- Cisco Community
- Technology and Support
- Data Center and Cloud
- Other Data Center Subjects
- ARP Issues with Nexus Fabric
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-28-2017 08:32 AM - edited 03-01-2019 08:31 AM
Hi,
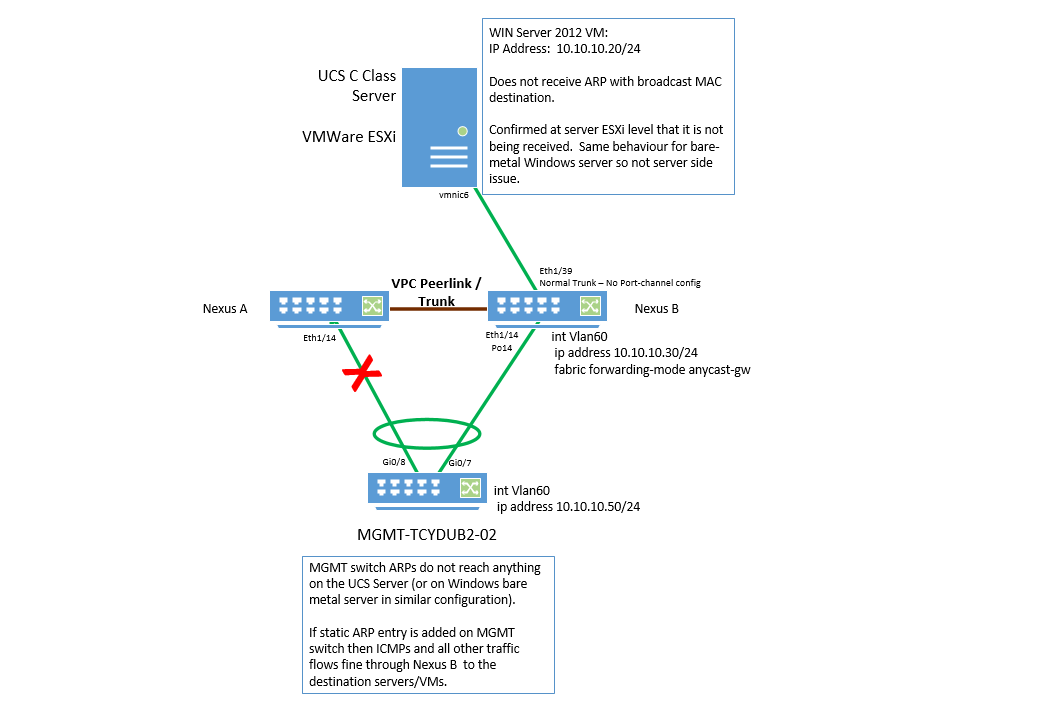
I have been experiencing some arp issues across a nexus fabric. Basically we have 2 x data centres connected via a BGP/EVPN fabric using vxlan L2/3 routing and bridging. The problem originated when connectivity issues surfaced between some bare metal database servers dual homed on a port-channel/VPC to the nexus VPC domain in DC-1 and some host VM's in DC-2 ; communicating on the same vlan/vxlan segment. Basic icmp reachability would only work by disabling one of the server links connecting to Nexus-B effectively forcing the traffic across the peer-link. Originally we suspected server problems but it turns out the same issue is there for hosts/vms on UCS. To isolate the issue we tested/recreated the problem in DC-1 between a switch and a Cisco C-Series server. The Nexus does not seem to be forwarding the arp requests out the interface towards the server. This will work by enabling 'ip local proxy-arp' on the Anycast Gateway interface but this is not optimal solution. Anyone seen any behavior like this before.
Frank
Solved! Go to Solution.
- Labels:
-
Other Data Center Topics
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-05-2017 11:17 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-28-2017 11:28 AM
hi Frank,
we faced similar issue were the N9K was dropping the ARP before it reaches CPU.
the issue was related to internal Bug and upgrade of NXOS FW resolved the issue
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-28-2017 02:50 PM
Hi Yasser, Thanks for the reply. I suspected as much.
Do you have bug id ?
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-02-2017 11:01 AM
HI Frank,
sorry for late reply :)
no i don;t have it but they recommend to upgrade to latest version available
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-04-2017 03:08 AM
Thanks Yasser.
Frank
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-05-2017 11:17 AM
Hi Frank,
did you resolve the issue ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-06-2017 05:18 AM
Hi Yasser, I did but not by code upgrade. Bouncing port-channel interfaces rectified the issue so appears to be some kind of programming bug. Ethanalyzer previously showed the arps were hitting the CPU. The problem has not surfaced since so I plan to do a scheduled reboot soon and see how things go. Very strange/rare issue so must be some undocumented bug.
Frank
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide

{kind=link}