- Cisco Community
- Technology and Support
- Data Center and Cloud
- Other Data Center Subjects
- Hx Configure issue
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-17-2018 05:02 AM - edited 03-01-2019 08:42 AM
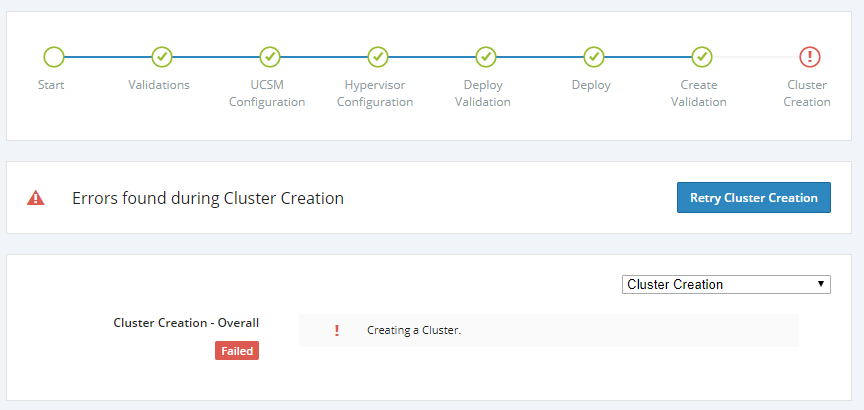
cluster create error occurred during hx configuration
last progress step Cluster Creation is fail
Cluster Creation-Overall - Creating Cluster
how to solve this problem ??
Solved! Go to Solution.
- Labels:
-
other data center topics
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-05-2018 01:37 AM
Hello Daesung,
Cluster Issues
After Cluster reregister Controller VMs not EAM Agents
Description
Controller VMs are not listed as EAM agents after stcli cluster reregister.
Action: recreate the cluster
|
Step 1 |
Delete the vCenter cluster. |
|
Step 2 |
Recreate the vCenter cluster. |
|
Step 3 |
Reregister the HX cluster. # stcli cluster reregister |
Cluster Becomes Unhealthy after Multiple Reregisters
Description
Performing multiple cluster re-registers might cause the cluster to become unhealthy.
Action: Recreate the cluster
The HX Cluster lost the vCenter information, the virtCluster and HX Connect status indicates the cluster offline. However, the HX Data Platform cluster indicates it was healthy throughout.
Recreate the cluster.
# stcli cluster recreate
ClusterNotConfigured Error after Node Removed
Description
After removing a node from a cluster, on one of the controller VMs, the stcli cluster info command lists ClusterNotConfigured.
Action: Refresh the cluster
From the controller VM command line, run:
# stcli cluster refresh
Cluster Capacity Higher than Individual Disks
Description
Total Cluster usage shown might be higher than the usage shown for individual disks.
For example, cluster usage can be 80%, yet highest utilized disk might show only 76% usage.
Action: None
The difference can be attributed to management layer handling. Use the cluster usage value to make all utilization related decisions.
Re-registering a Cluster Does Not Re-register Compute Nodes with EAM
Description
This can occur in a variety of scenarios. Possible scenarios include:
Scenario 1
- Start from an older HX version, prior to 2.1.x.
- Add a compute node.
- Re-register the cluster.
- Upgrade the cluster. Task fails to include the compute nodes.
Scenario 2
- Start from an older HX version, prior to 2.1.x.
- Add a compute node.
- Upgrade the cluster. Task completes.
- Re-register the cluster. Task fails at the EAM level.
Scenario 3
- Start with a new HX version, 2.1.x or later.
- Add a compute node.
- Re-register the cluster. Task fails at the EAM level.
Action: Remove compute nodes before re-register
|
Step 1 |
vMotion any VMs off of the compute nodes and remove the compute nodes from the HX cluster. |
|
Step 2 |
Re-register the HX cluster. |
|
Step 3 |
Add the compute nodes to the HX cluster. |
Latency Spikes Seen for Workloads with Large Working Sets
Description
Large working set workloads require accessing data from the capacity tier. As of HX Data Platform version 2.1(1b) backend access is optimized to significantly reduce the magnitude and frequency of high latency spikes.
- For hybrid clusters – When this symptom is present, the upgrade requires a longer maintenance window. Also, the default upgrade process does not automatically enable this optimization. Contact Cisco TAC to enable this performance enhancement during the upgrade process.
- For All Flash clusters - The upgrade times are not significantly affected and the default upgrade path automatically enables this performance enhancement.
Action: Upgrade to 2.1(1c) or greater
Cluster Health Status Remains Unhealthy after Rebalance
Description
In any three node cluster, including ROBO storage clusters, a single node in maintenance mode or failure causes the cluster to become unhealthy. Rebalance does not correct this.
Action: Return node to healthy state
Check that a node or component within a node is not failing. The cluster remains unhealthy as long as a component or node is failed. When the component or node returns to a healthy state, the cluster recovers and becomes healthy again.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-05-2018 01:37 AM
Hello Daesung,
Cluster Issues
After Cluster reregister Controller VMs not EAM Agents
Description
Controller VMs are not listed as EAM agents after stcli cluster reregister.
Action: recreate the cluster
|
Step 1 |
Delete the vCenter cluster. |
|
Step 2 |
Recreate the vCenter cluster. |
|
Step 3 |
Reregister the HX cluster. # stcli cluster reregister |
Cluster Becomes Unhealthy after Multiple Reregisters
Description
Performing multiple cluster re-registers might cause the cluster to become unhealthy.
Action: Recreate the cluster
The HX Cluster lost the vCenter information, the virtCluster and HX Connect status indicates the cluster offline. However, the HX Data Platform cluster indicates it was healthy throughout.
Recreate the cluster.
# stcli cluster recreate
ClusterNotConfigured Error after Node Removed
Description
After removing a node from a cluster, on one of the controller VMs, the stcli cluster info command lists ClusterNotConfigured.
Action: Refresh the cluster
From the controller VM command line, run:
# stcli cluster refresh
Cluster Capacity Higher than Individual Disks
Description
Total Cluster usage shown might be higher than the usage shown for individual disks.
For example, cluster usage can be 80%, yet highest utilized disk might show only 76% usage.
Action: None
The difference can be attributed to management layer handling. Use the cluster usage value to make all utilization related decisions.
Re-registering a Cluster Does Not Re-register Compute Nodes with EAM
Description
This can occur in a variety of scenarios. Possible scenarios include:
Scenario 1
- Start from an older HX version, prior to 2.1.x.
- Add a compute node.
- Re-register the cluster.
- Upgrade the cluster. Task fails to include the compute nodes.
Scenario 2
- Start from an older HX version, prior to 2.1.x.
- Add a compute node.
- Upgrade the cluster. Task completes.
- Re-register the cluster. Task fails at the EAM level.
Scenario 3
- Start with a new HX version, 2.1.x or later.
- Add a compute node.
- Re-register the cluster. Task fails at the EAM level.
Action: Remove compute nodes before re-register
|
Step 1 |
vMotion any VMs off of the compute nodes and remove the compute nodes from the HX cluster. |
|
Step 2 |
Re-register the HX cluster. |
|
Step 3 |
Add the compute nodes to the HX cluster. |
Latency Spikes Seen for Workloads with Large Working Sets
Description
Large working set workloads require accessing data from the capacity tier. As of HX Data Platform version 2.1(1b) backend access is optimized to significantly reduce the magnitude and frequency of high latency spikes.
- For hybrid clusters – When this symptom is present, the upgrade requires a longer maintenance window. Also, the default upgrade process does not automatically enable this optimization. Contact Cisco TAC to enable this performance enhancement during the upgrade process.
- For All Flash clusters - The upgrade times are not significantly affected and the default upgrade path automatically enables this performance enhancement.
Action: Upgrade to 2.1(1c) or greater
Cluster Health Status Remains Unhealthy after Rebalance
Description
In any three node cluster, including ROBO storage clusters, a single node in maintenance mode or failure causes the cluster to become unhealthy. Rebalance does not correct this.
Action: Return node to healthy state
Check that a node or component within a node is not failing. The cluster remains unhealthy as long as a component or node is failed. When the component or node returns to a healthy state, the cluster recovers and becomes healthy again.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-27-2018 01:02 AM
Hi,
I removed one node on the cluster and then when I move back the node in the cluster the controller VM stated that did not manage by ESX Agent manager. So do I need to refresh the cluster?
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide

{kind=link}