (RIB) para buscar el siguiente salto hacia esa red. Luego, el router comprobaría en su LIB cual es el label anunciado por ese siguiente salto para ese prefijo o red destino. Y después, con esa información, y el su label entrante para ese prefijo, la entrada es construida en la LFIB. Las partes esenciales de la entrada en la LFIB serían: label entrante asignada por el router mismo, label saliente aprendida del siguiente salto, e información del siguiente salto.
Ahora que tenemos labels, tablas, estructuras y reenvío claros, ¿cuales son las operaciones requeridas para mover paquetes aquí y allá?
MPLS trabaja dependiendo de 3 procesos en cuanto a manejar paquetes se refiere, como se mencionó anteriormente, usando labels.
Esas operaciones son:
- Label Push o Imposition
- Label Swap
- Label Pop
Cuando esas operaciones son llevadas a cabo por un router, el mismo es llamado LSR (Label Switching Router - por sus siglas en inglés). Dichas funciones se explican de la siguiente manera:
Label Push: Sucede cuando un paquete llega a un LSR y el mismo empuja o impone un label encima del paquete IP u otro label, en caso de que ya tenga un label encima. Una de las situaciones donde esto ocurre, se da cuando un paquete llega a una red MPLS y será transportado a través de la misma.
Label Swap: Se realiza si un LSR recibe un paquete etiquetado y el mismo será reenviado a su siguiente salto de la misma manera (etiquetado). Como cada LSR asigna un número de label localmente significativo para cada red destino o prefijo, reenviarlos significa reemplazar el label entrante con el label saliente anunciado por el siguiente salto en elbinding remoto.
Label Pop: La operación de pop es implementada al remover el label del paquete, o en caso de que el paquete posea más de un label, remover el label superior de la pila de labels (un conjunto de labels apiladas es llamado label stack)
Si un PUSH sucede cuando un router recibe un paquete que va a atravesar la red MPLS, y un SWAP ocurre en cada salto intermediario para proveer el label del router siguiente, entonces ¿cómo sabe un LSR cuando realizar POP en los paquetes?
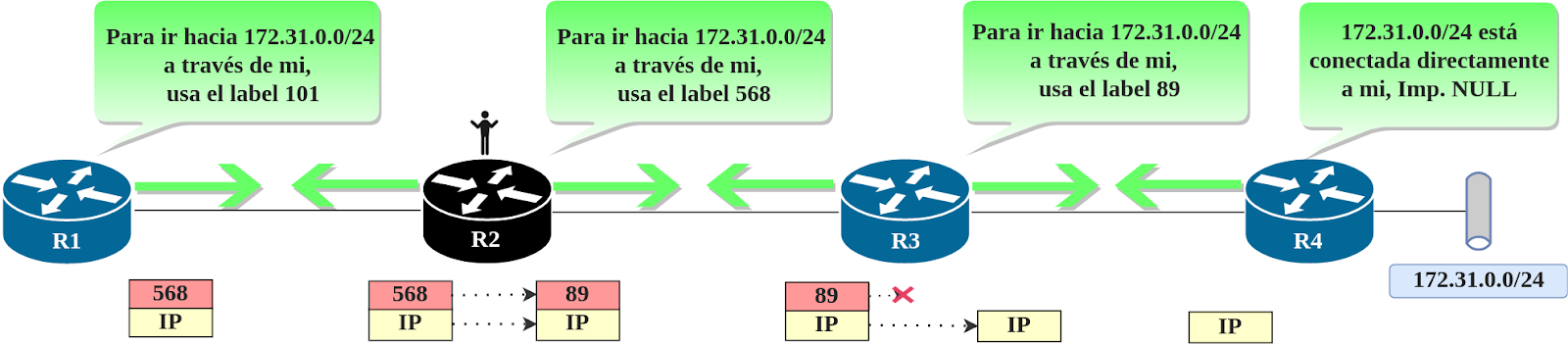
Para asegurarse de que esto suceda en el momento correcto, existe un mecanismo llamado Penultimate Hop Popping, y es implementado para remover el label del paquete un salto antes de su destino. Funciona de una manera muy astuta: el LSR que tiene la red de destino conectada directamente o sumarizada, anuncia un label binding específico para ese prefijo haciendo uso del rango reservado de labels. Veámoslo de cerca.
Entre los números usados para labels, el rango desde 0 hasta 15 está reservado, y algunos de esos números son usados por el protocolo mismo para llevar a cabo operaciones. Aunque hay varios números de label en el rango reservado, le daremos una mirada a los más usados:
Label Número 3 or Implicit NULL: Este número de label es anunciado por el router final (el que está justo antes de la red destino) para que el vecino anterior realice el POP del label del paquete antes de enviarlo. El propósito es prevenir dobles búsquedas (lookups) en el LSR final. Si un paquete etiquetado llega, el LSR tendría que realizar una búsqueda en la LFIB para darse cuenta de que el label debe ser removido, y luego, otra búsqueda, pero esta vez en el FIB (IP lookup) para encontrar la información del siguiente salto y la interfaz de salida. Si el label es removido por elpenultimate hop LSR, se evita la primera (e innecesaria) búsqueda en el LSR final.
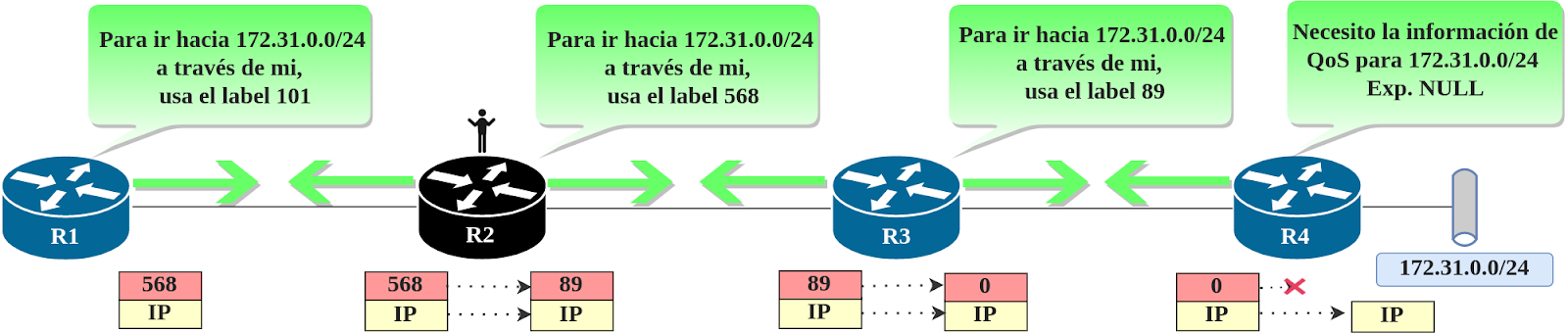
Labels Número 0 y 2 (IPv4 e IPv6) o Explicit NULL: Aunque retirar el label un salto antes ayuda a evitar una segunda búsqueda, también tiene sus desventajas. La información de QoS (Quality of Service por sus siglas en inglés) puede ser vaciada en el encabezado MPLS haciendo uso de los bits de TC (Traffic Class por sus siglas en inglés), pero, si el label es removido un salto antes, la información de QoS también se pierde. Este label se usa para evitar que ocurra el PHP (Penultimate Hop Popping). El label de explicit NULL sería anunciado por el LSR final (dependiendo de la versión de IP - 0 para IPv4 y 2 para IPv6) y el vecino anterior enviaría el paquete usando ese número. Una vez es recibido, el LSR final removerá el label implicit NULL y revisará la información de QoS para reenviar el paquete de acuerdo a la misma.
Label Número 1 o Router Alert: Este label es empleado para realizar troubleshooting en MPLS, ya que el mismo asegura que los paquetes sean enviados en modo “seguro” para garantizar su llegada al destino correspondiente.Cuando un LSR recibe un paquete con el label número 1, evitará el reenvío en hardware y será procesado por el CPU (process switched). El label número 1 no se muestra en la LFIB ya que el mismo es reenviado por software. El reenvío es un poco distinto del resto de los labels, porque el label 1 no es removido en cada salto que atraviesa. El LSR va a intercambiar los labels como usualmente se hace (haciendo uso del contenido de la LFIB) y luego el label 1 se colocara encima de los otros labels existentes antes de reenviarlo, para garantizar que será procesado por el CPU en el próximo LSR.
Hasta ahora, hemos conversado sobre paquetes etiquetados, pero no le hemos dado una mirada detallada para saber cómo luce exactamente el label MPLS y dónde está situado. Observemos de cerca ahora:
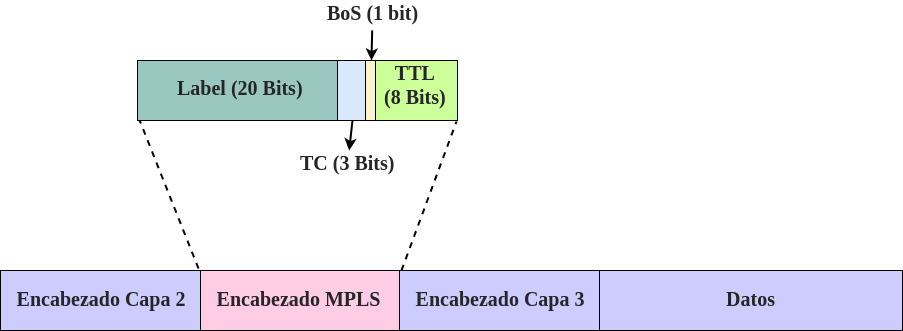
Como se representa arriba, el encabezado MPLS tiene 32 bits de largo y está justo entre los encabezados de capa 2 y capa 3 cuando el reenvío se realiza. Mirando de cerca podemos identificar los siguientes campos:
Label (20 bits): Identifica el valor del label usado por los LSRs para reenviar paquetes a través de una red MPLS. El rango de valores para este campo es <0 - 1,048,575> (220-1).
Traffic Class (3 bits): El campo Traffic Class, previamente conocido como EXP, es usado para transportar información de clases de tráfico para que las políticas de QoS puedan ser implementadas en una red MPLS al revisar el valor en el encabezado.
Bottom Of Stack (1 bit): MPLS permite que múltiples labels serán colocadas encima de un paquete. Las mismas son tratadas como un stack; el label del inferior o de fondo (bottom label) es la más cercana al encabezado de capa 3 mientra que el label superior (top label) es la más cercana al encabezado de capa 2, y los LSRs siempre operan solo con el top label (con la excepción del label de Router Alert). Para poder identificar cual label es la última - la del fondo - el bit BoStendrá el valor de 1 en el último label y 0 en el resto de ellas.
Time to Live (TTL) (8 bits): Análogo a reenvío IP, es usado para hacer seguimiento del número de saltos que un paquete etiquetado puede realizar (o el número de routers que puede atravesar en su viaje a su destino) antes de ser descartado. Usado como un mecanismo de prevención de loops. El rango de valores es <0 - 255> (28-1). Los paquetes son reenviados y una unidad es sustraída del valor actual en cada router/salto, esta operación es repetida hasta que llega a su destino o el valor llega a 0 (y es descartado).
Hasta este punto hemos discutido muchos temas relacionados con MPLS, un poco de historia y varios componentes que trabajan juntos para proveer un método de transporte cuyas aplicaciones son una característica común y atractiva hoy en dia. Este blog ha sido planeado para ser una lección introductoria en MPLS simple y así entender sus mecanismos internos. Lo artículos futuros abordarán otros escenarios más complejos y aplicaciones de este protocolo para construir una infraestructura capaz de proveer un servicio.
¡Cualquier comentario, preguntas o correcciones son bienvenidos!
Versión en inglés: MPLS History and building blocks
- Marcar como leída
- Marcar como nuevo
- Favorito
- Resaltar
- Imprimir
- Informe de contenido inapropiado
Hola @David Samuel Penaloza Seijas
Gracias por compartir tan valiosa información, estamos seguros es de gran ayuda y apoyo para los miembros de la comunidad.
- Marcar como leída
- Marcar como nuevo
- Favorito
- Resaltar
- Imprimir
- Informe de contenido inapropiado
Contento de poder colaborar :)
- Marcar como leída
- Marcar como nuevo
- Favorito
- Resaltar
- Imprimir
- Informe de contenido inapropiado
muchas felicidades por esta gran explicacion, gracias por el aporte, Slds
¡Conecte con otros expertos de Cisco y del mundo! Encuentre soluciones a sus problemas técnicos o comerciales, y aprenda compartiendo experiencias.
Queremos que su experiencia sea grata, le compartimos algunos links que le ayudarán a familiarizarse con la Comunidad de Cisco:
Navegue y encuentre contenido personalizado de la comunidad