- Cisco Community
- Technology and Support
- Networking
- Networking Knowledge Base
- RP Redundancy with PIM Bidir - Phantom RP
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-31-2010 05:02 AM - edited 03-01-2019 04:36 PM
Overview :
With PIM Bidirectional, all packets move on the shared tree so RP redundancy is even more important than with PIM Sparse-Mode where RP failover has only an impact on newly active streams...
Despite PIM SM, there is no point with PIM Bidir to use several RP simultaneously since RP doesn't play handle any specific load in control plane. Nevertheless, RP is ALWAYS on the data path with Bidir so RP position is important. We oftenly use several RPs for different set of groups, depending on locations. For a given group, there is only one RP active at a time. We can define one or several backup RPs.
- Principle :
The method used to provide RP redundancy for PIM Bidirectional is called phantom RP. As the name lets suppose, we use a virtual RP, i.e. the IP address advertised as RP address is not defined on any routers. We can do that with Bidir since there is no packet unicasted to the RP address; the RP is just the root of the shared tree, i.e. the address routers RPF to.
Typical approach to configure phantom RP is the following :
- define on all 'candidate' RPs a loopback interface with a subnet including the RP address
- each 'candidate' RP uses a different subnet mask length
- subnet of loopback is advertised in IGP
This way, the 'active' RP is the candidate RP advertising the route with the longest subnet mask (no matter the metric).
If the 'active' RP fails, route towards the RP address falls back to next candidate RP advertising the second longest subnet mask, and so on...
With Phantom RP, RP failover depends only on IGP convergence => RP convergence = IGP convergence
- Configuration Example :
| Primary RP | Backup RP |
|---|---|
interface Loopback0 ! interface Loopback1 | interface Loopback0 ! interface Loopback1 |
Few remarks :
* It's important the RP address is NOT the loopback address but one of the other address in the subnet defined on the loopback
* By default, OSPF advertises all loopbacks as /32 so the need of 'ip ospf network point-to-point' command to advertise the subnet mask
* We hardcode the OSPF RID to avoid any duplicate RID problem in case address of Loopback1 is the highest loopback
* There is a need to define a mapping agent for auto-rp to work (not shown here)
* BSR doesn't support yet the possibility to advertise as candidate RP an IP address which is not defined on any interface. This implies that BSR cannot be used with phantom RP. We need to use either Auto-RP or static RP.
- Outputs :
With such a config, 2 routes are available to reach the RP address :
Router#sh ip route 192.168.3.0
Routing entry for 192.168.3.0/24, 2 known subnets
Variably subnetted with 2 masks
O 192.168.3.0/30 [110/21] via 192.168.1.13, 00:10:03, Ethernet1/0
O 192.168.3.0/29 [110/11] via 192.168.1.17, 00:10:03, Ethernet2/0
Router#
We always use the longest match (/30) so all routers RPF towards primary RP :
Router#sh ip route 192.168.3.2
Routing entry for 192.168.3.0/30
Known via "ospf 1", distance 110, metric 21, type intra area
Last update from 192.168.1.13 on Ethernet1/0, 00:10:19 ago
Routing Descriptor Blocks:
* 192.168.1.13, from 192.168.2.100, 00:10:19 ago, via Ethernet1/0
Route metric is 21, traffic share count is 1
Router#
Router#sh ip rpf 192.168.3.2
RPF information for ? (192.168.3.2)
RPF interface: Ethernet1/0
RPF neighbor: ? (192.168.1.13)
RPF route/mask: 192.168.3.0/30
RPF type: unicast (ospf 1)
RPF recursion count: 0
Doing distance-preferred lookups across tables
Router#
Router#sh ip mroute 226.1.1.1
IP Multicast Routing Table
Flags: D - Dense, S - Sparse, B - Bidir Group, s - SSM Group, C - Connected,
L - Local, P - Pruned, R - RP-bit set, F - Register flag,
T - SPT-bit set, J - Join SPT, M - MSDP created entry,
X - Proxy Join Timer Running, A - Candidate for MSDP Advertisement,
U - URD, I - Received Source Specific Host Report,
Z - Multicast Tunnel, z - MDT-data group sender,
Y - Joined MDT-data group, y - Sending to MDT-data group
Outgoing interface flags: H - Hardware switched, A - Assert winner
Timers: Uptime/Expires
Interface state: Interface, Next-Hop or VCD, State/Mode
(*, 226.1.1.1), 00:05:15/00:02:58, RP 192.168.3.2, flags: B
Bidir-Upstream: Ethernet1/0, RPF nbr 192.168.1.13
Outgoing interface list:
Ethernet1/0, Bidir-Upstream/Sparse, 00:05:15/00:00:00
Serial2/0, Forward/Sparse, 00:05:15/00:02:37
Router#
- Failover example :
In the below topology, let's assume the initial forwarding is done as shown below :
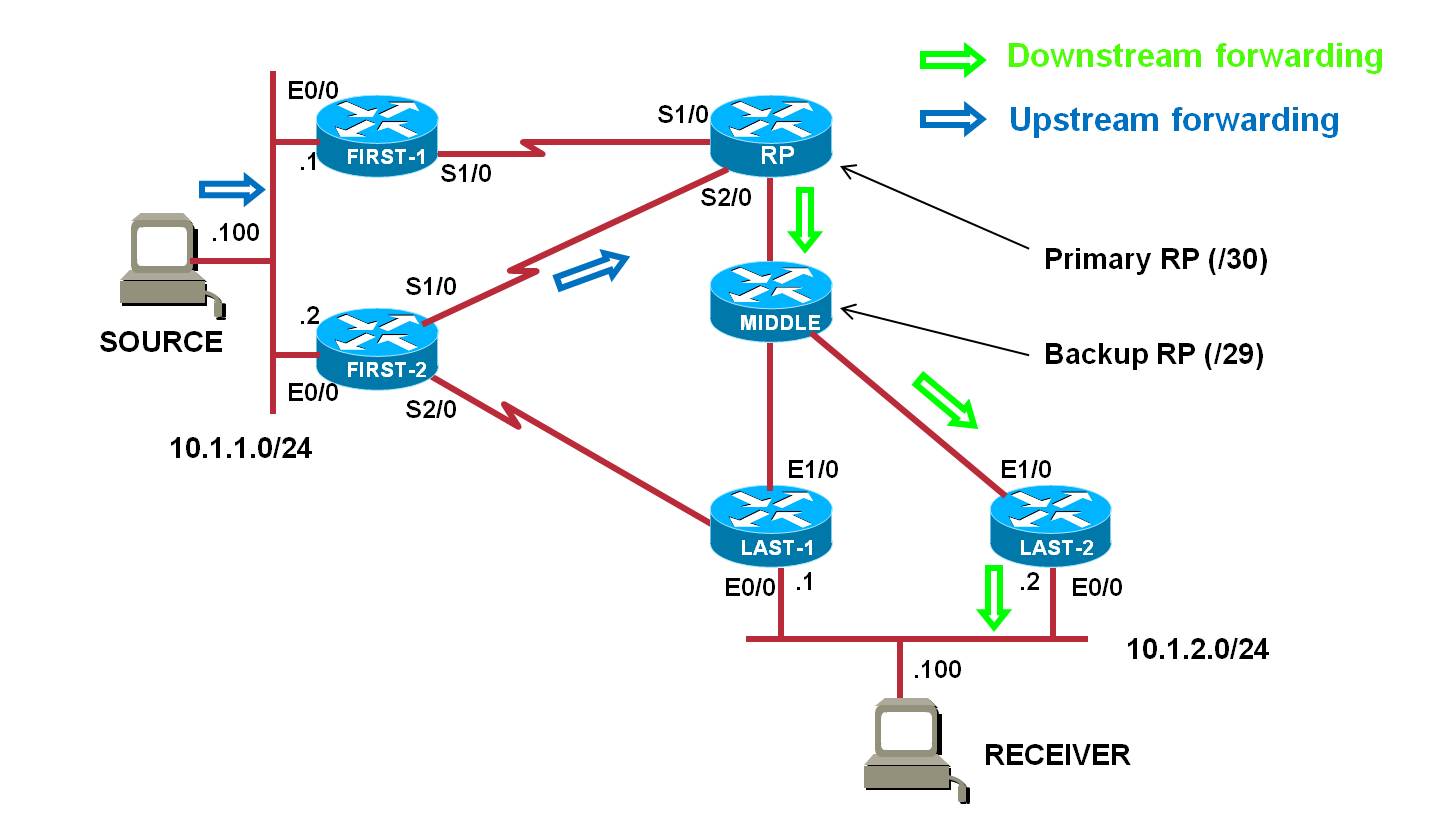
N.B. It's important to note that if RP address was loopback IP address (and not another IP in loopback subnet), the (*,G) join from Last-2 wouldn't be forwarded by Middle router towards RP since it would be destined to one of its IP address...
When primary RP fails, the /30 route gets removed once IGP has converged and RP address becomes reachable through the /29 route advertised by Middle router. All routers uses now that route to RPF to RP address.
This triggers the following changes in Distribution Tree :
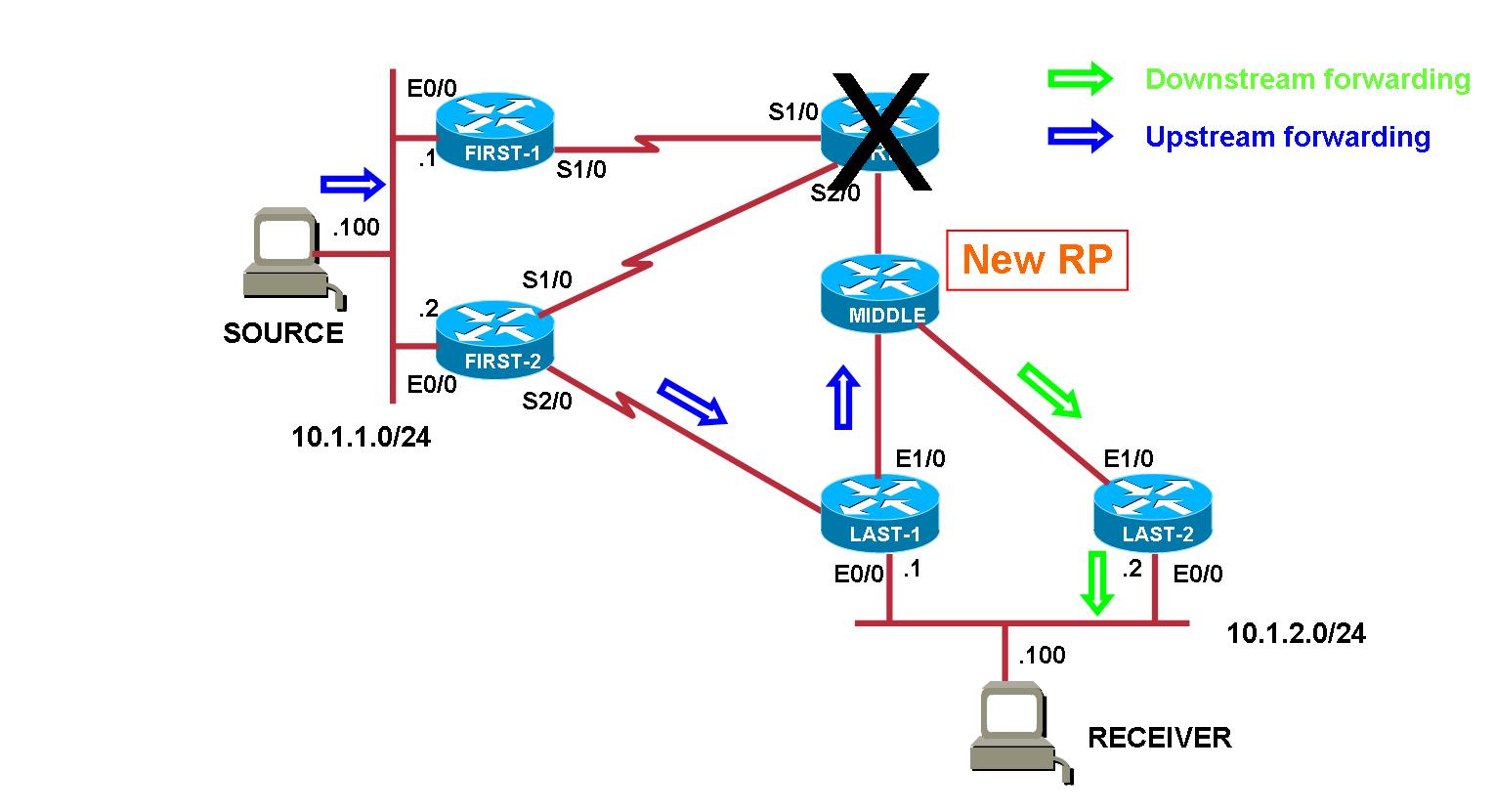
- on First-2 : Bidir-Upstream interface becomes S2/0 instead of S1/0. The stream starts to be forwarded on Serial2/0 (instead of Serial1/0)
- on Last-1 : assuming it's the DF on the serial connection towards First-2, multicast packets are accepted and forwarded on its Bidir-Upstream interface (which stays Ethernet1/0). If Last-1 was not the DF on the serial connection, a new DF election is triggered and this can add around 1 sec delay (see below).
N.B. Stream is not directly forwarded on Receiver segment because Last-1 is not the DF on that segment
- MIDDLE router is the DF on the Ethernet connection towards Last-1 so it accepts the packets and forwards the stream towards Last-2
- Last-2 accepts the stream on its Bidir-Upstream interface and forwards it towards receiver (Last-2 is the DF on the Receiver segment)
Conclusion :
RP convergence = IGP convergence + potential delay for DF election
The extra delay for DF election impacts only convergence for upstream forwarding. This delay is mainly caused by time actual DF takes before passing the role to new DF (Backoff_Period = 1 sec)

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello,
Nice article.
I'd like to know the reason why "It's important the RP address is NOT the loopback address but one of the other address in the subnet defined on the loopback". Couldn't we just use the shared address on the loopbacks? Why is that? Is it for protection, so not just anybody can send traffic to this address and maybe attempt a DoS attack??
Thanks.
Regards,
Diego
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Diego,
The answer is in the doc :
<snip>
N.B. It's important to note that if RP address was loopback IP address (and not another IP in loopback subnet), the (*,G) join from Last-2 wouldn't be forwarded by Middle router towards RP since it would be destined to one of its IP address...
<snip>
i.e. if you use the IP addr configured on loopback, it becomes a 'real' RP (not a phantom RP anymore) and it defeats the purpose...
Thx,
Fabrice
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Nice Doc 5+
quick question, in this case with auo-rp the other routers in the network still need to be configured with auto-rp listener, right ?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
auto-rp listener is indeed needed if interfaces are configured with sparse-mode only.
If configured with sparse-dense, there is no need for auto-rp listener.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
how does it work in case of mvpn ? if there is a receiver behind PE1, a source behind PE2 and RP behind PE3, how would it work ? Would we fall in the "RP on a stick" scenario ? the RP should be considered the ISP backbone, there would not be the real need to have one ... right ?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
For a deeper understanding, check this LAB demo example using Nexus switches: PIM Phantom RP Demystified: Why and How to deploy it?
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: