- Cisco Community
- Technology and Support
- Data Center and Cloud
- Application Centric Infrastructure
- Unusual application timeouts and disconnects for servers when they are on the ACI fabric
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Unusual application timeouts and disconnects for servers when they are on the ACI fabric
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-17-2016 12:37 AM - edited 03-01-2019 05:01 AM
I have a small ACI fabric of 2 spines and 4 leaves. Our end-users are on a 3750x stack that is connected to the fabric via statically mapped EPGs and VLANs. The users and servers are all in the same EPG and Bridge Domain with no contracts needed. The users are reporting application timeouts that intermittently occur throughout the day which didn't happen before we moved the servers into ACI. If I migrate a server back out of the fabric the application timeouts do not happen again. ICMP never fails, so my pings look fine with never a lost packet or even a bit of latency.
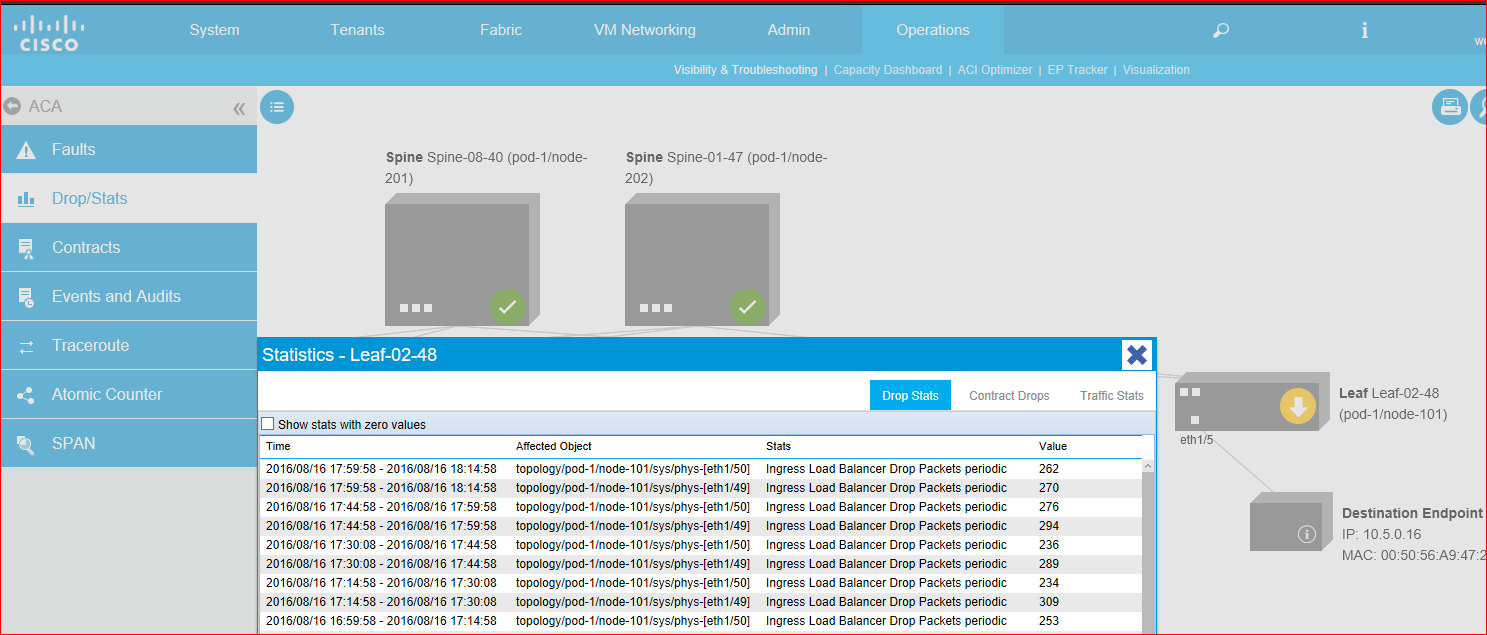
In the APIC I went to Visibility and Troubleshooting and put in two endpoints that were seeing this trouble. Under the Drop/Stats page I see that all my leaf switches have dropped packets on the 40Gb uplinks to the spine. When I drill in I see the message "Ingress Load Balancer Drop Packets periodic" followed by a counter of dropped packets. (See image below).
Does anyone know what this means and why I would be dropping packets on these fast uplinks? I have a very small pilot load on the fabric presently, so I'm hardly approaching capacity.
- Labels:
-
Cisco ACI
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-17-2016 07:17 AM
Hello!
I am not precisely sure where the drops might be coming in to play here, but lets take a look at a few things. First is, since everything is in a single BD and EPG, are multiple VLANs from the 3750 stack coming into these single BD and EPGs? Do you have any gateway (subnet) configured on your BD or is this still on the 3750/other aggregation switch/router? And the last thing is what is the configuration of your BD, specifically the forwarding behavior? Default, Flooding, ARP Flooding, etc...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-17-2016 11:55 AM
Thanks for the help.
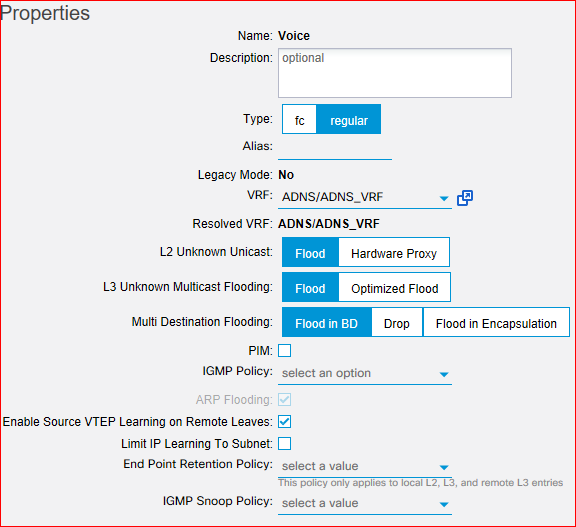
There are about 30 VLANs (each is mapped to it's own BD and EPG) between the 3750x stack and the fabric. Each BD is setup to flood unknown unicast (see picture below) since I was having issues using hardware proxy where fabric endpoints couldn't communicate with external endpoints until the external endpoint initiated the conversation.
The gateway for each VLAN is still on the 3750x.
The uplinks between the fabric and the 3750x are with two 10Gb links setup in a VPC. I just killed one interface in the VPC to force all traffic over a single link to see if that was causing the issue and I'm waiting to hear from the users.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-26-2016 05:53 AM
The users have not been having the disconnects since I manually took down one of the ports in the VPC. One other thing I did was patch the 3750x incrementally that same evening, so I'm left to wonder if it was the VPC on the APIC or the 3750x update that fixed it. I'm hesitant to put the VPC back into production because the disconnects were causing a real mess.
Before I took it down, I checked and the etherchannel on the 3750x was clean with no errors. I'm not sure how to troubleshoot the VPC on the APIC so I didn't see stats on that side.
Any pointers on how to troubleshoot this if I bring it back online during a maintenance window?
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide

