- Cisco Community
- Technology and Support
- Networking
- Networking Knowledge Base
- vPC Auto-Recovery Feature in Nexus 7000
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-04-2012 04:36 PM - edited 03-01-2019 04:49 PM
- Introduction
- Why do we need vPC Auto-Recovery
- Configuration of vPC auto-recovery
- How does Auto-Recovery Really Work
- Should I enable vPC auto-recovery
- Reference
Introduction
vPC Auto-Recovery Feature in Nexus 7000.
Why do we need vPC Auto-Recovery
There were two main reasons for this vPC enhancement:
- In a data center outage or power outage, both vPC peers comprising of Nexus 7000 Switches are down. Occasionally, only one of the peers can be restored. Since the other Nexus 7000 is still down, vPC peer-link as well as vPC peer-keepalive link are also down. In this scenario, vPC will not come up even for the Nexus 7000 which is already up. We had to remove all vpc configurations from the port-channel on that Nexus 7000 to get the port-channel working. When the other Nexus 7000 comes up then we have to again make configuration changes to include the vpc configuration for all vPC.Starting with 5.0(2), this behavior was taken care of by configuring reload restore command under vpc domain configuration.
- For some reason vPC peer-link goes down. Since vPC peer-keepalive is still up, vPC secondary peer device brings down all its vPC member ports due to dual active detection. Hence all the traffic goes through vPC primary switch. For some reason, vPC primary switch also goes down. This will blackholed the traffic since vPC on secondary are still down because it had detected dual active detection before the vPC primary switch went down.
We merge these two enhancements together into one feature starting from 5.2(1) called vPC auto-recovery.
Configuration of vPC auto-recovery
Configuration of auto-recovery is pretty straightforward.
You just need to configure auto-recovery under vpc domain on both vPC peers
For eg:
On Switch S1
S1 (config)# vpc domain 1
S1(config-vpc-domain)# auto-recovery
S1# show vpc
Legend:
(*) - local vPC is down, forwarding via vPC peer-link
vPC domain id : 1
Peer status : peer adjacency formed ok
vPC keep-alive status : peer is alive
Configuration consistency status : success
Per-vlan consistency status : success
Type-2 consistency status : success
vPC role : primary
Number of vPCs configured : 5
Peer Gateway : Enabled
Peer gateway excluded VLANs : -
Dual-active excluded VLANs : -
Graceful Consistency Check : Enabled
Auto-recovery status : Enabled (timeout = 240 seconds)
vPC Peer-link status
---------------------------------------------------------------------
id Port Status Active vlans
-- ---- ------ --------------------------------------------------
1 Po1 up 1-112,114-120,800,810
vPC status
----------------------------------------------------------------------
id Port Status Consistency Reason Active vlans
-- ---- ------ ----------- ------ ------------
10 Po40 up success success 1-112,114-1
20,800,810
On Switch S2
S2 (config)# vpc domain 1
S2(config-vpc-domain)# auto-recovery
S2# show vpc
Legend:
(*) - local vPC is down, forwarding via vPC peer-link
vPC domain id : 1
Peer status : peer adjacency formed ok
vPC keep-alive status : peer is alive
Configuration consistency status : success
Per-vlan consistency status : success
Type-2 consistency status : success
vPC role : secondary
Number of vPCs configured : 5
Peer Gateway : Enabled
Peer gateway excluded VLANs : -
Dual-active excluded VLANs : -
Graceful Consistency Check : Enabled
Auto-recovery status : Enabled (timeout = 240 seconds)
vPC Peer-link status
---------------------------------------------------------------------
id Port Status Active vlans
-- ---- ------ --------------------------------------------------
1 Po1 up 1-112,114-120,800,810
vPC status
----------------------------------------------------------------------
id Port Status Consistency Reason Active vlans
-- ---- ------ ----------- ------ ------------
40 Po40 up success success 1-112,114-1
20,800,810
How does Auto-Recovery Really Work
We will take each behavior discussed in Why do we need vPC auto-recovery? section separately.
Assumption is that vPC auto-recovery is configured and saved to the start-up configuration on both switches S1 and S2.
1. Power outage shuts down both Nexus 7000 vPC peers simultaneously and only one switch is able to come up.
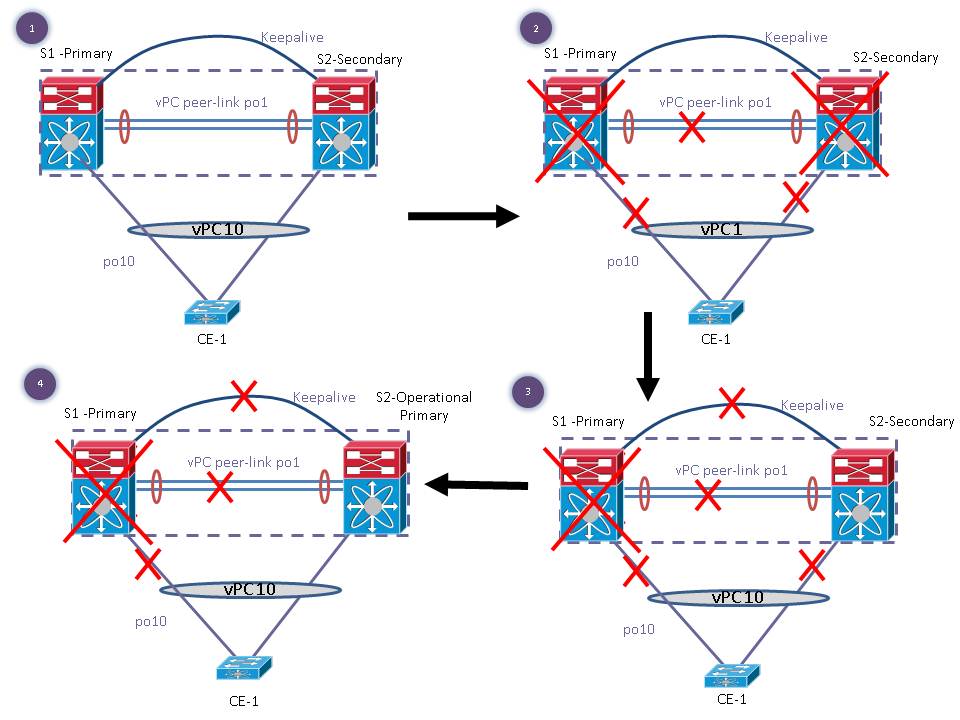
- Both S1 and S2 are power down simultaneously.
- Now only one switch is able to power up say for eg. S2 is the only switch which comes online.
- S2 will wait for vPC auto-recovery timeout (default 240 seconds which can be configured using auto-recovery reload-delay x where x is 240-3600 sec) to see if either vPC peer-link comes up or peer-keepalive status is up. If any of the above links is up (peer-link or peer-keepalive status) then auto-recovery will not get triggered.
- After the timeout if both links are still down (peer-link as well as keepalive status), vPC auto-recovery will kick in and S2 will become primary and initiate to bring up its local vPC.Since there are no peers, consistency check is bypassed.
- Now S1 comes online. At this time, S2 will retain its primary role and S1 will take secondary role, consistency checks are performed and appropriate actions are taken.
2. vPC peer-link is lost first and then primary vPC peer is power down.
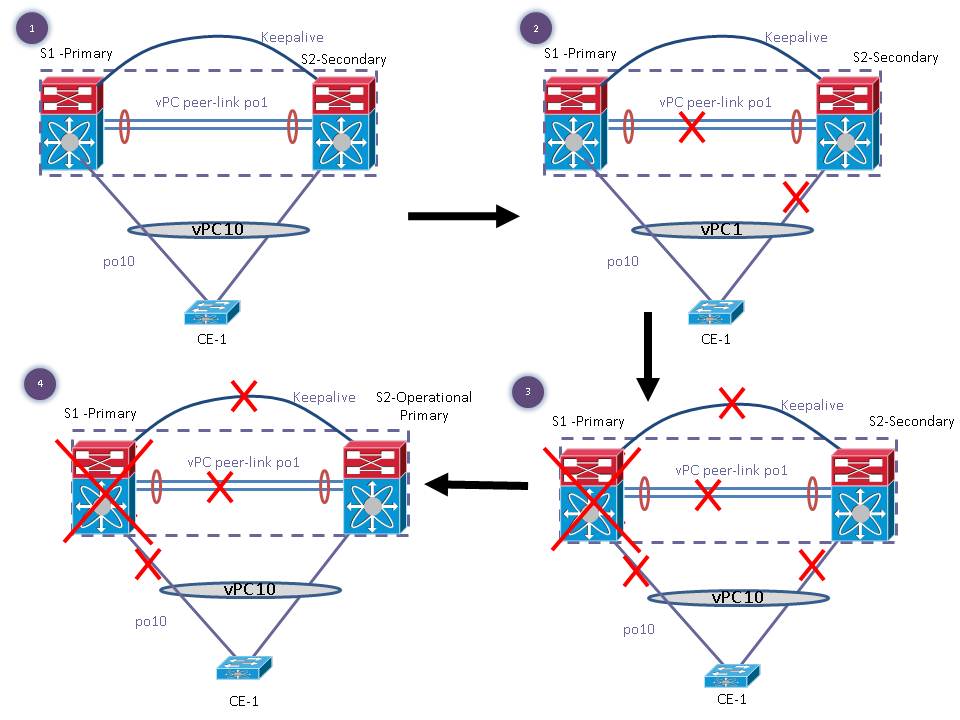
- For some reason, vPC peer-link goes down first.
- Since vPC peer-keepalive is still up, it detects dual active detection and vPC secondary S2 will bring down all its local vPC.
- Now vPC primary S1 is power down or reloads.
- This will bring down the vPC peer-keepalive link as well.
- S2 will wait for 3 consecutive peer-keepalive messages are lost. For some reason, either vPC peer-link comes up or S2 gets a peer-keepalive message, then auto-recovery does not kick in.
- However, if the peer-link remains down and we lost three consecutive peer-keepalive messages then, vpc auto-recovery will kick in.
- S2 will assume the role of primary and will bring up its local vPC bypassing consistency check.
- When S1 completes the reload, S2 will still retain its role of primary and S1 will become secondary, consistency check is performed and appropriate action is taken.
Note:
As explained in both scenario, the switch which unsuspends its vPC role using vPC auto-recovery, will continue to remain primary even after peer-link is up. The other peer will take the role of secondary and will suspends its own vPC until consistency check is done.
For eg:
S1 is powered off. S2 becomes operational primary as expected. Peer-link and keepalive and all vpc links are disconnected from S1. S1 is not powered up. Since S1 is completely isolated, it will bring the vPC up (although physical links are down) due to auto-recovery and will take the role of Primary. Now, if we connect peer-link or keepalive between S1 and S2, S1 will keep the role of primary and S2 will be come secondary. This will cause S2 to suspend its vPC until both vPC peer-link and keepalive are up as well as consistency check is done. This will cause black holing of traffic since S2 vPC is in secondary and S1 physical links are down.
Should I enable vPC auto-recovery
It is a good practice to enable auto-recovery in your vPC environment.
Although rare but there is a chance that vPC auto-recovery feature may get you in dual active scenario. For eg, if you first lost the peer-link and then you lost the keep-alive then you will have dual active scenario.
In this situation each vPC member port keeps advertising the same LACP ID as before the dual-active failure.
A vPC topology intrinsically protects from loops in case of dual-active scenarios. In the worst case, there will be duplicate frames. Despite this, as a loop prevention mechanism, each switch starts forwarding BPDUs with the same BPDU Bridge ID as prior to the vPC dual active failure.
While not intuitive, it is still possible and desirable to continue forwarding traffic from the access layer to the aggregation layer without drops for existing traffic flows, provided that the Address Resolution Protocol (ARP) tables are already populated on both Cisco Nexus 7000 Series peers for all needed hosts.
If new MAC addresses are to be learned by the ARP table, issues may arise because the ARP response from the server may always be hashed to one Cisco Nexus 7000 Series device and not the other, making it impossible for the traffic to flow correctly.
Suppose, however, that before the failure in the situation just described, traffic was equally distributed to both Cisco Nexus 7000 Series by a correct PortChannel and by Equal Cost Multipath (ECMP) configuration. In that case, serverto-server and client-to-server traffic continues with the caveat that single-attached hosts connected directly to the Cisco Nexus 7000 Series will not be able to communicate (for the lack of the peer link). Also, new MAC addresses learned on one Cisco Nexus 7000 Series cannot be learned on the peer, as this would cause flooding for the return traffic that arrives on the peer Cisco Nexus 7000 Series device.
Reference
For further details please refer to page 19 of
http://www.cisco.com/en/US/prod/collateral/switches/ps9441/ps9670/C07-572835-00_NX-OS_vPC_DG.pdf
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Very good explaination.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
We had Auto recovery on operational secondary as enabled but on Operational primary as disabled.
We ignored this part and during one of the QC test we shut down the peer-link from secondary side.
This did bring down most of the network. Still not sure what did happen there. Could you please help in understanding the behavior in this scenario.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi
If you can give more details them it may be helpful to find out what exactly went wrong.
When you shutdown the peer-link, was the peer-keepalive still active. If yes, then auto-recovery does not even kick in and by behavior, it will suspend all vpc on operational secondary.
So if you have orphan devices or devices just connected to operational secondary then outage would be expected behavior.
Viral
")
")
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
This is a really good document.
I'm deploying a 5K solution for an office desktop LAN at the moment. Each PC is plugged in to a dual homed fex. One thing that I have ofund is that in particular scenario, so when the primary goes down and the secondary is still up, the secondary would not bring the orphan ports back online. I have had to enter the vpc orphan port suspend command to allow them to come back online. It seems counter intuitive. Any ideas why it would behave like that?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks.
Auto-recovery is going to work only for vpc port-channels.
Moreover, by default, orphan port does not get suspend when peer-link goes down. You need to have "vpc orphan-port suspend" command configured if you want to suspend orphan port when peer-link goes down.
If orphan ports are getting suspended without this configuration then it is probably a bug. You can do show run vpc all to check it out if you have it configured or not.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
thanks for this ,excellent and very useful.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
"For eg, if you first lost the peer-link and then you lost the keep-alive then you will have dual active scenario." Thinks this statement is wrong in "Should I enable vPC auto-recovery " section because the dual active scenario occurs first the keepalive to be down and then next the peer-link.
Regards,
Ganapareddy Sudhakar
9989050050
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community:
