- Cisco Community
- Technology and Support
- Data Center and Cloud
- Application Networking
- Re: WAAS doesn't optimize, it stops traffic instead
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
WAAS doesn't optimize, it stops traffic instead
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2010 11:55 AM
Hi,
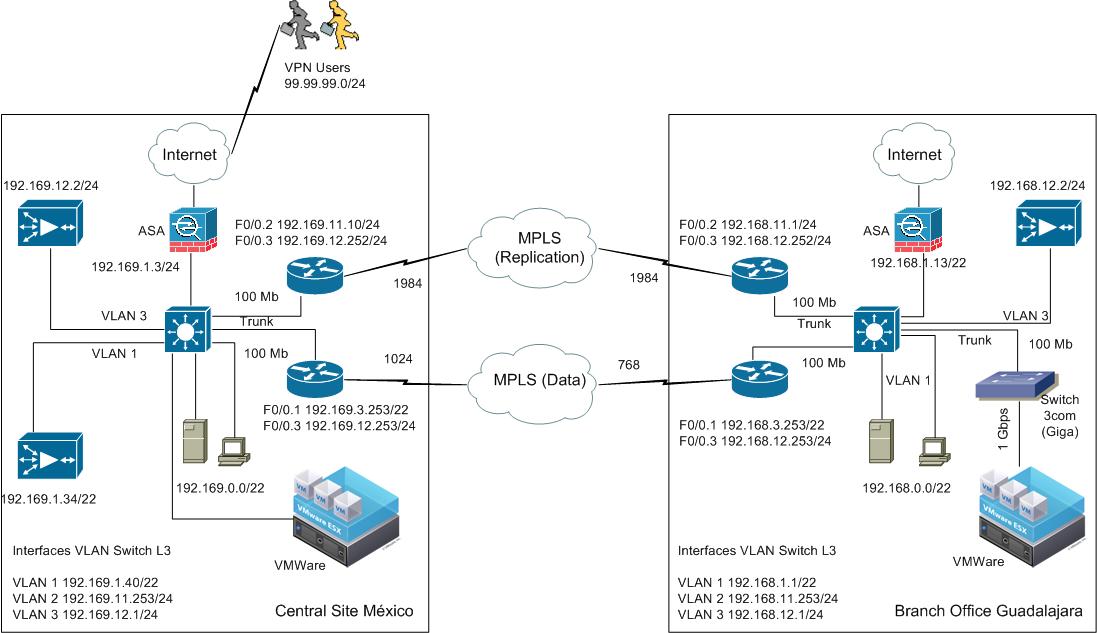
I installed WAAS in inline mode, the inline card was in shutdown state, when I apply the no shutdown command in central site we lost communication to the other sites. Originally we tried to implement WCCP (topology3) since we have two MPLS links and we need them both to be optimized but when we aplly wccp commands on the routers we also lost communication, that's why we decide to make a test with inline (topology inline).
I'm attaching routers and waas configuraction for WCCP that we removed when we made the inline test.
Any ideas why this is happening?
The WAAS version is 4.1.5c
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2010 12:10 PM
Hi,
I still see wccp being used on both edge and core wae.The wccp configuration is still active and not disabled.
Based on the router configuration the only reason why wccp failed could be the fact that the wccp redirect-list is applied only for 61 service and not 62
so on both edge and core router you need to have
ip wccp 61 redirect-list 101
and
ip wccp 62 redirect-list 101
Also if you no longer want to test wccp and only want to test inline then first disable wccp on both the edge and core wae's by entering the "no wccp version 2" command in config mode and then do a no shut to the inline group and check if it still fails
I think the wccp redirect-list issue could be the reason why the traffic was black holed when wccp was enabled.Please also try wccp with using the same redirect-list for both service 61 and 62 and see if that resolves the issue.
Regards
-Smita Nambiar
Cisco PDI HelpDesk
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2010 01:38 PM
Hi Smita,
That show run is when I was trying to use wccp, currently they don'y have any configuration of wccp, the routers don't have it eihter. we had to create that access-list (101) in order WAAS could be synchronized otherwise edge wae couldn't reach central manager, besides applpication like mail or sap or so they had delay in response time, so we had to add those servers to the access-list and they stay out of the optimization.
I used the no wccp version 2 command but when I applied the no shut command to the inline group we have no communication to the other site, so I had to shut them down again.
I'm sending the current show run of both wae.
Regards,
Alex
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2010 02:21 PM
Hi Alex,
Thank you for the confirmation that only inline interception is enabled and central site losses access when inline interception is enabled.
One thing I noted in the Core and Edge Router configuration is that you are using BGP.
In the past have seen issues with BGP where the WAE was dropping the BGP packet. This is because the WAE
counts as a hop and the packet was reaching it's max TTL
WAAS device is counted as another "hop". So, each WAAS device that the BGP communication passes through must be counted as a "hop".
Could you please increase the hop count for BGP on both edge and core router and see if the issue still occurs when you do a no-shutdown for the inline group on the wae's?
Regards
-Smita
Cisco PDI Helpdesk
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2010 02:38 PM
Hi Smita,
Thanks for your help, I will do the test tomorrow, besides the fact of the "hops" do you see anything else that I have to review? just in case that increasing the hop count doesn't work.
I'll let you know the result.
Regards,
Alex
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2010 03:01 PM
Hi Alex,
Just one other clarification I needed was are you using two wae's each at both remote and DC site or is it one wae at each site with two inline groups?
As per topology diagram I see two wae devices,but as per the sh run that you have sent me from the remote and data center wae devices, I see only the inlinegroup1/1 configured as below.
interface InlineGroup 1/1
inline vlan all
no autosense
bandwidth 100
full-duplex
shutdown
exit
but I dont see InlineGroup1/0?
Also make sure the routers and switch to which the inline group wan and lan ports are connected to are also set for 100-full speed and duplex setting
Otherwise the wae config looks fine to me.Let me know the results of testing after increasing the bgp hop count.
Regards
-Smita Nambiar
Cisco PDI Helpdesk
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-19-2010 06:32 PM
Hi Smita,
There are two wae in each location.
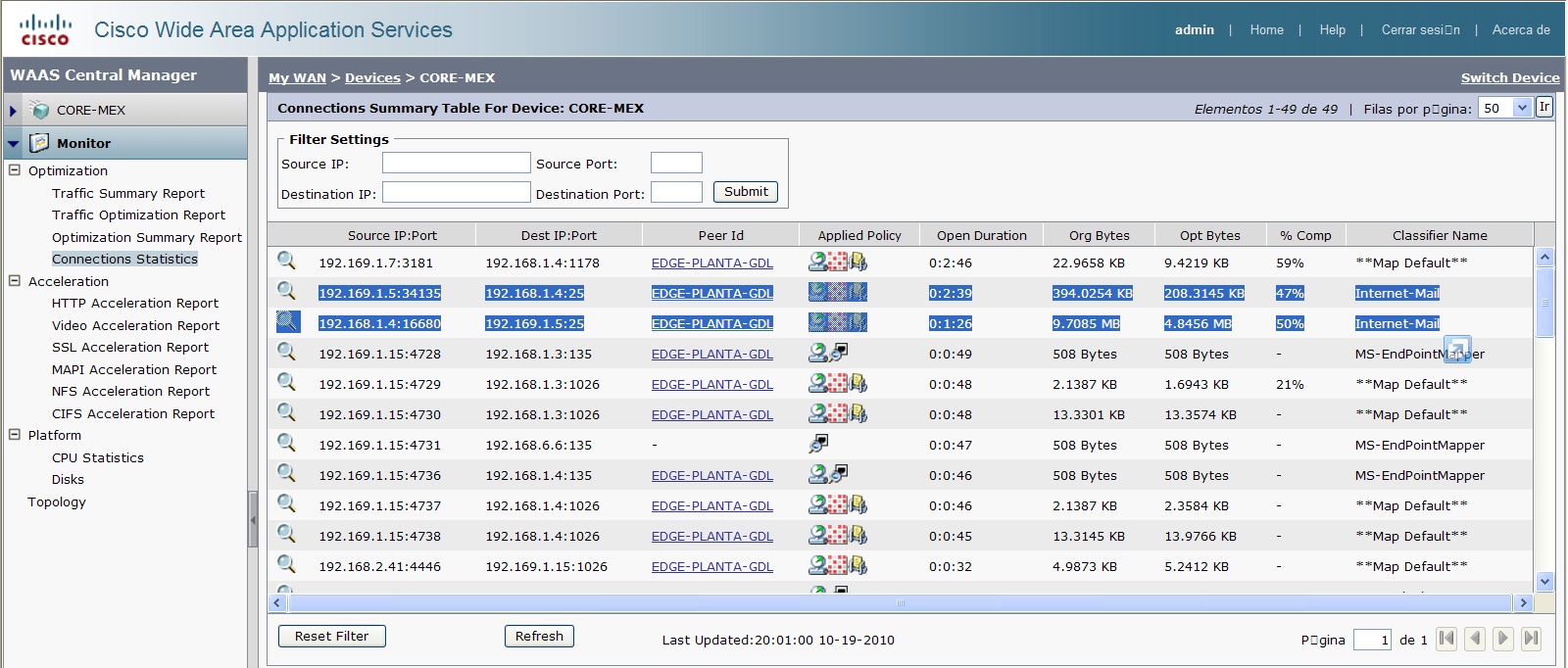
It wasn't neccesary to inrease the hop count for bgp, I could make WAAS optimize in both links but the thing now is that email delivery is too slow, users complain that they don´t get their emails from central site, and some other applications don't work, like the access to the VCenter of VMWare to manage virtual machines. I checked the connections and the reports of WAAS and it showed that there were a lot of optimized connections but the users are not happy with the result. Why the traffic is having this behavior? Any ideas?
Thank you in advance for your help.
Alex
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-19-2010 10:08 PM
Hi Alex,
Just curious how was the inline issue fixed...was it a cabling issue or something else?
Regarding the slowness for email application...can we get more information on the exact symptom?
Are users seeing duplicate emails when a single email is sent or is the client seeing any error message when sending emails or is it that just users never receive any emails?
What version of Outlook are we using?
Also are we seeing the Outlook connections being optimized on both the wae's when we enter the sh stat conn | i
What other specific application is seeing slowness? Are users seeing optimization benefit for any applications or is it all applications are slow?
If all applications are slow then we will need to check speed and duplex settings across the remote and data center sites.
When users are accessing Vmware Vcenter are we seeing the client connection to the Vcenter server on both wae's (you can use the sh stat conn | i
Following is the Release Note link which mentions WAAS 4.1.5c open caveats
http://www.cisco.com/en/US/docs/app_ntwk_services/waas/waas/v415/release/notes/ws415xrn.html#wp70844
We do have ddts CSCsy99732 related to email, but we need to make sure the symptom users are seeing is same as mentioned in the bug.This ddts is resolved in WAAS version 4.2
Also what is WAN Bandwidth and latency for this WAAS deployment?
Regards
-Smita
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2010 11:45 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2010 01:54 PM
Hi Alex,
Could you check the output of sh statistics ip output on all wae's to check if traffic is fragmented and hence dropped?
Just look for the Fragments created counter and see if the number is incrementing when the issue occurs
Also another way would be to do a ping from the central wae to remote wae and check if packets are being dropped due to fragmentation
WAE#ping -s
eg:ping -s 1460
Also please check if there could be speed duplex mismatches that can drop packets.
It will be best if we get on a webex session and get access to the set-up and troubleshoot.
Is this a POC/pre-production WAAS deployment.If yes could you please contact your Cisco Account team and have them open a pdi case(http://www.cisco.com.go/pdihelpdesk)
Regards
-Smita
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-21-2010 10:18 AM
Hi Smita,
In one of the links (replication) there is no fragmentation
EDGE-PLANTA-GDL-REP#sh statistics ip
IP statistics
-------------
Total packets in = 2479
with invalid header = 0
with invalid address = 0
forwarded = 0
unknown protocol = 0
discarded = 0
delivered = 2479
Total packets out = 2378
dropped = 0
dropped (no route) = 0
Fragments dropped after timeout = 0
Reassemblies required = 0
Packets reassembled = 0
Packets reassemble failed = 0
Fragments received = 0
Fragments failed = 0
Fragments created = 0
but in the other I got this
EDGE-PLANTA-GDL#sh statistics ip
IP statistics
-------------
Total packets in = 35287583
with invalid header = 0
with invalid address = 0
forwarded = 2
unknown protocol = 0
discarded = 0
delivered = 17578526
Total packets out = 35697204
dropped = 0
dropped (no route) = 2
Fragments dropped after timeout = 0
Reassemblies required = 484592
Packets reassembled = 242296
Packets reassemble failed = 0
Fragments received = 242287
Fragments failed = 0
Fragments created = 484574
doing the ping test I didn't see any increment in the counters. I checked the duplex and speed and forced to full and 100 in all devices routers, switches and WAEs.
This is a production deployment. I'll make other test in the replication link in about 20 min (starting at 12:45 pm Mexico time), we will send a backup of 20 Gb aprox. so if you want to make the webex sesion would be helpful
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-21-2010 04:08 PM
Hi Alex,
Since this is a production deployment.Could you please open a TAC case?
For replication traffic if you are using application accelerator mode,try just TFO+LZ policy instead of TFO DRE and LZ and check if that helps performance.
Regards
-Smita
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-25-2010 10:48 AM
Thank you Smita,
I'll continue with TAC
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide

{kind=link}
{kind=link}
{kind=link}