- Cisco Community
- Technology and Support
- Security
- Network Access Control
- ISE behind load balancer
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-08-2011 02:02 AM - edited 03-10-2019 06:37 PM
I have a question regarding ISE profiling servers that are placed behind a load balancer:
If you have a ISE environment where both computers and users are being authenticated, and Machine Access Restriction (MAR) is enabled (so users can only authenticate on a previously authenticated machine), are the ISE servers aware of all succesfull computer authentications handled by the other ISE servers?
For example:
There are 2 ISE appliances (ISE01 and ISE02) behind a load balancer.
A user starts up his computer, and computer authentication is handled by ISE01 (and the authentication is successful). At the moment the user logs in on that computer, the load balancer chooses ISE02 to authenticate the user.
Will ISE02 be aware that the corresponding computer was already succesfully authenticated on ISE01, so that the user is able to log in? Or will it deny the user authentication because it thinks the computer is not (yet) authenticated and Machine Access Restrictions is enabled?
Kind regards,
Bert
Solved! Go to Solution.
- Labels:
-
AAA
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-21-2017 07:40 PM
Thanks Laszlo,
The fragment feature was disabled on my switch, so I enabled it & disabled the minimum length as suggested by you. But the issue still persists
7010-CS01(config)# show hardware forwarding ip verify module 3 | i fra
fragment Enabled 0
7010-CS01# show hardware forwarding ip verify module 3 | i leng
length minimum Disabled --
The failure logs on ISE shows the failure reason as below
| 5411 Supplicant stopped responding to ISE | |
| Failure Reason | 12931 Supplicant stopped responding to ISE after sending it the first EAP-TLS message |
As soon as I point it to the PSN instead of the VIP it works straight away.
I have logged a TAC case for the issue.
On a side note, did you have TACACS traffic load balanced through the F5?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-21-2017 09:47 PM
I also forgot to mention, our deployment is not inline. The PSNs & the F5 are on different networks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-21-2017 09:59 PM
We only balance Radius for now.
The best thing you can do is capture traffic, that is what TAC is going to ask you also.
Capture on the client, then on F5 and ISE.(F5 has this functionality from CLI, you can capture incomming and outgoing traffic at the same time)
Then you will see where the packets are missing.
This is what we did and found the problem.
In our deployment the ISE PSN's have their gateway in the F5.
If PEAP is working then 100% that it is a fragmentation problem.
Laszlo
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-21-2017 10:10 PM
If you want send me a screnshoot of the F5 config for ISE and i can compare it to our.
laszlo
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-23-2017 12:56 AM
Hi Laszlo,
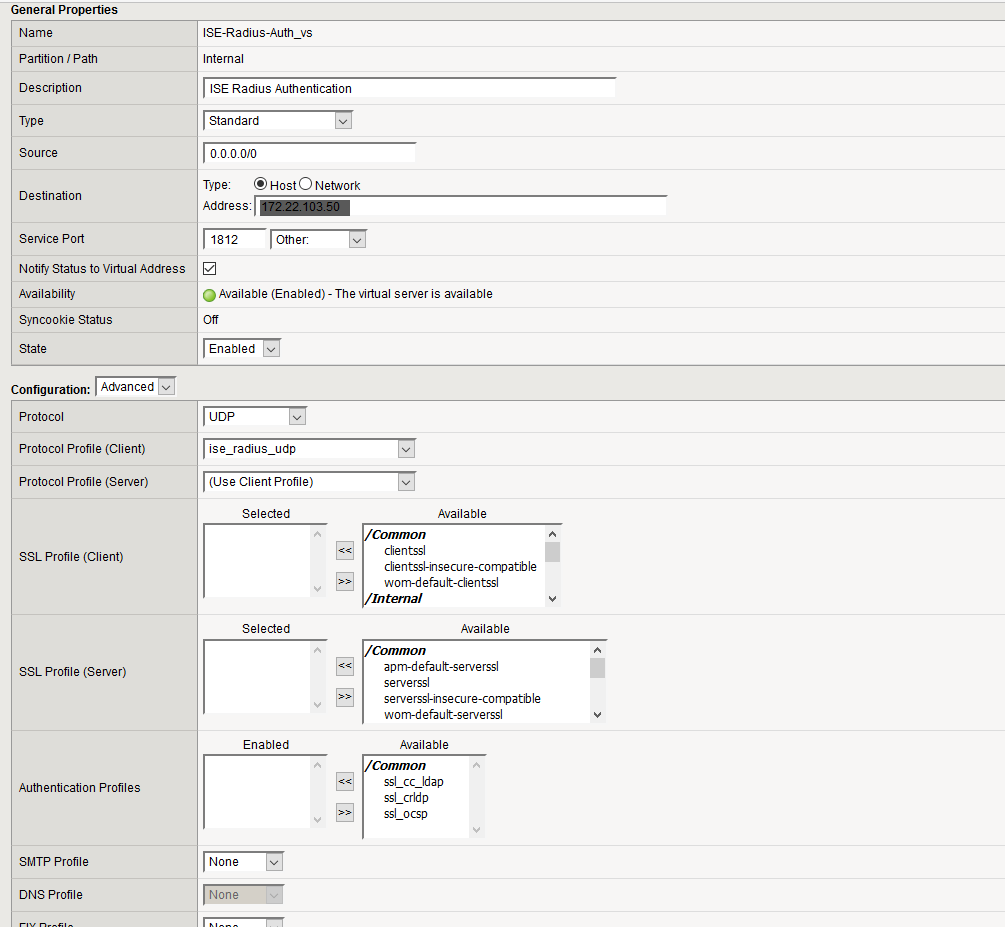
In my case the servers are on different L3 domains to the F5. So basically, the f5 is not inline with the servers which is recommended design on the guide. So, is this going to work in my setup? I would have thought it would work at least with SNAT but it doesn't. I have attached the screenshots
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-23-2017 04:00 AM
Recommend review content posted here: https://communities.cisco.com/docs/DOC-64434
More specifically, the Cisco Live session BRKSEC-3699 available on CiscoLive.com has a reference version of presentation that gets into more details than regular session presentation. Due to size, I started pulling the GUI screenshots of F5 config, but those can be found at above Community link or in session from 2016.
Assuming the LTM is reassembling fragmented UDP/RADIUS packets, then be sure to check it is not dropping fragments that are too small.
LTM: tm.minipfragsize
Pre-11.6: Default = 576 bytes
11.6.0+: Default = 566 bytes
# tmsh modify sys db tm.minipfragsize value 1
Also, if reviewed the ISE LB guide or Live session, then you should be aware that ISE does not support SNAT of traffic from the NAD if CoA is needed. This is detailed in above guides. CoA will rely on the source IP of RADIUS traffic for determining the CoA target. There is enhancement to use NAS-IP-Address so that CoA target can learn true target for CoA. Be sure to work with a Cisco team to submit customer name against feature.
I recommend review Live session on the topic of inline. It is not that it cannot be done, but that configuration increases the complexity and is often the source of issues which are more difficult to troubleshoot.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2017 12:10 AM
Hi Craig,
Thanks for sending those links.
I actually attended your session at Cisco Live in Melbourne this year!
I had a look at the slides but all the design scenarios specified in there had the F5 inline with the PSNs in one way or another. In my case, the PSNs are located at different DCs & the F5's internal network is also on a different subnet to that of the PSNs. So, it looks like the load balancing wont work unless I re-design the way the PSNs connect to the F5. I will still persevere with TAC to see what they say & advise if something comes out of it.
Regards,
Raj
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2017 02:17 AM
Node groups and local LB clusters should not extend a campus network. Sometimes customers may have dark fiber or other high-speed transport that effectively extend campus boundaries, but other than that, all members of LB cluster should typically be located in a zone where all data must pass through LB. Assymmetric flows are technically possible for some cases, but recommend avoid designing this way. If PSNs split across DCs, then split node groups and PSN clusters and assign separate VIPs to each. This is typical setup.
/Craig
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2017 08:21 PM
Hi Craig,
I agree. We do have a dark fibre between our DCs & run OSPF on our F5s.
Since most of the pool members for various services are in the core, we use auto map (SNAT) on all VIPs & this design fits our network.
Will need to think about spinning up another F5 just for the PSNs.
Thanks for all your suggestions!
Regards,
Raj
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2017 09:18 PM
SNAT for the traffic coming from NADs won't work if need CoA to work. Many of the more advanced features rely on CoA.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2017 12:22 AM
I did see that on the deployment guide.
I was just referring to our network & how we got around the limitation of the pool members being on different subnets.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2017 07:23 AM
There is no restriction on pool members being on same or different subnets.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2017 07:12 PM
Sorry, I am bit confused now.
In order for an inline deployment where the F5 is the DFGW for the PSNs wouldnt the PSN pool members need to be on the same subnet?
From the slides, what I inferred was the recommended design to load balance radius & tacacs is when the F5 is inline with the PSNs.
We have a one-arm/routed F5 deployment where PSNs are at different DCs.
So, I am assuming unless we re-design the f5 deployment, the load balancing is not going to work?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-29-2017 06:47 AM
Although a bit more tricky, there are traffic engineering techniques like PBR that can be used to force return traffic back through F5. Again, it is technically possible to bypass F5 for some flows, but it can prove problematic to troubleshoot. Expectation is that all RADIUS is returned through load balancer so that responses originate from VIP, else will be dropped by NAD.
- « Previous
-
- 1
- 2
- Next »
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide