- Cisco Community
- Technology and Support
- Service Providers
- Service Providers Knowledge Base
- ASR9000/XR Netflow Architecture and overview
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 09-26-2012 12:06 PM
- Introduction
- Basic configuration for netflow
- Scale parameters for netflow
- Netflow support
- Architecture
- Netflow Cache size, maintenance and memory
- Sample usage
- Cache Size
- Aging
- Which packets are netflowed?
- Sampling
- Monitoring netflow
- The exporter (MAP)
- Troubleshooting Netflow
- Exporter fields
- Not supported features
- Related Information
Introduction
This document decribes the ASR9000 netflow architecture.
It provides a basic configuration how to set up netflow and what the parameters are for scale and how netflow is implemented in the ASR9000/XR
Basic configuration for netflow
The basic configuration for netflow consists of an
Flow monitor map
An exporter map
and a sampler map.
The Flow monitor MAP pulls in the Exporter map
On the interface you want to enable netflow on, you pull in the monitor map and the sampler map.
flow monitor-map FM
record ipv4
exporter FE
cache permanent
cache entries 10000
! cache timeouts define how frequently we export what, max of 1M per LC
cache timeout active 2
cache timeout inactive 2
!
flow exporter-map FE
version v9
options interface-table timeout 120
! these 2 define the exports of the sample map and interface table to theflow collector for sync'ing indexes
! to names etc.
options sampler-table timeout 120
!
transport udp 1963
destination 12.24.39.1
source <interfacename>
!
sampler-map FS
random 1 out-of 1
interface GigabitEthernet0/0/0/20
description Test PW to Adtech G4
ipv4 address 16.1.2.1 255.255.255.0
flow ipv4 monitor FM sampler FS ingress
!
Scale parameters for netflow
Ø Trident: 100kpps/LC (total, that is in+out combined) Typhoon: 200kpps/LC Ø 1M records per LC (default cache size is 64k) Ø 50K Flows per sec export per LC Ø Sample intervals from 1:1 to 1:64k
Ø Up to 8 exporters per map, vrf aware
Netflow support
Architecture
Netflow is not hardware accelerated in the ASR9000 or XR for that matter, but it is distributed.
What that means is that each linecard individually runs netflow by itself.
Resources are shared between the interfaces and NPU's on the linecard.
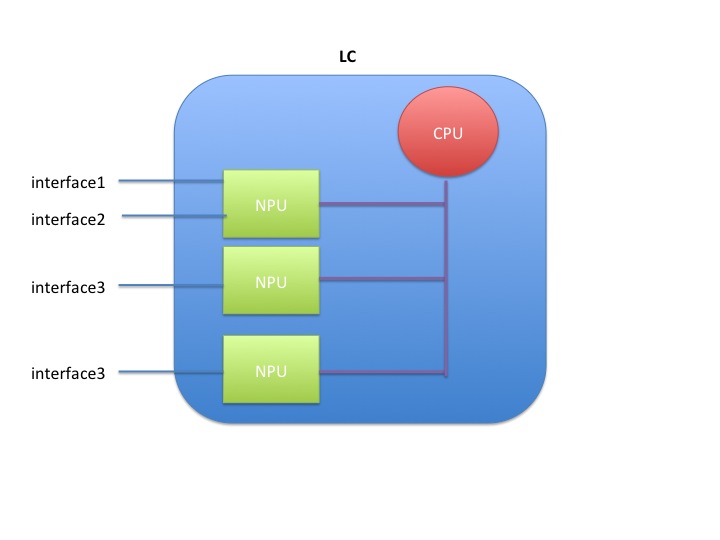
When you have 1 interface to one NPU on one linecard enabled for netflow, the full rate is available to that interface, which is 100k pps for trident and 200k for typhoon.
When you enable 2 interfaces on the same NPU on the same LC, then both interfaces share the 100k pps (trident) or 200k pps (typhoon)
When you enable 2 interfaces on 2 different NPU's, then both NPU's share the total rate of 100k/200k amongst them giving each NPU 50k or 100k depending on the LC type.
Packet flow for netflow
Inside the LC CPU

Netflow Cache size, maintenance and memory
In IOS-XR platforms, it is the LC processor memory that holds the netflow cache.
NetFlow Cache is a Section of memory that stores flow entries before they are exported to external collector.
The ‘nfsvr’ process running on the linecard, manages the netflow cache.
Memory usage
The memory used can be monitored via this command:
show flow monitor FM cache internal location 0/0/CPU0
...
Memory used: 8127060
Total memory used can be verified by checking the process memory util of "NFSVR"
show processes memory location 0/0/CPU0 | inc nfsvr
257 139264 65536 73728 12812288 nfsvr
Sample usage
The memory used with the cache size of default 64k entries for ipv4 & MPLS is about 8MB & for ipv6 is about 11MB.
The memory used with the cache size of maximum 1M entries for ipv4 & MPLS is about 116 MB & for ipv6 is about 150MB.
The memory used with cache size of maximum 1M entries (default is 65535) is about 116 MB per ipv4 flow monitor .
If ‘n’ ipv4 flow monitors are used all with maximum 1M entries, the memory used would be n x 116 MB.
Cache Size
Configuration to set the cache entries to ten thousand looks as follows:
flow monitor-map FM
cache entries 10000
Aging
95% of configured cache size is the high watermark threshold. Once this threshold is reached, certain flows (longest idle ones etc) are aggressively
timed out. XR 4.1.1 attempts to expire 15% of the flows.
The show flow monitor FM cache internal location 0/0/cpu0 command will give you the data on that:
Cache summary for Flow Monitor :
Cache size: 65535
Current entries: 17
High Watermark: 62258
NETFLOW-6-INFO_CACHE_SIZE_EXCEEDED
this syslog message means that we wanted to add more entries to the cache than what it could hold. There are a few different reasons and remediations for it:
- the cache size is too small, and by enlarging it we can hold more entries
- the inactive timeouts are too long, that is we hold entries too long in the cache not getting aged fast enough
- we have the right size cache, and we do export them adequately, but we are not getting the records out fast enough due to volume, in that case we can tune the rate limit of cache expiration entries via:
flow monitor <name> cache timeout rate-limit <time>
Permanent cache
The permanent cache is very different from a normal cache and will be useful for accounting or security monitoring. The permanent cache will be a fixed size chosen by the user. After the permanent cache is full all new flows will be dropped but all flows in the cache will be continuously updated over time (i.e similar to interface counters).
Note that the permanent cache uses a different template when it comes to the bytes and packets.
When using this perm cache, we do not report fields 1 and 2, but instead use 85 and 86.
Fields 1 and 2 are “deltas” 85 and 86 are "running counters".
In your collector you need to "teach" it that 1 and 85, 2 and 86 are equivalent.
Characteristics
Which packets are netflowed?
All packets subject to sampling, regardless or whethe they are forwarded or not are subject to netflow.
This includes packets dropped by ACL or QOS policing for instance!
A drop reason is reported to NF.. * ACL deny * unroutable * policer drop * WRED drop * Bad IP header checksum * TTL exceeded * Bad total length * uRPF drop
Example
IPV4SrcAddr IPV4DstAddr L4SrcPort L4DestPort IPV4Prot IPV4TOS InputInterface ForwardStatus ByteCount PacketCount Dir 17.1.1.2 99.99.99.99 3357 3357 udp 0 Gi0/1/0/39 DropACLDeny 415396224 8654088 Ing
Sampling
As described in the architecture section, the total sampling capability depends on the number of interfaces having netflow enabled.
It shaped up to be something like this table:
|
# of NPs Enabled for Netflow |
Policing Rate Per Trident NP (Unidirectional) |
Policing Rate Per Typhoon NP (Unidirectional) |
|
1 |
100kpps |
200kpps |
|
2 |
50kpps |
100kpps |
|
3 |
33kpps |
66kpps |
|
4 |
25kpps |
50kpps |
Punt Policing of netflow packets
All packets that exceed this rate are dropped by the punt policer.
You can verify that by the controllers np counters command.
show controllers np counters all
Node: 0/0/CPU0:
----------------------------------------------------------------
Show global stats counters for NP0, revision v2
Read 67 non-zero NP counters:
Offset Counter FrameValue Rate (pps)
-------------------------------------------------------------------------------
....
934 PUNT_NETFLOW 18089731973 6247
935 PUNT_NETFLOW_EXCD 6245 0
...
The _EXCD depicts that the police rate had been exceeded.
This means that you likely have to increase your sampling interval.
Monitoring netflow
sh flow monitor FM cache format table include layer4 tcp-flags ipv4 sour dest prot tos count pack byte location 0/0/CPU0
Mon Apr 19 09:31:19.589 EDT
Cache summary for Flow Monitor FM:
Cache size: 10000
Current entries: 1
High Watermark: 9500
Flows added: 1
Flows not added: 0
Ager Polls: 580
- Active timeout 0
- Inactive timeout 0
- TCP FIN flag 0
- Watermark aged 0
- Emergency aged 0
- Counter wrap aged 0
- Total 0
Periodic export:
- Counter wrap 0
- TCP FIN flag 0
Flows exported 0
IPV4SrcAddr IPV4DstAddr IPV4Prot IPV4TOS L4TCPFlags ByteCount PacketCount
16.1.2.2 16.1.1.2 tcp 0 S| 4282560 71 376
Matching entries: 1
The exporter (MAP)
Export occurs when data in the cache is removed which can occur in one of three ways.
- Inactive timer expiry : The cache entry expires due to not matching an incoming packet for a specified amount of time. Default value is 15 seconds.
- Active timer expiry : The cache entry, though still matching incoming packets, has been in the cache so long that it exceeds active timer. Default value is 30 minutes
- Cache Exhaustion : The cache becomes full, so some of the oldest entries are purged to make room for new entries.
The netflow exporter can be in a VRF, but can not be out of the Mgmt Interface.
Here’s why. The netflow runs off of the line card (LC interfaces and NP) and there is, by default, no forwarding between the LCs and the management Ethernet. This because the MGMT ether is designated out of band by LPTS (local packet transport services). More detail in the ASR9000 Local packet transport services document here on support forums).
Netflow records can be exported to any destination that may or may not be local to the LC where netflow is running. For example, LC in slot 1 & 2 are running netflow & the exporter may be connected to an interface reachble via LC in slot 3.
A total of 8 exporters per MAP is allowed.
Troubleshooting Netflow
Tue Nov 16 11:23:41.437 EST
Flow Exporter: FE
Flow Exporter memory usage: 3280812
Used by flow monitors: FM
Transport UDP
Destination 3.0.0.38 (1963)
Source 0.0.0.0 (12162) <<<<<<< PROBLEM!!
Flows exported: 0 (0 bytes)
Flows dropped: 0 (0 bytes)
.....
Exporter fields
Flow record key fields
- IPv4 source & destination addresses
- IPv4 protocol & TOS byte
- Transport source & destination ports
- Input interface
- Direction
- Forwarding status
- BGP next-hop
Flow record non-key fields
- TCP flags
- IPv4 source & destination prefix mask length
- Source & destination BGP AS #
- IPv4 address of BGP next hop
- Packet & byte counters
- First & last packet timestamps
- Output interface
Not supported features
Ø DBNA
Ø Cisco netflow mib is not supported.
Related Information
Netflow cache size considerations
Recent enhancements
Show commands
show flow exporter-map ..
show flow monitor-map ..
show sampler-map ..
show processes memory location <0/0/CPU0> | inc nfsvr
show flow monitor .. cache internal location <0/0/CPU0>
show flow exporter .. location <0/1/CPU0>
show flow platform producer statistics location <0/0/CPU0>
show flow platform nfea policer np <np_num> loc <node-id>
show controller np ports all location <0/Y/CPU0>
show controller np count np<number> loc <0/Y/CPU0>
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
Great article on XR Netflow, I appreciate the detailed information. Using the record mpls ipv4-ipv6-fields option will I be able to export flows tunneled through a l2vpn vc?
On a separate topic, do you have any information on XR CBQoS SNMP support? I find this feature very useful in IOSto monitor interface policy-map utilization and I am having trouble finding support specifically for CISCO-CBP-TARGET-MIB in XR.
Regards,
Jon
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Jon, thank you! We cannot apply netflow to L2 circuits, only to L3 enabled interfaces, that is interfaces of the non l2transport kind and should have an ip address associated with it.
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
You said that the netflow exporter can be in a VRF, but can not be out of the Mgmt Interface.
If we use out of band management and the destination is behind Mgmt Interface, is there any workaround solution? What version code you refer to?
Thanks,
Judy
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Judy, the netflow destination must be found via a fabric enabled interface (that is an interface on a linecard).
This is irrespective of the code as this is defined by the implementation of LPTS.
regards!
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
I think we are talking about different things. Using the example configuration above, you mean the interface
0/0/0/20, I was asked you the interface to forward records out. I guess I misunderstood.
I got it.
thanks,
JT
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
aha I see Judy: yeah the 0/0/0/20 is a fabric interface on a linecard that runs netflow, as it is getting sampled.
The netflow exporter, that is the address of the netflow collector in your exporter map, that one has to be found via a fabric enabled interface also and cannot be routed out the mgmt interface.
(netflow runs on the LC and the LC can inject the export records just fine, but since it is attached to the fabric it cannot *route* through the mgmt interfaces on the RSP.
regards
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
I just found the follow tips at Cisco Netflow documents.
"We recommend that you do not use the management interface to export NetFlow packets. Exporting the
management interface does not work efficiently."
-JT
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
yeah it finally got added properly to the official documentation. Although I dont like the wording: "it is not recommended", it should say it doesn't work...
regards
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi,
Netflow on ASR9001 has all the limitations of a single Typhoon LC. Did I get it right?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Correct indeed!
An asr9001 is really like a MOD80 LC and "sort-of" RSP440 slapped into the same chassis.
So all limitations you read about a MOD80 typhoon linecard will apply to an ASR9001 also.
regards
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Great article !
When highwater mark is exceeded, recommendation is to increase cache, with a trade-off in respect to straining LC memory. Would a safer option be to increase sampling interval ?
TIA
/Samir
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
hey samir, thanks! :)
when you reach the high watermark it starts aggressively aging out flows to create room for new ones.
The lowering sampling interval when there is a high variety of flows would potentially temporarily mitigate the situation, but statistically, we'd still be capturing flows at a lower sampling rate too, so your cache may not fill that quick as it did before, but there is still a chance of.
The trade of here to be made is:
CPU util: aggressive timers will induce extra load, but can keep your cache size smaller
Increase cache: will allow more flows at the expense of shared memory that is used by other functionality and features
sampling rate: high will provide higher accuracy with more correlation load, where as a lower rate will reduce the cache constraints giving a little less accuracy especially for short lived flows.
cheers
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks a million Xander !
Is there a best practice safe recommendation at this point ?
/Samir
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
That's difficult Samir, it is very much dependent on your other shared mem needs, and how much cpu you're willing to use for this functionality and the desired accuracy. Then the flow distribution you have is also very much important factor in this:
eg if you have 2 datacenters interconnecting, then the distri is not that large so you can live with a much lower sampling rate. Also because these flows tend to be longer lived hence netflow will see them.
Internet access will see a lot of flow distris and short lived, requiring a potentially higher sampling rate, getting more samples up and requires more memory for those flows.
To give 2 basic "profiles":
use case: to get an "idea" of traffic:
cachesize minimal, sampling rate low (eg 1:10000) default export timers
use case: accuracy and detail:
cachesize maximum of 1M, sampling rate high 1:100/1000
potentially need tweak on timers if the flow distri is high; adds cpu load
generally there is no problem setting the cache size to 1M.
It is about 250 bytes per flow or so. If you dont have amssive arp scale or high qos profiles, then this may work easily.
regards
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Very fair answer Xander, it makes sense.
I am on a CRS and expect a conservative cache increase to be relatively safe.
Many thanks again.
/Samir
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: