- Cisco Community
- Technology and Support
- Data Center and Cloud
- Application Centric Infrastructure
- Re: endpoint timeout
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
")

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-18-2017 02:15 AM - edited 03-01-2019 05:24 AM
Hi everyone,
we have a strange issue in a ACI multi-pod environment, which hopefully is just the result of a single checkmark set wrong at some point.
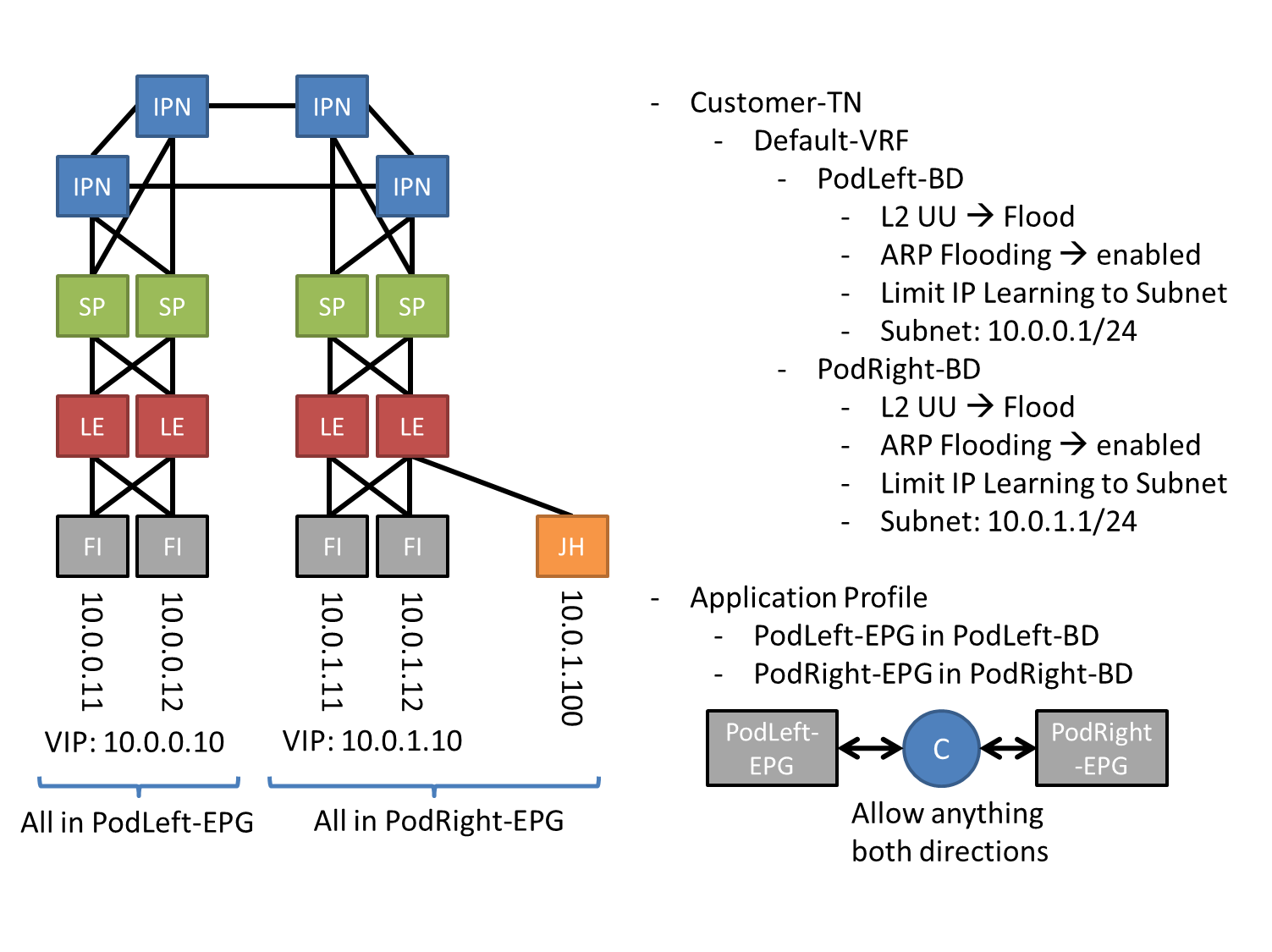
We have a pretty straightforward multi-pod environment (see attached drawing) wich connects servers across two sites (currently everything in one lab, so no latency problems or anything related to distance). Servers are managed by UCS manager and thus connect to Fabric Interconnects. FIs are attached to the fabric and we have one Bridge Domain and a corresponding EPG on each site. A contract between those EPGs allows all traffic, the fabric is default gateway for the subnets. We have a Jump Host in one Pod for several tasks.
Now after plugging everything in we can easily ping the physical FI addresses both in the same and in the remote pod. However, the VIP aka the UCS manager's address at the remote site is not pingablefrom the Jump Host. As soon as it is pinged from one of the Leaf switches that have the SVI for the subnet configured ICMP requests from the Jump Host get answered as well and everything works just fine. BUT: at some point in time the VIP is again lost from the endpoint table and we have to start over again.
This raises two questions:
- Can we avoid the first ping from the fabric (looks like some "silent host" kind of problem)
- Why does the endpoint for the VIP time out or get lost otherwise? As the answer marked as correct in this post (https://supportforums.cisco.com/t5/application-centric/aci-how-to-clear-endpoint-manually/td-p/3062011) indicates this should not happen as long as the endpoint is still reachable.
We tried several settings in the Bridge Domains, enabling and disabling flooding, limiting or not limiting learning to subnets etc.
Also this behavior didn't change after a firmware upgrade from 2.2(1n) to 3.0(2h).
Currently we have a workaround by constantly pinging all relevant addresses but this is rather unsatisfactory.
I hope someone can shed light into this mystery and as I said, I suspect a missing or wrongly done piece of configuration.
Thank you
Nik
Solved! Go to Solution.
- Labels:
-
Cisco ACI
Accepted Solutions

")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-18-2017 11:20 PM
Hi Nik,
I can think of two scenarios where we might see this issue:
1) Stale remote entry on the remote leaf node(s). This could be a problem if there is a remote entry of the VIP, and pointing to the local leaf, but the local leaf haven’t relearned the VIP since it is silent. If the jump host has an arp entry for the VIP it will send a unicast packet so when the local leaf receives the unicast packet with unknonw destination it will drop it.
i recommend checking for any remote entries of the VIP on all of the remote leaf nodes by running the “show endpoint ip <ip addres of VIP>
2) There is another route on the routing table is overlapping with your BD subnet pointing somewhere else including an L3out, or maybe a route from learned from another VRF via route leaking. This could be a problem if the remote leaf is sending the traffic to another location instead of sending it to the spine proxy.
To check for overlapping you can run the “show ip route <VIP Ip address> VRF < VIP VRF>
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-18-2017 08:45 AM
Hi Nik,
Some questions:
When the jump host is unable to reach the VIP of the UCS fabrics, did you confirm that the endpoint of the VIP is not in the endpoint table of the local leaf nodes connected to the FI? What about the remote leaf?
Does the issue happens even if the jump host is on the same pod as the fabric interconnecteds?
Have you verify that the VIP is not moving between UCS fabrics constantly? (This should not happen in normal situations). In the UCS you can type the “show cluster extended state” to figure out which fabric is the primary fabric
Have you try clearing the arp table of the jump host when the issue is happening, and does this make any difference when trying to reach the VIP.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-18-2017 10:37 PM
Hi Manuel,
I didn't look at the endpoint table on any specific leaf but the EPG operational tab doesn't show the VIP until we ping it, while the physical IPs of the FIs show up right away.
Yes it does happen even if all devices are in the same pod.
The VIP is not flapping.
No, I haven't tried clearing the ARP cache.
I'll check endpoint tables and ARP cache next time the issue returns. "Luckily" I shouldn't have to wait too long before I get that chance.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-18-2017 11:20 PM
Hi Nik,
I can think of two scenarios where we might see this issue:
1) Stale remote entry on the remote leaf node(s). This could be a problem if there is a remote entry of the VIP, and pointing to the local leaf, but the local leaf haven’t relearned the VIP since it is silent. If the jump host has an arp entry for the VIP it will send a unicast packet so when the local leaf receives the unicast packet with unknonw destination it will drop it.
i recommend checking for any remote entries of the VIP on all of the remote leaf nodes by running the “show endpoint ip <ip addres of VIP>
2) There is another route on the routing table is overlapping with your BD subnet pointing somewhere else including an L3out, or maybe a route from learned from another VRF via route leaking. This could be a problem if the remote leaf is sending the traffic to another location instead of sending it to the spine proxy.
To check for overlapping you can run the “show ip route <VIP Ip address> VRF < VIP VRF>
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-26-2017 10:57 PM
Hi Manuel,
I think you got it right with your second scenario. Turned out we had a /23 overlapping a /25 subnet for a migration period. Now that we've fixed it everything seems to work smoothly as expected.
Thank you very much!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-26-2017 11:02 PM
Hi Nik,
I am glad this issue is now resolved
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-02-2018 11:25 PM
Bad news,
the issue - or at least a highly related one - returned 😞
My server colleagues spun up a "HyperFlex Storage Controller VM" with a new IP in PodLeft. This IP has never been known to the fabric and apparently doesn't talk either, so it doesn't come up in the endpoint table of any leaf switch. Now we try to ping it from the Jump Host in PodRight to no avail. The network itself is reachable which can easily be checked by pinging another host in the same subnet.
The new address is not even pingable from any other machine within the PodLeft Subnet unless a) the gateway IP (in ACI) is pinged from the new address or b) a leaf switch hosting the gateway IP pings the new address. If this happens it turns up in the endpoint table at may then live happily ever after.
Something that looks fishy from my point of view is that this HyperFley thingy it now has two interfaces on the same subnet:
root@SpringpathController1234:~# ifconfig eth0 inet addr:10.0.0.82 Bcast:10.0.0.255 Mask:255.255.255.0 eth0:mgmtip inet addr:10.0.0.40 Bcast:10.0.0.255 Mask:255.255.255.0
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-02-2018 11:55 PM
Hi Nik,
what is the BD configuration for your hyperflex endpoint?
I understand that there is some specific BD configuration that is required for hyper flex. For example, arp flooding and GARP based detection need to be enable, as well as “Limit IP learning to Subnet.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2018 02:42 AM
Hi Manuel,
thanks again for the reply!
We tried different settings but this is what we roll with for the last couple of weeks:
Type: regular
Legacy Mode: no
L2 Unknown Unicast: Flood
L3 Unknown Multicast Flooding: Flood
Multi Destination Flooding: Flood in BD
PIM: - not selected -
IGMP Policy: - none -
ARP Flooding: true
Endpoint Dataplane Learning: true
Clear Remote MAC Entries: false
Limit IP Learning To Subnet: true
End Point Retention Policy: - none -
IGMP Snoop Policy: - none -
Same settings for all Bride Domains.
GARP Based Detection is indeed disabled at the moment. Didn't notice that setting before since it's on the L3 configuration tab... I'll give that a try and come back with further information 🙂
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide


{kind=link}