- Cisco Community
- Technology and Support
- Service Providers
- Service Providers Knowledge Base
- ASR9000/XR: Understanding BGP flowspec (BGP-FS)
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-07-2014 01:55 PM - edited 08-08-2019 08:04 AM
Introduction
BGP flow spec is a new tool that can be used to assist in DDOS mitigation in a dynamic fashion, levering BGP.
When I first started working and looking at BGP-FS I was a bit confused and in this article I would like to try and unravvle some of the specifics of BGP-FS, what you can do with it and how it works.
DDOS mitigation via RTBH (remote triggered blackhole)
Conceptually in this picture:
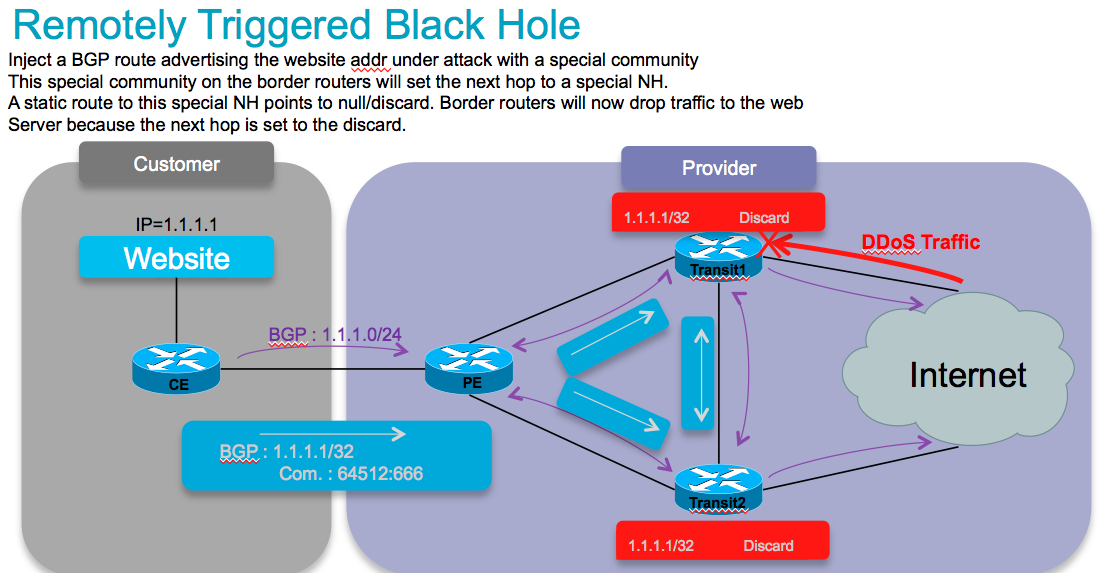
DDOS mitigation with the help of BGP is generally done via RTBH (remote triggered blackhole). And this comes basically in 2 key flavors: Source and Destination based.
The concept is that a BGP edge speaker has a static route defined to a "special next hop" to null0.
From a central point we inject a new route for a particular destination (eg our affected webserver) with a next hop pointing to that special next hop. This means that now at our border routers, our webserver address is set to a next hop, and this next hop is drop, and we prevent this traffic from hitting our server. This protects it nicely. But it removes the ability to reach this server completely!
The source based model is a similar concept whereby we KNOW where an attack comes from and now we send in a bgp path for that source with the special next hop, which then points to null.
Now when we use uRPF (reverse path forwarding), when a packet from that suspect source comes in, we apply RPF, we find the nexthop set to null0/discard. This would make RPF fail and we drop the packet from that host (or subnet for that matter).
Both options work great, but are big hammers.
BGP flowspec allows for a more granular appraoch and effectively construct instructions to match a particular flow with source AND destination, and L4 parameters and packet specifics such as length, fragment etc, and allow for a dynamic installation of an action at the border rotuers to either:
- drop the traffic
- inject it in a different vrf (for analysis)
- or allow it, but police it at a specific defined rate.
Cool. Now that we got that theory out of the way, how about Flowspec then, what does it do and how is it different?!
BGP flowspec definitions
This conceptually describes how flowspec works:
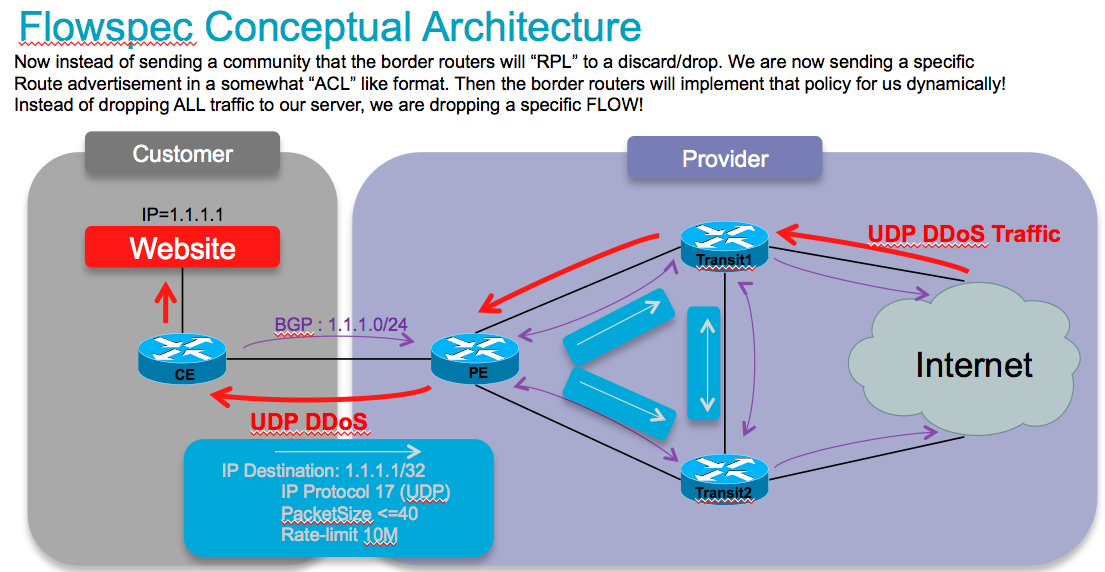
So instead of sending/injecting a route for our server or server subnet with a special community that the border routers will associated with a nexthop to drop in their route policy language, in this case we are sending the new flowspec attribute format down to the border routers instructing them to create a sort of ACL with class-map and policy-map to implement this rule that we are advertising!
Very nifty, am lovin it. So in order to do that, we need to extend the BGP protocol a bit, and this is how the RFC is defining that approach:
BGP FS adds a new NLRI (network layer reachability info) to the BGP protocol:
NLRI defined (AFI=1, SAFI=133)
It adds the following packet/attribute format:

It allows for the following parameters to be defined:
6.Source Port (+1 component)
7.ICMP Type (asr9k has support for this yet, CRS does also)
8.ICMP Code (asr9k has support for this yet, CRS does also)
9.TCP Flags (asr9k supports lower byte, crs can not look at all bits)
10.Packet length
11.DSCP
12.Fragment
The actions that can be associated to a flow that we matched on by the parameters specified above are encoded as follows:

And the available actions that we can define are:
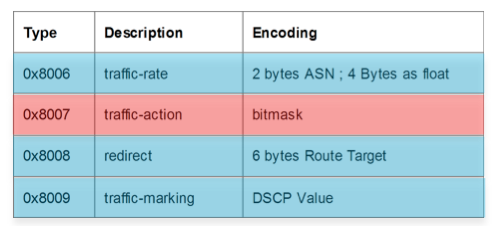
So with these new rules we can define a prefix or prefix set and not just that, we can base it on L3 source, L3 dest, its L4 specifics and even on packet length and L3 header options such as fragments! Then we can specify what actions we want to associate with that flow, redirect it, remark it, drop it or police it. And that is the full flow info.
All actions are supported by both CRS and ASR9000.
Ok this is all awesome, now that we got the theory out of the way, you want to go set it up I am sure!
Client/Server Model
In BGP-FS there is a client and a server. What that effectively means is that there is a device that injects the new flowspec entry (for the lack of a better word I guess) and there is a device (BGP speaker) that receives that NRLI and has to implement something in the hardware forwarding to act on that instruction.
So the device sending or injecting the NRLI is what I call the server, and the device that receive the NRLI and programs the hardware forwarding is called the client.
Visually:
CLIENT
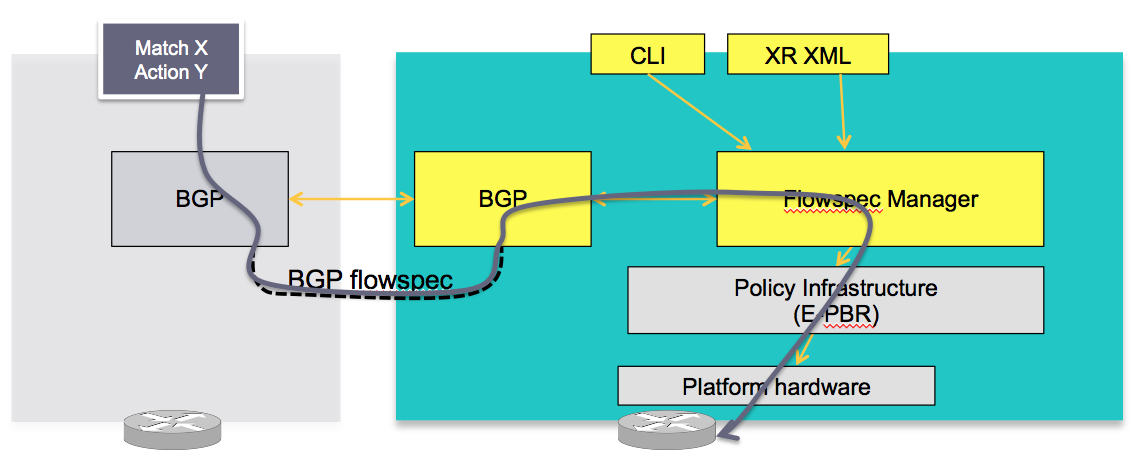
In this concept the server in the grey box injects the flowspec NRLI and the client in the right box receives the information, sends it to the flow spec manager, configures the ePBR (enhance Policy based routing) infrastructure who then in turn programs the hardware from the underlaying platform in use.
SERVER
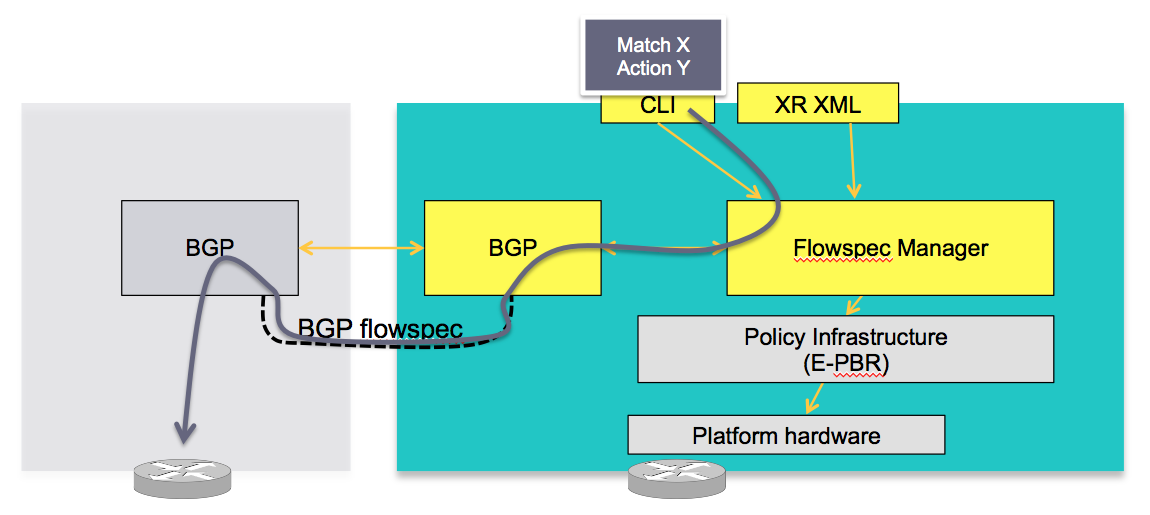
The server is configured either via CLI or XML to provide that entry for NRLI injection.
Note that XRv, virtual XR, can be a Server, it can inject those NRLI's for an asr9000 or CRS to act on those. Obviously XRv, not having a hardware forwarding layer is not a client
Configuration
conceptually
BGP
applicable to both client and server, we need to enable the new address family for advertisement:
router bgp 100
address-family ipv4 flowspec
! Initializes the global address family
address-family ipv6 flowspec
!
neighbor 1.1.1.1
remote-as 100
address-family ipv4 flowspec
! Ties it to a neighbor configuration
address-family ipv6 flowspec
!
Interface
You can disable flowspec on the interface as follows:
Interface gigabit0/0/0/0
ipv4 flowspec disable
!
Client
requires no special config other then a flowspec enabled peer.
Server
The server side configuration includes the policy-map definition and the association to the ePBR config consists of 2 portions, the class definition, and using that class in ePBR to define the action.
Classification
class-map type traffic match-all <class-name>
<match statement> #Any combination of tuples 1-13 match statements goes here.
end-class-map
!
!
Tuple definition possibilities:
#Type 1: match destination-address {ipv4| ipv6} <IPv4/v6 address>/<mask-length>
#Type 2: match source-address {ipv4| ipv6} <IPv4/v6 address>/<mask-length>
#Type 3: match protocol { <value> | <min_value> - <max_value> }
<!In case of IPv6, it will map to last next-header >
#Type 4: create two class-maps one with source-port and another with destionation-port
match source-port { <value> | <min_value> - <max_value> }
match destination-port { <value> | <min_value> - <max_value> }
<! Applicable only for TCP and UDP protocol !>
#Type 5: match destination-port { <value> | <min_value> - <max_value> }
#Type 6: match source-port { <value> | <min_value> - <max_value> }
#Type 7: match {ipv4 | ipv6} icmp-type { <value> | <min_value> - <max_value>}
#Type 8: match {ipv4 | Ipv6} icmp-code { <value> | <min_value> - <max_value>}
#Type 9: match tcp-flag <value> bit-mask <mask-value>
#Type 10: match packet length { <value> | <min_value> - <max_value> }
#Type 11: match dscp { <value> | <min_value> - <max_value> }
match ipv6 traffic-class { <value> | <min_value> - <max_value> }
[for providing 8 bit traffic class value]
#Type 12: match fragment-type {dont-fragment, is-fragment, first-fragment, last-fragment}
#Type 13: match ipv6 flow-label { <value> | <min_value> - <max_value> }
policy-map type pbr <policy-name>
class type traffic <class-name>
<action> #Any one of the extend community action listed below
class class-default
end-policy-map
ACTIONS:
##Traffic rate:
police rate < > | drop
#Traffic action:
sample-log
#Traffic marking:
set dscp <6 bit value> |
set ipv6 traffic-class <8 bit value>
#VRF redirect based on route-target:
redirect {ipv6} extcommunity rt <route_target_string>
# Redirect IP nexthop support
redirect {ipv6} next-hop <ipv4/v6 address> {ipv4/v6 address}
The following ties the flowspec to the PBR policies defined earlier.
flowspec
[local-install interface-all]
address-family ipv4
[local-install interface-all]
service-policy type pbr <policy-name>
service-policy type pbr <policy-name>
address-family ipv6
[local-install interface-all]
service-policy type pbr <policy-name>
service-policy type pbr <policy-name>
!
!
vrf <vrf-name>
address-family ipv4
[local-install interface-all]
service-policy type pbr <policy-name>
service-policy type pbr <policy-name>
address-family ipv6
[local-install interface-all]
service-policy type pbr <policy-name>
service-policy type pbr <policy-name>
!
!
!
Example use case/configuration:
Target:
all packets to 10.0.1/24 from 192/8 and destination-port {range [137, 139] or 8080, rate limit to 500 bps in blue vrf and drop it in vrf-default. Also disable flowspec getting enabled on gig 0/0/0/0.
Associated copy paste config:
class-map type traffic match-all fs_tuple
match destination-address ipv4 10.0.1.0/24
match source-address ipv4 192.0.0.0/8
match destination-port 137-139 8080
end-class-map
!
!
policy-map type pbr fs_table_blue
class type traffic fs_tuple
police rate 500 bps
!
!
class class-default
!
end-policy-map
policy-map type pbr fs_table_default
class type traffic fs_tuple
drop
!
!
class class-default
!
end-policy-map
flowspec
local-install interface-all
address-family ipv4
service-policy type pbr fs_table_default
!
!
vrf blue
address-family ipv4
service-policy type pbr fs_table_blue local
!
!
!
!
Interface GigabitEthernet 0/0/0/0
vrf blue
ipv4 flowspec disable
BGP Flowspec and local QoS configuration
When flowspec is implemented on an interface that is also having local QoS configuration, local config will come before flowspec processing.
Local config will police and dscp-mark the packets and pass them to flowspec.
Flowspec will then do its processing (police, redirect) except dscp marking.
Flowspec will retain dscp marking as dictated by local qos config.
Say, we have the following:
inbound qos config : police 100Mbps, mark dscp af11
=============================================================
ipv4 access-list acl_ipv4_qos_stream
6 permit ipv4 any host 200.255.5.2
!
!
class-map match-any cm_ipv4_qos_stream
match access-group ipv4 acl_ipv4_qos_stream
end-class-map
!
policy-map pm_ipv4_qos_stream
class cm_ipv4_qos_stream
police rate 100 mbps
!
set dscp af11
!
class class-default
!
end-policy-map
!
interface hundredGigE 0/4/0/35
service-policy input pm_ipv4_qos_stream
=============================================================
Then we receive the following in flowspec advertisement.
flowspec config : police 50Mbps, mark dscp af43, redir vrf.
=============================================================
RP/0/RP0/CPU0:fretta-50#sh flowspec ipv4 detail | b 200.255.5.2
Flow :Dest:200.255.5.2/32
Actions :Traffic-rate: 50000000 bps DSCP: af43 Redirect: VRF honeypot Route-target: ASN2-4787:13 (bgp.1)
Statistics (packets/bytes)
Matched : 116570713/12822778430
Transmitted : 57360817/6309689870
Dropped : 59209896/6513088560
=============================================================
Then the outcome will be:
- traffic will be policed by flowspec at 50Mbps.
- traffic will be redirected by flowspec to VRF honeypot.
- flowspec will not overwrite dscp marking, traffic will be forwarded using dscp af11 instead of af43.
NCS5500 platform will also display this same behavior.
Related Information
Special thanks to Nic Fevrier whose pictures I used for some of the visuals above.
Xander Thuijs CCIE#6775
Principal Engineer, ASR9000
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
Great write up. Any chance that BGP FlowSpec can be used to implement something like Juniper's prefix-action - which is basically UBRL but at a subnet granularity rather than a flow granularity? Our requirement is to police subnets within an address block:
Parent subnet x.y.0.0/17 - /29 subnetwork within this block to be policed at 1Gbps
x.y.0.0/29 > Total inbound traffic will not exceed 1Gbps
x.y.0.8/29 > Total inbound traffic will not exceed 1Gbps
x.y.0.16/29 > Total inbound traffic will not exceed 1Gbps
x.y.0/24/29 > Total inbound traffic will not exceed 1Gbps
Thanks,
Terry
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Terry, thank you!! :)
I dont think the flowspec would lend itself for that too easily, but I think you can very easily use QPPB for that requirement!! If the prefixes you have referenced here are actually bgp prefixes, then we can trap those and set a qos-group on them and have them policed either on ingress or egress.
If you do it on ingress, it will be a feedback loop (so cost some pps perforamnce). Doing it on egress will make it "aggregate" from all incoming sources, but that may just want you want anyway it sounds like.
Check the QPPB write up here:
https://supportforums.cisco.com/document/12050971/asr9000xr-implementing-qos-policy-propagation-bgp-qppb
cheers
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Giving it a second thought also, I think you can leverage flowspec here too, by basically advertising the FS subnets and assigning a policer action on it in the flowspec "server" down to the clients. Yes that shoudl work also!
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
Thanks for your reply! What if the prefixes weren't BGP prefixes? That is to say, the ASR is configured to statically route 10.1.0.0/17 and the policy that needs to be imposed is every /29 requires 1G of traffic. If the /29 in aggregate uses more than 1G, a policer exceed action (for example) needs to be taken.
Typically, UBRL would implement this for each /32. What I need is this for a /29.
Thanks again,
Terry
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
I guess what I'm trying to avoid is having to statically define 4096 policer configs
2^(subnet - route) = 2^(29-17) = 2^12 =4096
UBRL is the obvious solution if the granularity required is /32.
I can use BGP and inject /29s if that would make it simpler, but with both QPPB and FS I'd have to define the policer individually, which doesn't get around my basic problem. Ideally what I need is a mechanism to define policers via a template.
Thanks,
Terry
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hey Xander thanks for the great article!
I would like your thoughts on the following. Still for a SP DDoS 'clean pipes' type of design, by making use of BGP FS you would gain more granularity to do a specific action (police, drop,etc) a flowspec of the attack traffic and still have the rest of 'clean' traffic to flow to the end destination.
But to really 'clean' the traffic you still need a TMS (mitigation) element in your DDoS architecture (as the CGSE in a CRS) etc right?
Any thoughts on this are greatly appreciated!
thanks
Carlos
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Carlos, that is correct, you would need a device to clean the traffic.
A generic approach taken is that on the suspicion of "dirty traffic" a filter via FS is set up to tunnel/redirect that traffic to the cleaner, once that cleaner has filtered this traffic it can send it back for original path transmission to the destination it was set for.
Unless you have such a good signature handler that knows exactly the right from wrong, learnt from netflow or DPI (eg via VSM, the virtual service module application) then it can instruct FS also to immediately drop or police that traffic.
I think the approach to first attempt to clean is better, for this simple reason it helps learning more about mallicious flow, so it is great for datamining.
Another thing to add next to FS, if you're dual homed, is by readvertising some metrics for the affected destination prefix, this so it only goes into one of the homed pairs so that the other border router is dealing with mostly clean traffic, also not necessary, but a nice option.
cheers!
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks Alexander for the great post!
Can You tell us, is it possible to configure and test bgp flowspec on CSR1000v or XRv platforms?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
You won't be able to test forwarding plane on XRv but you will be able to use XRv as a BGP FlowSpec controller to inject rules.
As long as you don't want to pass traffic, you can still play with several XRv and learn how it can be configured. The rules will be advertised and learned but of course, nothing will be programmed at the data plane level.
Cheers,
N.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks Nicolas!
As I understand, FlowSpec is just BGP extension for distributed rules/acl's/blackholing...
We should use a FlowSpec server (with NetFlow collector) in order to detect and inject forwarding rules (dynamically when necessary).
Is there a full solution, I mean what server/software we should use here in order to detect and mitigate DDoS attacks?
Thanks!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi,
actually, BGP FS goes beyond ACL/Blackholing: It can also be used to rate-limit the traffic matched by the description, or divert it to a new next-hop address or to leak into a different VRF, or to remark the DSCP field of the traffic.
I'm not aware of any open-source / free pre-packaged solution to do the detection (based on NFv9 records), and rules injecting. But commercial solutions (like Arbor Peakflow SP for example) can do this pretty well.
BR,
N.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Xander,
Thanks for the great article. What would the configuration look like if you want the policy to be enforced in a VRF on your client? When I generate a flowspec route from the controller (which also happens to be a client of itself), locally the policy is enforced just fine:
RP/0/RSP0/CPU0:9006-4-LAB#show flowspec vrf BLA01 ipv4 detail
VRF: BLA01 AFI: IPv4
Flow :Dest:10.62.80.13/32
Actions :Traffic-rate: 1 bps Redirect: VRF BLA01 Route-target: ASN2-65200:10110101 (policy.1.POLICY1.CLASS1)
Statistics (packets/bytes)
Matched : 403720173/302794570111
Dropped : 403607779/302709184649
...However when I move over to one of the clients the flow only shows up in the global table. There is no flow entry for the vrf table at all:
RP/0/RSP0/CPU0:9006-3-LAB#show flowspec vrf all afi-all detail
AFI: IPv4
Flow :Dest:10.62.80.13/32
Actions :Traffic-rate: 0 bps (bgp.1)
Statistics (packets/bytes)
Matched : 0/0
Dropped : 0/0
I think I'm missing something simple here and hoping you might know off the top of your head. Thanks in advance!
Brad
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
hey brad, I probably need to see the precise configuration to understand some things better, but enabling flowspec on an interface in a vrf should be just fine.
it may be a cosmetic issue, or some config issue that we could possibly resolve.
cheers
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
I thought that this was the only way to enable flowspec on an interface:
RP/0/RSP0/CPU0:9006-3-LAB#show run flowspec
flowspec
vrf BLA01
address-family ipv4
local-install interface-all
!
!
!
Is there a different way?
To expand on the flowspec specific config a bit more the "client" has ipv4/ipv6 flowspec peering relationships with reflectors, and what I pasted above. Nothing else.
The "controller" has the same BGP peering relationships to the reflectors, along with the class-map, policy-map and the below config:
RP/0/RSP0/CPU0:9006-4-LAB#show run flowspec
flowspec
address-family ipv4
local-install interface-all
service-policy type pbr POLICY1
!
vrf BLA01
address-family ipv4
local-install interface-all
service-policy type pbr POLICY1
!
!
The client receives the route just fine:
RP/0/RSP0/CPU0:9006-3-LAB#show bgp ipv4 flowspec Dest:10.62.80.13/32/48
BGP routing table entry for Dest:10.62.80.13/32/48
Versions:
Process bRIB/RIB SendTblVer
Speaker 3 3
Last Modified: Jan 29 21:34:13.968 for 00:17:00
Paths: (1 available, best #1)
Not advertised to any peer
Path #1: Received by speaker 0
Not advertised to any peer
Local
0.0.0.0 from 10.1.1.20 (10.1.1.4)
Origin IGP, localpref 100, valid, internal, best, group-best
Received Path ID 0, Local Path ID 1, version 3
Extended community: FLOWSPEC Traffic-rate:200,0
Originator: 10.1.1.4, Cluster list: 0.1.8.0
But it's only installing the flow rule into the global table:
RP/0/RSP0/CPU0:9006-3-LAB#show flowspec vrf default ipv4 detail
AFI: IPv4
Flow :Dest:10.62.80.13/32
Actions :Traffic-rate: 0 bps (bgp.1)
Statistics (packets/bytes)
Matched : 0/0
Dropped : 0/0
RP/0/RSP0/CPU0:9006-3-LAB#show flowspec vrf BLA01 ipv4 detail
<no output>
The controller, which is also a client of itself, installs the policy into the correct table, and filters traffic as expected:
RP/0/RSP0/CPU0:9006-4-LAB#show flowspec vrf BLA01 ipv4 detail
VRF: BLA01 AFI: IPv4
Flow :Dest:10.62.80.13/32
Actions :Traffic-rate: 1 bps (policy.1.POLICY1.CLASS1)
Statistics (packets/bytes)
Matched : 821063216/615803701906
Dropped : 821159191/615873323343
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Looks like you didn't enable the vpnv4 flowspec peering between your controller and client.
Could you please share the router BGP config on both sides ?
Thanks,
N;
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: