- Cisco Community
- Technology and Support
- Service Providers
- Service Providers Knowledge Base
- ASR9000/XR: Load-balancing architecture and characteristics
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on
08-28-2012
07:08 AM
- edited on
11-22-2022
08:23 AM
by
nkarpysh
![]()

")
Introduction
In this document it is discussed how the ASR9000 decides how to take multiple paths when it can load-balance. This includes IPv4, IPv6 and both ECMP and Bundle/LAG/Etherchannel scenarios in both L2 and L3 environments
Core Issue
The load-balancing architecture of the ASR9000 might be a bit complex due to the 2 stage forwarding the platform has. In this article the various scenarios should explain how a load-balancing decision is made so you can architect your network around it.
In this document it is assumed that you are running XR 4.1 at minimum (the XR 3.9.X will not be discussed) and where applicable XR42 enhancements are alerted.
Load-balancing Architecture and Characteristics
Characteristics
ASR9000 has the following load-balancing characteristics:
- ECMP:
- Non recursive or IGP paths : 32-way
- Recursive or BGP paths:
- 8-way for Trident
- 32 way for Typhoon
- 64 way Typhoon in XR 5.1+
- 64 way Tomahawk XR 5.3+ (Tomahawk only supported in XR 5.3.0 onwards)
- Bundle:
- 64 members per bundle
The way they tie together is shown in this simplified L3 forwarding model:
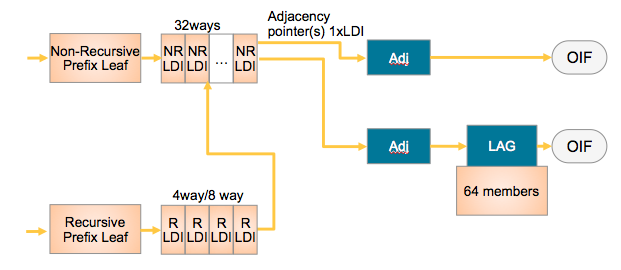
NRLDI = Non Recursive Load Distribution Index
RLDI = Recursive Load Distribution Index
ADJ = Adjancency (forwarding information)
LAG = Link Aggregation, eg Etherchannel or Bundle-Ether interface
OIF = Outgoing InterFace, eg a physical interface like G0/0/0/0 or Te0/1/0/3
What this picture shows you is that a Recursive BGP route can have 8 different paths, pointing to 32 potential IGP ways to get to that BGP next hop, and EACH of those 32 IGP paths can be a bundle which could consist of 64 members each!
Architecture
The architecture of the ASR9000 load-balancing implementation surrounds around the fact that the load-balancing decision is made on the INGRESS linecard.
This ensures that we ONLY send the traffic to that LC, path or member that is actually going to forward the traffic.
The following picture shows that:
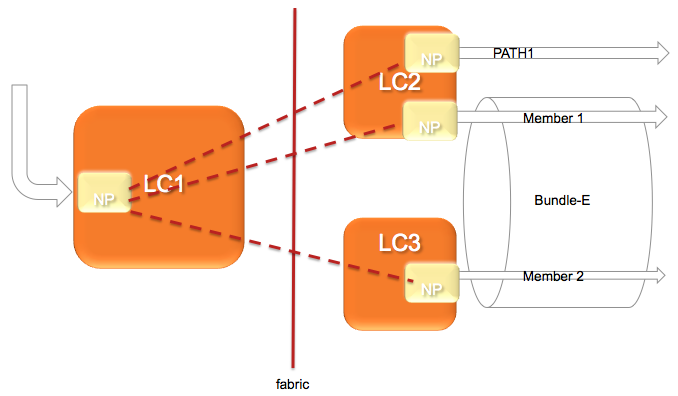
In this diagram, let's assume there are 2 paths via the PATH-1 on LC2 and a second path via a Bundle with 2 members on different linecards.
(note this is a bit extraordinary considering that equal cost paths can't be mathematically created by a 2 member bundle and a single physical interface)
The Ingress NPU on the LC1 determines based on the hash computation that PATH1 is going to forward the traffic, then traffic is sent to LC2 only.
If the ingress NPU determines that PATH2 is to be chosen, the bundle-ether, then the LAG (link aggregation) selector points directly to the member and traffic is only sent to the NP on that linecard of that member that is going to forward the traffic.
Based on the forwarding achitecture you can see that the adj points to a bundle which can have multiple members.
Allowing this model, when there are lag table udpates (members appearing/disappearing) do NOT require a FIB update at all!!!
What is a HASH and how is it computed
In order to determine which path (ECMP) or member (LAG) to choose, the system computes a hash. Certain bits out of this hash are used to identify member or path to be taken.
- Pre 4.0.x Trident used a folded XOR methodology resulting in an 8 bit hash from which bits were selected
- Post 4.0.x Trident uses a checksum based calculation resulting in a 16 bit hash value
- Post 4.2.x Trident uses a checksum based calculation resulting in a 32 bit hash value
- Typhoon 4.2.0 uses a CRC based calculation of the L3/L4 info and computes a 32 bit hash
8-way recursive means that we are using 3 bits out of that hash result
32-way non recursive means that we are using 5 bits
64 members means that we are looking at 6 bits out of that hash result
It is system defined, by load-balancing type (recursive, non-recursive or bundle member selection) which bits we are looking at for the load-balancing decision.
Fields used in ECMP HASH
What is fed into the HASH depends on the scenario:
| Incoming Traffic Type | Load-balancing Parameters |
|---|---|
| IPv4 |
Source IP, Destination IP, Source port (TCP/UDP only), Destination port (TCP/UDP only), Router ID |
| IPv6 |
Source IP, Destination IP, Source port (TCP/UDP only), Destination port (TCP/UDP only), Router ID |
| MPLS - IP Payload, with < 4 labels |
Source IP, Destination IP, Source port (TCP/UDP only), Destination port (TCP/UDP only), Router ID |
|
From 6.2.3 onwards, for Tomahawk + later ASR9K LCs: MPLS - IP Payload, with < 8 labels |
Source IP, Destination IP, Source port (TCP/UDP only), Destination port (TCP/UDP only), Router ID Typhoon LCs retain the original behaviour of supporting IP hashing for only up to 4 labels.
|
|
MPLS - IP Payload, with > 9 labels |
If 9 or more labels are present, MPLS hashing will be performed on labels 3, 4, and 5 (labels 7, 8, and 9 from 7.1.2 onwards). Typhoon LCs retain the original behaviour of supporting IP hashing for only up to 4 labels. |
| - IP Payload, with > 4 labels |
4th MPLS Label (or Inner most) and Router ID |
|
- Non-IP Payload |
Inner most MPLS Label and Router ID |
* Non IP Payload includes an Ethernet interworking, generally seen on Ethernet Attachment Circuits running VPLS/VPWS.
These have a construction of
EtherHeader-Mpls(next hop label)-Mpls(pseudowire label)-etherheader-InnerIP
In those scenarios the system will use the MPLS based case with non ip payload.
IP Payload in MPLS is a common case for IP based MPLS switching on LSR's whereby after the inner label an IP header is found directly.
Router ID
The router ID is a value taken from an interface address in the system in an order to attempt to provide some per node variation
This value is determined at boot time only and what the system is looking for is determined by:
sh arm router-ids
Example:
RP/0/RSP0/CPU0:A9K-BNG#show arm router-id
Tue Aug 28 11:51:50.291 EDT
Router-ID Interface
8.8.8.8 Loopback0
RP/0/RSP0/CPU0:A9K-BNG#
Bundle in L2 vs L3 scenarios
This section is specific to bundles. A bundle can either be an AC or attachment circuit, or it can be used to route over.
Depending on how the bundle ether is used, different hash field calculations may apply.
When the bundle ether interface has an IP address configured, then we follow the ECMP load-balancing scheme provided above.
When the bundle ether is used as an attachment circuit, that means it has the "l2transport" keyword associated with it and is used in an xconnect or bridge-domain configuration, by default L2 based balancing is used. That is Source and Destination MAC with Router ID.
If you have 2 routers on each end of the AC's, then the MAC's are not varying a lot, that is not at all, then you may want to revert to L3 based balancing which can be configured on the l2vpn configuration:
RP/0/RSP0/CPU0:A9K-BNG#configure
RP/0/RSP0/CPU0:A9K-BNG(config)#l2vpn
RP/0/RSP0/CPU0:A9K-BNG(config-l2vpn)#load-balancing flow ?
src-dst-ip Use source and destination IP addresses for hashing
src-dst-mac Use source and destination MAC addresses for hashing
Use case scenarios
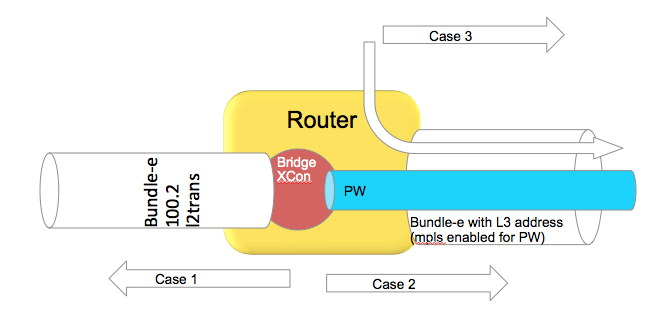
Case 1 Bundle Ether Attachment circuit (downstream)
In this case the bundle ether has a configuration similar to
interface bundle-ether 100.2 l2transport
encap dot1q 2
rewrite ingress tag pop 1 symmetric
And the associated L2VPN configuration such as:
l2vpn
bridge group BG
bridge-domain BD
interface bundle-e100.2
In the downstream direction by default we are load-balancing with the L2 information, unless the load-balancing flow src-dest-ip is configured.
Case 2 Pseudowire over Bundle Ether interface (upstream)
The attachment circuit in this case doesn't really matter, whether it is bundle or single interface.
The associated configuration for this in the L2VPN is:
l2vpn
bridge group BG
bridge-domain BD
interface bundle-e100.2
vfi MY_VFI
neighbor 1.1.1.1 pw-id 2
interface bundle-ether 200
ipv4 add 192.168.1.1 255.255.255.0
router static
address-family ipv4 unicast
1.1.1.1/32 192.168.1.2
In this case neighbor 1.1.1.1 is found via routing which appens to be egress out of our bundle Ethernet interface.
This is MPLS encapped (PW) and therefore we will use MPLS based load-balancing.
Case 3 Routing through a Bundle Ether interface
In this scenario we are just routing out the bundle Ethernet interface because our ADJ tells us so (as defined by the routing).
Config:
interface bundle-ether 200
ipv4 add 200.200.1.1 255.255.255.0
show route (OSPF inter area route)
O IA 49.1.1.0/24 [110/2] via 200.200.1.2, 2w4d, Bundle-Ether200
Even if this bundle-ether is MPLS enabled and we assign a label to get to the next hop or do label swapping, in this case
the Ether header followed by MPLS header has Directly IP Behind it.
We will be able to do L3 load-balancing in that case as per chart above.
(Layer 3) Load-balancing in MPLS scenarios
As attempted to be highlighted throughout this technote the load-balacning in MPLS scenarios, whether that be based on MPLS label or IP is dependent on the inner encapsulation.
Depicted in the diagram below, we have an Ethernet frame with IP going into a pseudo wire switched through the LSR (P router) down to the remote PE.
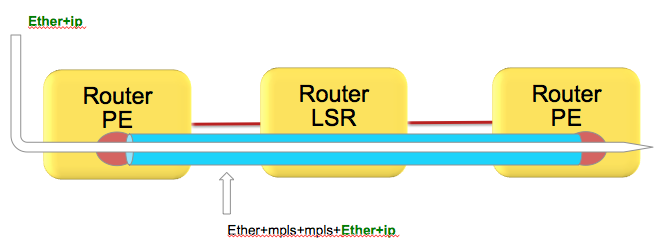
Pseudowires in this case are encapsulating the complete frame (with ether header) into mpls with an ether header for the next hop from the PE left router to the LSR in the middle.
Although the number of labels is LESS then 4. AND there is IP available, the system can't skip beyond the ether header and read the IP and therefore falls back to MPLS label based load-balancing.
How does system differentiate between an IP header after the inner most label vs non IP is explained here:
Just to recap, the MPLS header looks like this:
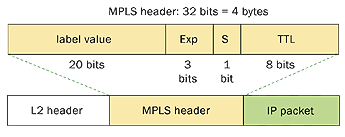
Now the important part of this picture is that this shows MPLS-IP. In the VPLS/VPWS case this "GREEN" field is likely start with Ethernet headers.
Because hardware forwarding devices are limited in the number of PPS they can handle, and this is a direct equivalent to the number of instructions that are needed to process a packet, we want to make sure we can work with a packet in the LEAST number of instructions possible.
In order to comply with that thought process, we check the first nibble following the MPLS header and if that starts with a 4 (ipv4) or a 6 (ipv6) we ASSUME that this is an IP header and we'll interpret the data following as an IP header deriving the L3 source and destination.
Now this works great in the majority scenarios, because hey let's be honest, MAC addresses for the longest time started with 00-0......
in other words not a 4 or 6 and we'd default to MPLS based balancing, something that we wanted for VPLS/VPWS.
However, these days we see mac addresses that are not starting with zero's anymore and in fact 4's or 6's are seen!
This fools the system to believe that the inner packet is IP, while it is an Ether header in reality.
There is no good way to classify an ip header with a limited number of instruction cycles that would not affect performance.
In an ideal world you'd want to use an MD5 hash and all the checks possible to make the perfect decision.
Reality is different and no one wants to pay the price for it either what it would cost to design ASICS that can do high performance without affecting the PPS rate due to a very very comprehensive check of tests.
Bottom line is that if your DMAC starts with a 4 or 6 you have a situation.
Solution
Use the MPLS control word.
Control word is negotiated end to end and inserts a special 4 bytes with zero's especially to accommodate this purpose.
The system will now read a 0 instead of a 4 or 6 and default to MPLS based balancing.
Configuration
to enable control word use the follow template:
l2vpn
pw-class CW
encapsulation mpls
control-word
!
!
xconnect group TEST
p2p TEST_PW
interface GigabitEthernet0/0/0/0
neighbor 1.1.1.1 pw-id 100
pw-class CW
!
!
!
!
Alternative solutions: Fat Pseudowire
Since you might have little control over the inner label, the PW label, and you probably want to ensure some sort of load-balancing, especially on P routers that have no knowledge over the offered service or mpls packets it transports another solution is available known as FAT Pseudowire.
FAT PW inserts a "flow label" whereby the label has a value that is computed like a hash to provide some hop by hop variation and more granular load-balancing. Special care is taken into consideration that there is variation (based on the l2vpn command, see below) and that no reserved values are generated and also don't collide with allocated label values.
Fat PW is supported starting XR 4.2.1 on both Trident and Typhoon based linecards. From 6.5.1 onward we support FAT label over PWHE.
Packet transformation with a Flow Label

Configuration of FAT Pseudowire
The following is configuration example :
l2vpn
load-balancing flow src-dst-ip
pw-class test
encapsulation mpls
load-balancing
flow-label both static
!
!
You can also affect the way that the flow label is computed:
Under L2VPN configuration, use the “load-balancing flow” configuration command to determine how the flow label is generated:
l2vpn
load-balancing flow src-dst-mac
This is the default configuration, and will cause the NP to build the flow label from the source and destination MAC addresses in each frame.
l2vpn
load-balancing flow src-dst-ip
This is the recommended configuration, and will cause the NP to build the flow label from the source and destination IP addresses in each frame.
FAT Pseudowire TLV
Flow Aware Label (FAT) PW signalled sub-tlv id is currently carrying value 0x11 as specified originally in draft draft-ietf-pwe3-fat-pw. This value has been recently corrected in the draft and should be 0x17. Value 0x17 is the flow label sub-TLV identifier assigned by IANA.
When Inter operating between XR versions 4.3.1 and earlier, with XR version 4.3.2 and later. All XR releases 4.3.1 and prior that support FAT
PW will default to value 0x11. All XR releases 4.3.2 and later default to value 0x17.
Solution:
Use the following config on XR version 4.3.2 and later to configure the sub-tlv id
pw-class <pw-name>
encapsulation mpls
load-balancing
flow-label both
flow-label code 17
NOTE: Got a lot of questions regarding the confusion about the statement of 0x11 to 0x17 change (as driven by IANA) and the config requirement for number 17 in this example.
The crux is that the flow label code is configured DECIMAL, and the IANA/DRAFT numbers mentioned are HEX.
So 0x11, the old value is 17 decimal, which indeed is very similar to 0x17 which is the new IANA assigned number. Very annoying, thank IANA
(or we could have made the knob in hex I guess )
Loadbalancing and priority configurations
In the case of VPWS or VPLS, at the ingress PE side, it’s possible to change the load-balance upstream to MPLS Core in three different ways:
1. At the L2VPN sub-configuration mode with “load-balancing flow” command with the following options:
RP/0/RSP1/CPU0:ASR9000(config-l2vpn)# load-balancing flow ?
src-dst-ip
src-dst-mac [default]
2. At the pw-class sub-configuration mode with “load-balancing” command with the following options:
RP/0/RSP1/CPU0:ASR9000(config-l2vpn-pwc-mpls-load-bal)#?
flow-label [see FAT Pseudowire section]
pw-label [per-VC load balance]
3. At the Bundle interface sub-configuration mode with “bundle load-balancing hash” command with the following options:
RP/0/RSP1/CPU0:ASR9000(config-if)#bundle load-balancing hash ? [For default, see previous sections]
dst-ip
src-ip
It’s important to not only understand these commands but also that: 1 is weaker than 2 which is weaker than 3.
Example:
l2vpn
load-balancing flow src-dst-ip
pw-class FAT
encapsulation mpls
control-word
transport-mode ethernet
load-balancing
pw-label
flow-label both static
interface Bundle-Ether1
(...)
bundle load-balancing hash dst-ip
Because of the priorities, on the egress side of the ingress PE (to the MPLS Core), we will do per-dst-ip load-balance (3).
If the bundle-specific configuration is removed, we will do per-VC load-balance (2).
If the pw-class load-balance configuration is removed, we will do per-src-dst-ip load-balance (1).
with thanks to Bruno Oliveira for this priority section
P2MP MPLS TE Tunnels
Only one bundle member will be selected to forward traffic on the P2MP MPLS TE mid-point node.
Possible alternatives that would achieve better load balancing are: a) increase the number of tunnels or b) switch to mLDP.
IPv6
Pre 4.2.0 releases, for the ipv6 hash calculation we only use the last 64 bits of the address to fold and feed that into the hash, this including the regular routerID and L4 info.
In 4.2.0 we made some further enhancements that the full IPv6 Addr is taken into consideration with L4 and router ID.
Determining load-balancing
You can determine the load-balancing on the router by using the following commands
L3/ECMP
For IP :
RP/0/RSP0/CPU0:A9K-BNG#show cef exact-route 1.1.1.1 2.2.2.2 protocol udp ?
source-port Set source port
You have the ability to only specify L3 info, or include L4 info by protocol with source and destination ports.
It is important to understand that the 9k does FLOW based hashing, that is, all packets belonging to the same flow will take the same path.
If one flow is more active or requires more bandwidth then another flow, path utilization may not be a perfect equal spread.
UNLESS you provide enough variation in L3/L4 randomness, this problem can't be alleviated and is generally seen in lab tests due the limited number of flows.
For MPLS based hashing :
RP/0/RSP0/CPU0:A9K-BNG#sh mpls forwarding exact-route label 1234 bottom-label 16000 ... location 0/1/cpu0
This command gives us the output interface chosen as a result of hashing with mpls label 16000. The bottom-label (in this case '16000') is either the VC label (in case of PW L2 traffic) or the bottom label of mpls stack (in case of mpls encapped L3 traffic with more than 4 labels). Please note that for regular mpls packets (with <= 4 labels) encapsulating an L3 packet, only IP based hashing is performed on the underlying IP packet.
Also note that the mpls hash algorithm is different for trident and typhoon. The varied the label is the better is the distribution. However, in case of trident there is a known behavior of mpls hash on bundle interfaces. If a bundle interface has an even number of member links, the mpls hash would cause only half of these links to be utlized. To get around this, you may have to configure "cef load-balancing adjust 3" command on the router. Or use odd number of member links within the bundle interface. Note that this limitation applies only to trident line cards and not typhoon.
Bundle member selection
RP/0/RSP0/CPU0:A9K-BNG#bundle-hash bundle-e 100 loc 0/0/cPU0
Calculate Bundle-Hash for L2 or L3 or sub-int based: 2/3/4 [3]: 3
Enter traffic type (1.IPv4-inbound, 2.MPLS-inbound, 3:IPv6-inbound): [1]: 1
Single SA/DA pair or range: S/R [S]:
Enter source IPv4 address [255.255.255.255]:
Enter destination IPv4 address [255.255.255.255]:
Compute destination address set for all members? [y/n]: y
Enter subnet prefix for destination address set: [32]:
Enter bundle IPv4 address [255.255.255.255]:
Enter L4 protocol ID. (Enter 0 to skip L4 data) [0]:
Invalid protocol. L4 data skipped.
Link hashed [hash_val:1] to is GigabitEthernet0/0/0/19 LON 1 ifh 0x4000580
The hash type L2 or L3 depends on whether you are using the bundle Ethernet interface as an Attachment Circuit in a Bridgedomain or VPWS crossconnect, or whether the bundle ether is used to route over (eg has an IP address configured).
Polarization
Polarization pertains mostly to ECMP scenarios and is the effect of routers in a chain making the same load-balancing decision.
The following picture tries to explain that.
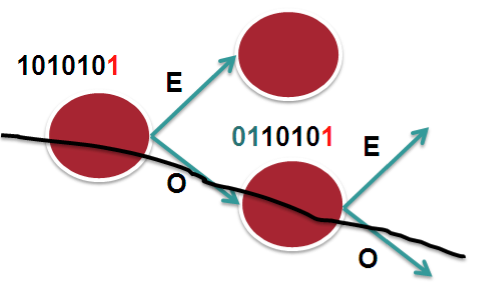
In this scenario we assume 2 bucket, 1 bit on a 7 bit hash result. Let's say that in this case we only look at bit-0. So it becomes an "EVEN" or "ODD" type decision. The routers in the chain have access to the same L3 and L4 fields, the only varying factor between them is the routerID.
In the case that we have RID's that are similar or close (which is not uncommon), the system may not provide enough variation in the hash result which eventually leads to subsequent routers to compute the same hash and therefor polarize to a "Southern" (in this example above) or "Northern" path.
In XR 4.2.1 via a SMU or in XR 4.2.3 in the baseline code, we provide a knob that allows for shifting the hash result. By choosing a different "shift" value per node, we can make the system look at a different bit (for this example), or bits.
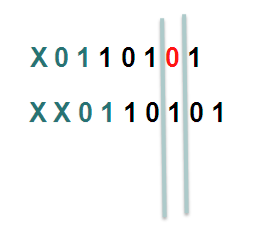
In this example the first line shifts the hash by 1, the second one shifts it by 2.
Considering that we have more buckets in the real implementation and more bits that we look at, the member or path selection can alter significantly based on the same hash but with the shifting, which is what we ultimately want.
HASH result Shifting
- Trident allows for a shift of maximum of 4 (performance reasons)
- Typhoon allows for a shift of maximum of 32.
Command
cef load-balancing algorithm adjust <value>
The command allows for values larger then 4 on Trident, if you configure values large then 4 for Trident, you will effectively use a modulo, resulting in the fact that shift of 1 is the same as a shift of 5
Fragmentation and Load-balancing
When the system detects fragmented packets, it will no longer use L4 information. The reason for that is that if L4 info were to be used, and subsequent fragments don't contain the L4 info anymore (have L3 header only!) the initial fragment and subsequent fragments produce a different hash result and potentially can take different paths resulting in out of order.
Regardless of release, regardless of hardware (ASR9K or CRS), when fragmentation is detected we only use L3 information for the hash computation.
Hashing updates
- Starting release 6.4.2, when an layer 2 interface (EFP) receives mpls encapped ip packets, the hashing algorithm if configured for src-dest-ip will pick up ip from ingress packet to create a hash. Before 6.4.2 the Hash would be based on MAC.
- Starting XR 6.5, layer 2 interfaces receiving GTP encapsulated packets will automatically pick up the TEID to generate a hash when src-dest-ip is configured.
Related Information
Xander Thuijs, CCIE #6775
Sr Tech Lead ASR9000
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander! how are you...
Let me tell about some test we did with horacio last week in connection with ospf areas and ASR9K. The topology is exact the layout. MPLS configured on all the interfaces. One H-VPLS between NPEs. OSPF as IGP, ABR running on AGGs, all links in the layout with the same cost, BGP neighbors ABRs-uPEs. High availability, same parameters in each guy, gratefull restart etc. We built pseudowires active and back-up between loopbacks so that uPE7 reach uPE8.
When we shutted down AGG-2 we experienced, I mean we had, lost of traffic for about 150 seconds! (see the log) very close the mpls hold-time set in 180s. We saw the time the back-up pseudowire becoming active improved when we remove gratefull restart and set mpls holdtime to low values. Although it was about 80 seconds, we expected this to be below one second.
In some example embodiments, when the active PW path goes down (e.g., is detected using a PW failure detection mechanism), the U-PE can immediately enable one of the backup PW paths (which are selected during configuration) and start forwarding traffic over the backup PW path with little or no signalling between the U-PE and N-PE
So, I wonder what we should do in order to improve this to subseconds. Maybe BFD on pwe? Does the release 4.2.1 or 4.3 support FFD (fast failure detection)? I mean, will it be possible configured what is supported in 15.2S described in this link or something similar for the 9K?
http://www.cisco.com/en/US/docs/ios-xml/ios/mp_l2_vpns/configuration/15-2s/wan-l2vpn-pw-red.html
"The configuration of a trigger for redundant pseudowire switchover reduces the time that it takes a large number of pseudowires to failover. A fundamental component of bidirectional forwarding detection (BFD) capability is enabled by fast-failure detection (FFD).
The configuration of this feature refers to a BFD configuration, such as the following (the second URL in the bfd map command is the loopback URL in the monitor peer bfd command):
bfd-template multi-hop mh
interval min-tx 200 min-rx 200 multiplier 3 !
bfd map ipv4 10.1.1.0/24 10.1.1.1/32 mh
"
Our test layout

uPE8 log during AGG-2 shutting down
UPE-8#
*Oct 25 21:55:53.810: %BGP-5-ADJCHANGE: neighbor 190.225.251.152 Down BGP Notification sent
*Oct 25 21:55:53.810: %BGP-3-NOTIFICATION: sent to neighbor 190.225.251.152 4/0 (hold time expired) 0 bytes
UPE-8#
*Oct 25 21:57:05.858: %LDP-5-GR: GR session 190.225.251.152:0 (inst. 1): interrupted--recovery pending
*Oct 25 21:57:05.858: %LDP-5-NBRCHG: LDP Neighbor 190.225.251.152:0 (0) is DOWN (Discovery Hello Hold Timer expired)
*Oct 25 21:57:05.862: MPLS peer 190.225.251.152 vcid 12, VC DOWN, VC state DOWN
*Oct 25 21:57:05.862: XC L2TP: Failed to find session for peer 190.225.251.152, vcid 12
*Oct 25 21:58:15.238: XC EVT[190.225.251.152:12]: Received status indication DOWN, alarm 0
*Oct 25 21:58:15.242: XC EVT[190.225.251.152:12]: FSM EV: Pri Dn, CHG from PUp,SAv to PDn,SAv,Etmr
*Oct 25 21:58:15.242: XC EVT[190.225.251.152:12]: FSM: Executing action Start Backup Enable Timer
*Oct 25 21:58:15.242: XC EVT[190.225.251.152:12]: FSM EV: Enable Tmr, CHG from PDn,SAv,Etmr to PDn,SUp
*Oct 25 21:58:15.242: XC EVT[190.225.251.152:12]: FSM: Executing action Activate Secondary Member
*Oct 25 21:58:15.242: Activating secondary member 190.225.251.151:23
*Oct 25 21:58:15.242: XC EVT[190.225.251.152:12]: Send event [Request Hot-Standby] to server
*Oct 25 21:58:15.246: XC EVT[190.225.251.152:12]: Received hot-standby complete event
*Oct 25 21:58:15.246: XC EVT[190.225.251.151:23]: Send event [Peer Status UP] to server
*Oct 25 21:58:15.250: XC EVT[190.225.251.151:23]: Received status indication UP, alarm 0
*Oct 25 21:58:15.250: XC EVT[190.225.251.151:23]: FSM EV: Sec Up, CHG from PDn,SUp to PDn,SUp
*Oct 25 21:58:15.250: XC EVT[190.225.251.151:23]: FSM: Executing action Ignore event, no action
*Oct 25 21:58:15.262: MPLS peer 190.225.251.151 vcid 23, VC UP, VC state UP
And without GR last 87 seconds:
*Oct 30 16:19:38.038: %BGP-5-ADJCHANGE: neighbor 190.225.251.152 Down BGP Notification sent
*Oct 30 16:19:38.038: %BGP-3-NOTIFICATION: sent to neighbor 190.225.251.152 4/0 (hold time expired) 0 bytes
*Oct 30 16:20:50.378: %LDP-5-NBRCHG: LDP Neighbor 190.225.251.152:0 (3) is DOWN (Discovery Hello Hold Timer expired)
*Oct 30 16:20:50.390: MPLS peer 190.225.251.152 vcid 12, VC DOWN, VC state DOWN
*Oct 30 16:20:50.390: XC L2TP: Failed to find session for peer 190.225.251.152, vcid 12
*Oct 30 16:20:50.394: XC EVT[190.225.251.152:12]: Received status indication DOWN, alarm 0
*Oct 30 16:20:50.394: XC EVT[190.225.251.152:12]: FSM EV: Pri Dn, CHG from PUp,SAv to PDn,SAv,Etmr
*Oct 30 16:20:50.394: XC EVT[190.225.251.152:12]: FSM: Executing action Start Backup Enable Timer
*Oct 30 16:20:50.394: XC EVT[190.225.251.152:12]: FSM EV: Enable Tmr, CHG from PDn,SAv,Etmr to PDn,SUp
*Oct 30 16:20:50.394: XC EVT[190.225.251.152:12]: FSM: Executing action Activate Secondary Member
*Oct 30 16:20:50.398: Activating secondary member 190.225.251.151:23
*Oct 30 16:20:50.398: XC EVT[190.225.251.152:12]: Send event [Request Hot-Standby] to server
*Oct 30 16:20:50.402: XC EVT[190.225.251.152:12]: Received hot-standby complete event
*Oct 30 16:20:50.402: XC EVT[190.225.251.151:23]: Send event [Peer Status UP] to server
*Oct 30 16:20:50.406: XC EVT[190.225.251.151:23]: Received status indication UP, alarm 0
*Oct 30 16:20:50.406: XC EVT[190.225.251.151:23]: FSM EV: Sec Up, CHG from PDn,SUp to PDn,SUp
*Oct 30 16:20:50.406: XC EVT[190.225.251.151:23]: FSM: Executing action Ignore event, no action
*Oct 30 16:20:50.418: MPLS peer 190.225.251.151 vcid 23, VC UP, VC state UP
*Oct 30 16:20:50.418: XC L2TP: Failed to find session for peer 190.225.251.151, vcid 23
*Oct 30 16:20:50.418: XC EVT[190.225.251.151:23]: Received status indication UP, alarm 0
*Oct 30 16:20:50.418: XC EVT[190.225.251.151:23]: FSM EV: Sec Up, CHG from PDn,SUp to PDn,SUp
*Oct 30 16:20:50.418: XC EVT[190.225.251.151:23]: FSM: Executing action Ignore event, no action
Best regards,
Javier
@testzone_
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Javier, good to hear from you!
Yes this convergence seems very much related to the MPLS hold time. So bascially in this scenario you want PW convergence happening and not PW re-routing if I understand correctly. BFD would help here, but we don't run BFD on targeted LDP sessions. There are some alternatives in terms of BFD running against the IGP and BGP to trigger failover scenarios a bit faster.
Any case this particular situation is a bit hard to resolve via the support forums and I would want to recommend to open a TAC case so we can investigate this and advice the best.
regards
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander!!
Continuing with the same test, when shutting down AGG-2, with GR disabled and changing some LDP parameters, the backup PW becomes active in 1,5 sec aprox.
The different LDP parameters are:
Session:
Hold time: 15 sec
Keepalive interval: 5 sec (not configured)
Discovery:
Link Hellos: Holdtime:2 sec, Interval:1 sec
Targeted Hellos: Holdtime:2 sec, Interval:1 sec
Graceful Restart:
Disabled
I think it´s difficult to reduce this time (1.5 sec) without bfd on targeted ldp sessions.
Regards.
Horacio Falcon
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Adrian,
yup this confirms that your convergence is bound to the hold time. BFD for targeted LDP I don't have a definitive roadmap on. I would want to recommend to work with the TAC to see if there are other options for your design that you can leverage and potentially work on a more definitive timeline on BFD over T-LDP if needed.
regards!!
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
I was wondering how does the FAT PW impact the scalability of the system based on the label allocation per flow? How do these labels consume internal resources? Could I face problems in regards to the number of labels available on the router for other L2/L3 VPN services?
Thanks in Advance!
Luis
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Luis,
great question, but no worries there! The flow label is merely a "dummy" label with a value computed based on inner packet info at the PE ends.
the scale limitation that many platforms have (including asr9k) are for the locally assigned labels. that is the labels that they can assign based on the locally determined paths. (see the asr9000 route scale document for more detail).
This "dummy" label, or flow label stated in a more sophisticated manner is give to the P routers so they can use that label, as most platforms used the inner most label for loadbalancing determination. Since we provide a label on a per flow basis, we can "hope" that the P router makes different decissions based on teh flow label that the Edge devices provide as part of that fat PW.
The only "overhead" is on the edge devices who have to compute and insert that new label. For P routers it is a standard operation without any overhead.
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
Excellent!
The concept of FAT PW is working pretty well in my customer and now we are getting more efficiency in the way that both residential and corporate mpls services are being transported across the MPLS Domain.
Thanks for your explanation!
Best regards,
Luis Anzola
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello,
Thanks for the great doc!
A few questions..
In all cases you describe the capabilities of the platform as a PE router
What happens in the case of ASR9K as P router?
I understand that packets of a single PW will be forwarded based on the bottom label. and that's ok if the packets already contain a flow label.
What happens if there is no flow label? Is there some kind of functionality like the "P Router Internal Load Balancing" on 7600?
Will you support different load balancing methods per bridge domain?
Currently, we can set the load balancing method (mac/ip) only under the L2VPN config, which affects all bridge domains.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
P routers follow pretty much the same model:
If it can find IP info it will use that balancing method. If there are more then 4 labels or inner is not IP then we follow the label based method.
If there is no flow label (as in fat PW), then we use effectively the PW ID label (which is the inner most) or we use IP if the first nibble after the inner label is a 4 or 6.
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
In the case of no flow label and PPPoE traffic in the payload, are you going to load balance based on mac addresses or based on the PW ID label?
Thanks
George
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
If there is PPPoE, there is first a ether header and then IP.
We don't look beyond the first header after the inner label.
However if the (dest)MAC start with a 4 or a 6, you have the issue again described above, so if you're carrying pppoe traffic you will want to use control word and use label based balancing.
A PE node may insert a flow label to hash traffic from pppoe sessions more intelligently. but that is PE capability dependent.
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi, Xander
Does ASR9K NV load balancing make a difference ? or same as standalone ASR9K ?
Thanks
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Qingyan,
loadbalancing between 2 paths (or members of a bundle) that are on a satellite are working the same way as the story above. that's easy right?
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thank you, Xander
That helps a lot !
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
If i have two Cisco ASR 9001 with bundle Ether interface ( 3 links 1 GE ) is possible also enable pim, multicast , ospf, mpls, ldp , thats correct ?. Is like Case 3 Routing through bundle , ok?
Thanks
regards
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: