- Cisco Community
- Technology and Support
- Service Providers
- Service Providers Knowledge Base
- ASR9000/XR Using and understanding BNG GEO-Redundancy
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
04-17-2016 05:43 AM - edited 01-29-2019 08:04 AM
Introduction
Geo redundancy is a powerful new technology for XR BNG that allows for session synchronization between 2 nodes. This means that a session active on one node has a shadow and fully programmed session on a standby node, so that when the active chassis fails, the standby BNG can take over and continue to forward the session info WITHOUT service interruption to the user.
Geo redundancy overcomes some of the restrictions that other redundancy models have which makes it a solution that is very compelling.
Existing redundancy models
Some of the existing models include the use of PPPoE smart server selection, ASR9K nv Cluster, ISSU, MC-LAG/MSTAG. This section outlines their operation and pros/cons.
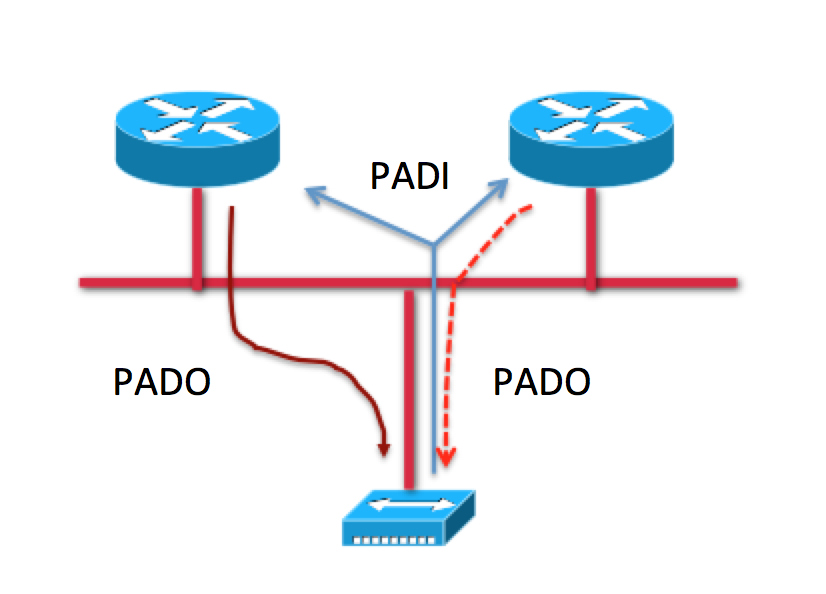
Smart Server selection
Smart server selection relies on the operation whereby a host sends a PADI (discovery), which is broadcast to multiple devices/BNG's. Normally all hosts send a PADO (offer) back to the client who then connects with one of the offered BNG's for a single connection. By controlling the response time of the PADO's from all BNG's we can make one node more primary for a particular vlan, and the other(s!) standby.
The solution is stateless, meaning that if the active node dies, the client needs to rediscover and will find one or more stadnby BNG's for connection with.
Pro is that this is simple, useful, it provides N+1 redundancy (multiple BNG nodes can be used on the segment for more sharing of the load).
Con is that this is stateless, clients have to reconnect, per vlan bases and for PPPoE only (not usable for dhcp). Though a similar concept can be leveraged for IP sessions by delaying the offer timers of the dhcp server.
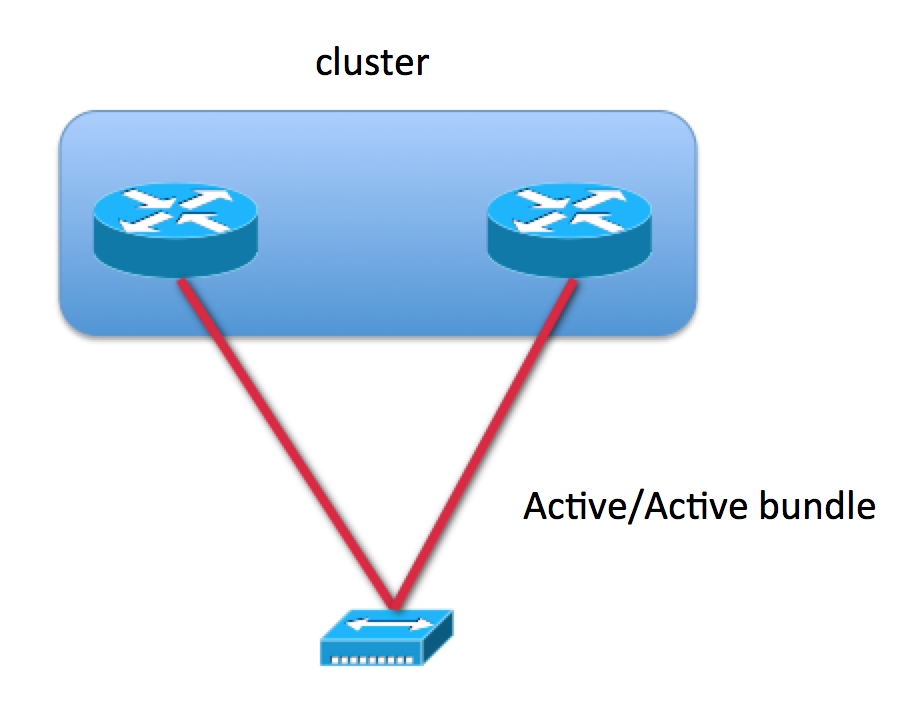
nV Cluster
Clustering two devices by linking their brains together via what we call the EOBC (Ether out of band connection), makes two chassis become a perfect mirror from each other. This automatically means that you have stateful redundancy.
It relies on the fact that you are dual homed with a connection in both both racks of the cluster. If the cluster device or rack we call it, fails the other chassis will take over as sole primary and the forwarding over the bundle all happens without any disruption
Pro: powerful, stateful, high scale
Con: sw upgrades, hw restrictions for cluster, requires bundle intefaces and dual homing into both nodes of the cluster, costly/license
MCLAG/MSTAG
Using standard redundancy technologies like mclag or mstag provides for a lot of simplicity. These technologies allow for dual homing and relying on ICCP (mclag) or STP (MSTAG) protocols to detect loops and only have one active link forwarding.
This means that a session is only available and active on one node at the time.
Pro: very simple low cost
Con: long convergence times and stateless
Summary
How nice would it be to have the best of all these solutions and not having so much cons? That is where GeoRed comes into play :)
How to use GeoRed
Geo redundancy provides for a very powerful M:N or N+1 redundancy model depending on how you like to implement it.
Flexible redundancy models via pairing across routers on Access Link basis
- 1:1 (both active/active with load sharing or active/standby) (like nv Cluster)
- M:N (active/standby roles and load is split across multiple routers)
- N:1 (1 backup for N active)
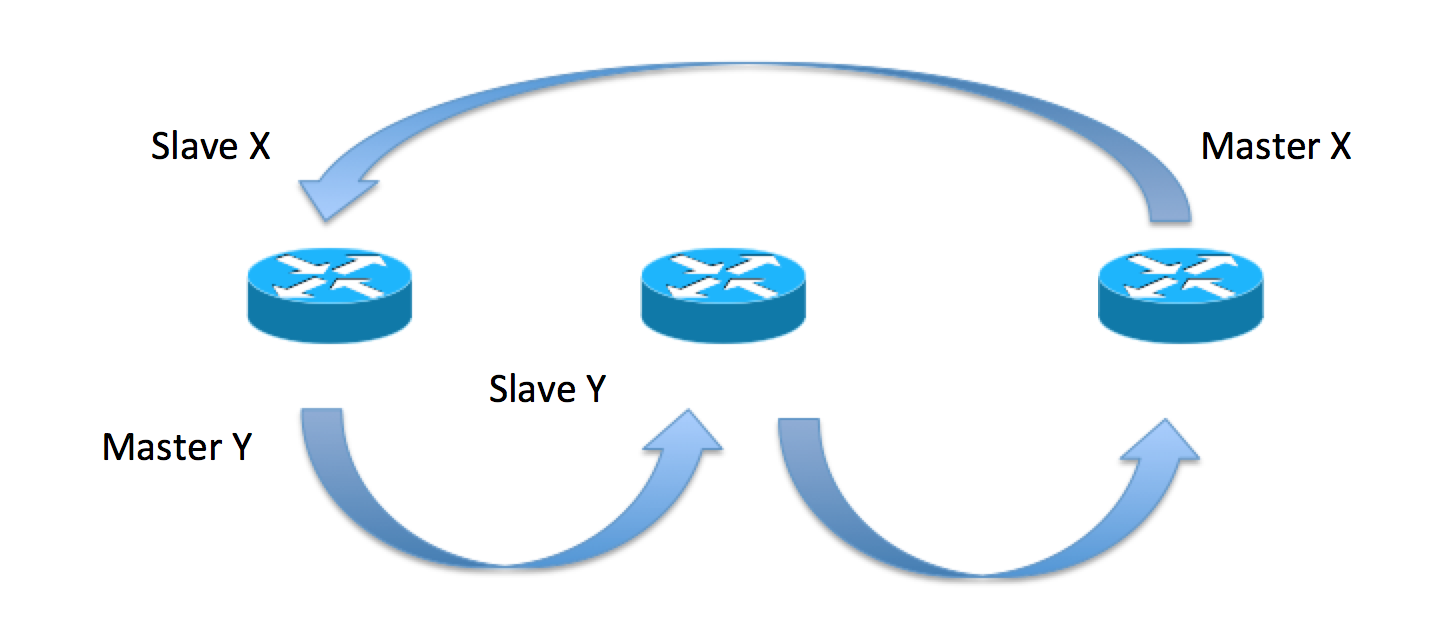
Full circle standby (M:N)
Designated backup (N:1)
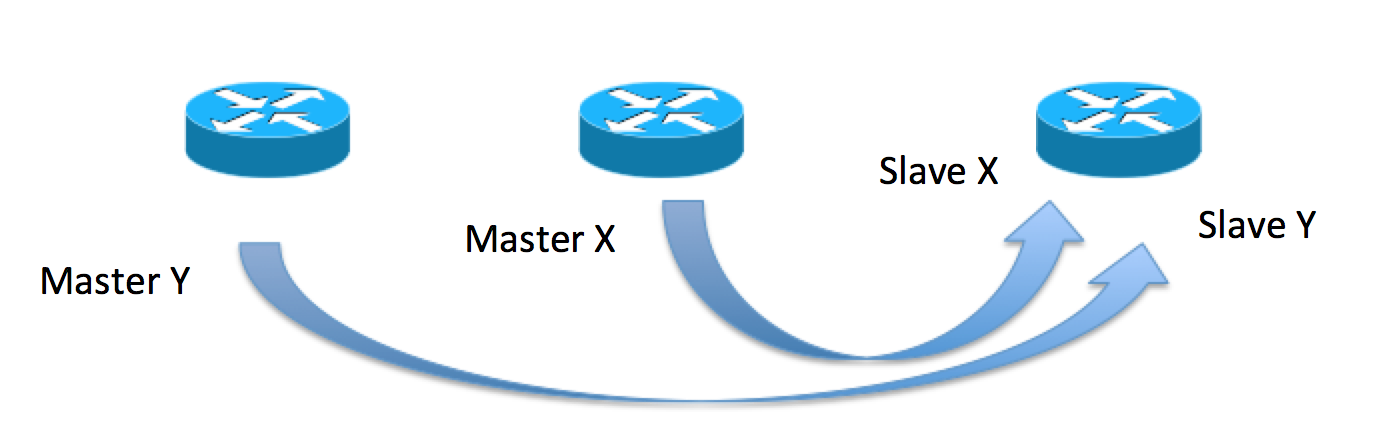
There is no special connection required between the BNG's, just an ip connectivity for the redundancy protocol (to be discussed later).
One big advantage is also that the different BNG nodes may be placed in different geo-locations without any limitations!
Complements existing BNG high-availability, redundancy and geo-redundancy mechanisms.
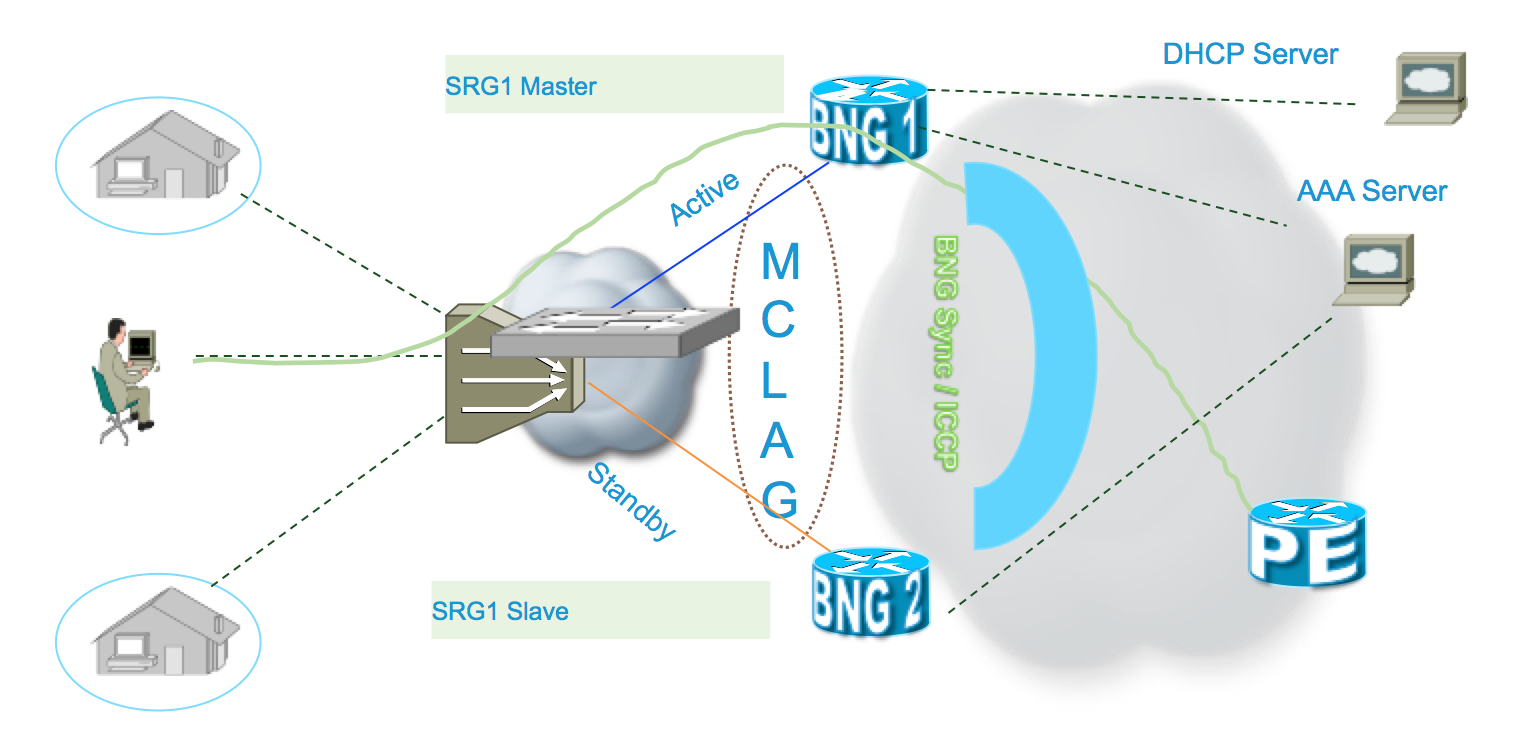
Geo redundancy in a nutshell:
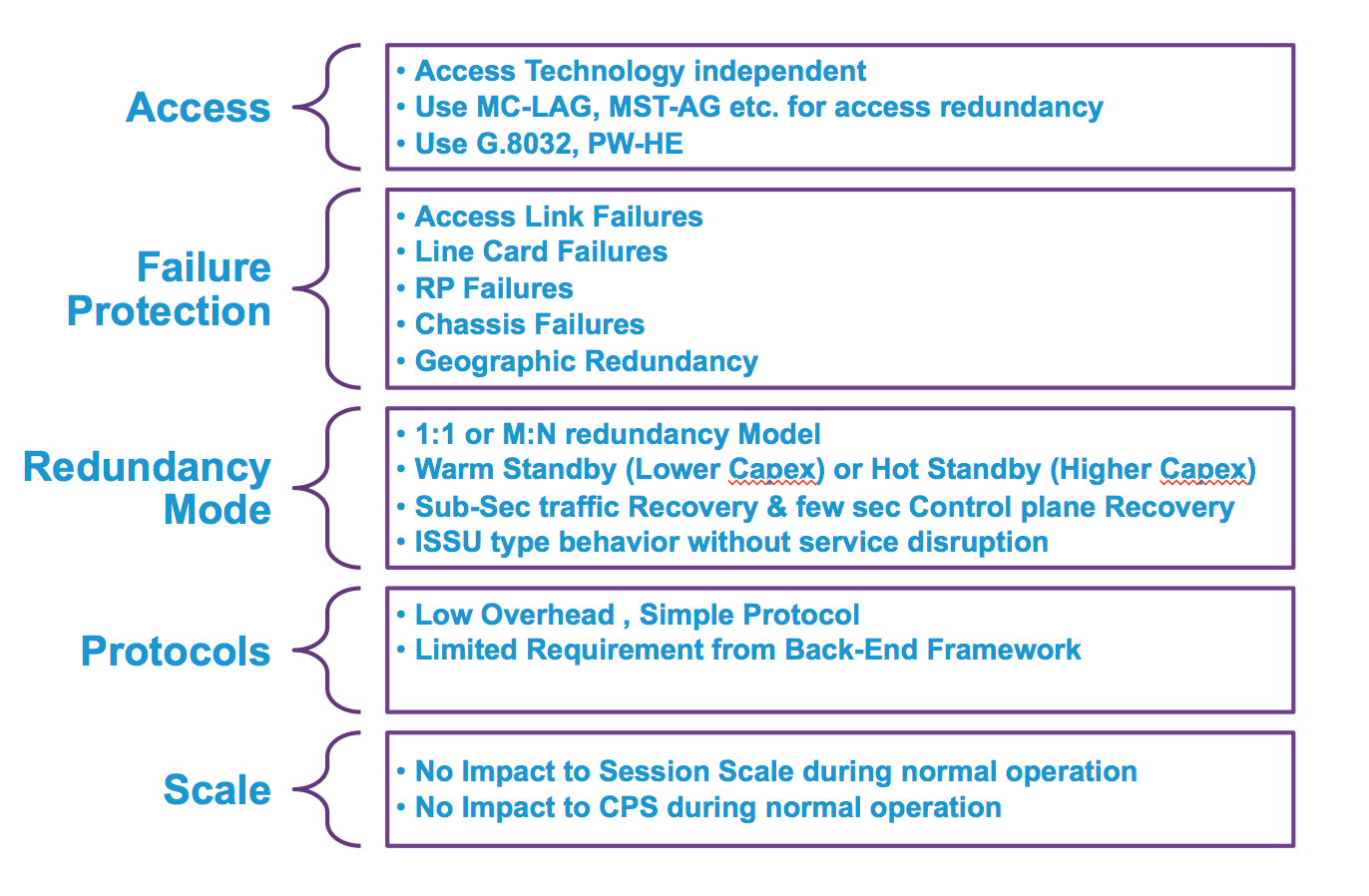
A typical design could look like this:
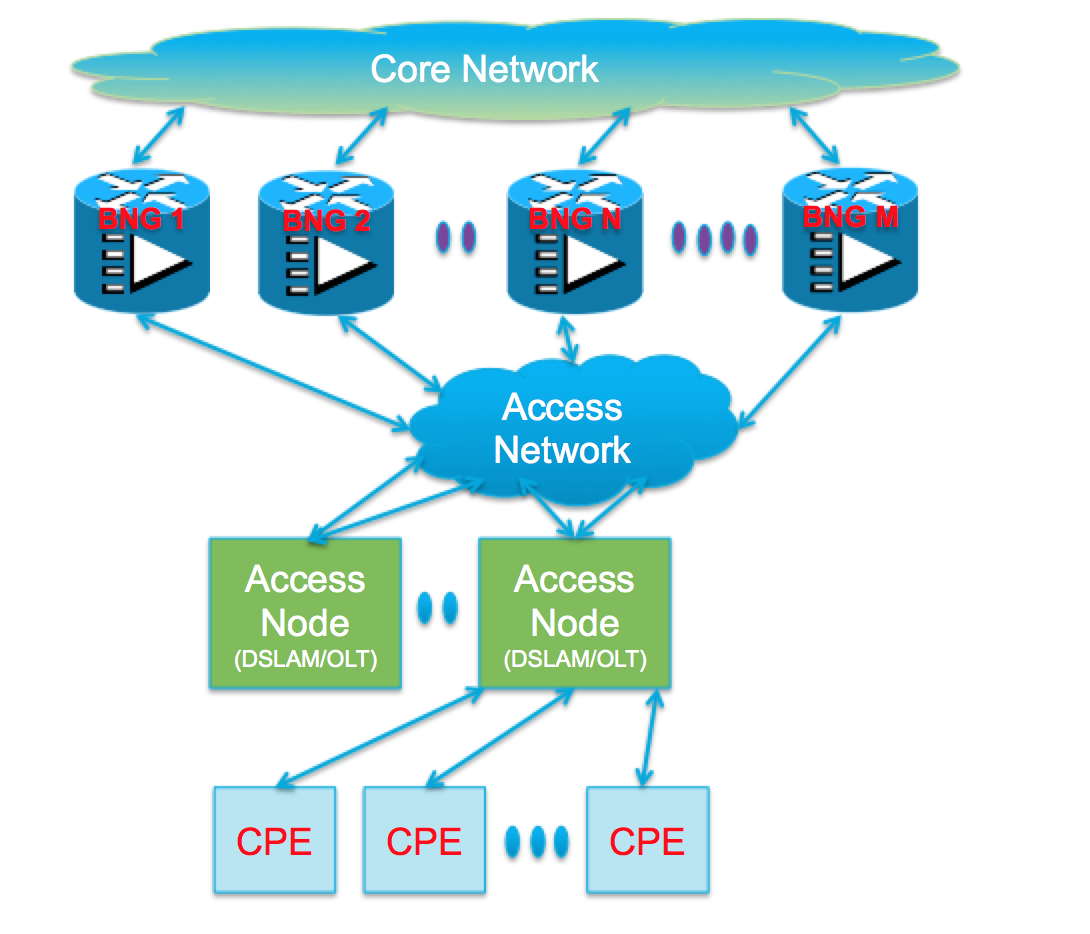
CPEs are agnostic to redundancy and they see “one BNG / Gateway”. Any switchover is transparent to them. With the redundancy model used, the CPE peers with the same mac address and node ID hence if a failover is required the CPe doesn't even know that it is talking to a different physical device.
Access Nodes are dual/multi-homed for redundancy using a variety of technologies such as MCLAG, Dual Homed (MST-AG), Ring (MST-AG or G.8032), xSTP, Seamless MPLS (PWs), etc. Using heartbeat mechanisms like E-OAM, BFD, etc. for faster fault detection/isolation.
BNG is not just a gateway router, it has subscriber state, policies and accounting/authorization details and subscriber features. Redundancy and synchronization also require sharing of protocol state like DHCP and PPP.
A good redundancy solution also should employ seamless integration with external servers like DHCP/Radius and backend policy/billing systems.
Implementation details
The concept for geo-redundancy is built on top of a sync protocol that is used in MCLAG also: ICCP (inter chassis communication protocol). It is a reliable protocol that allows for state and info sync between 2 chassis.
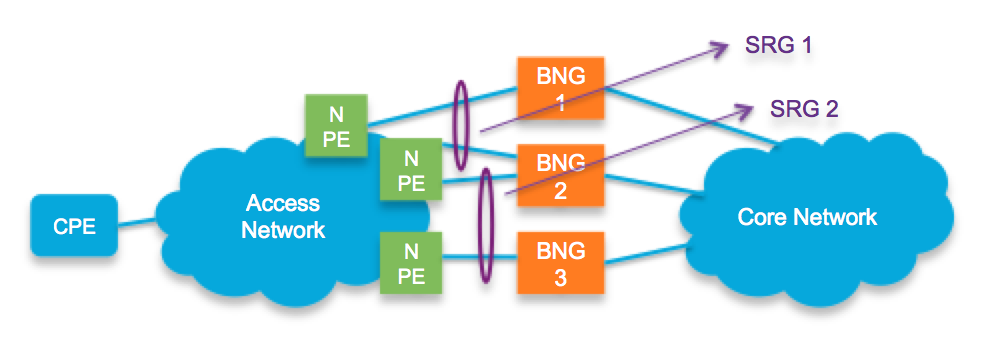
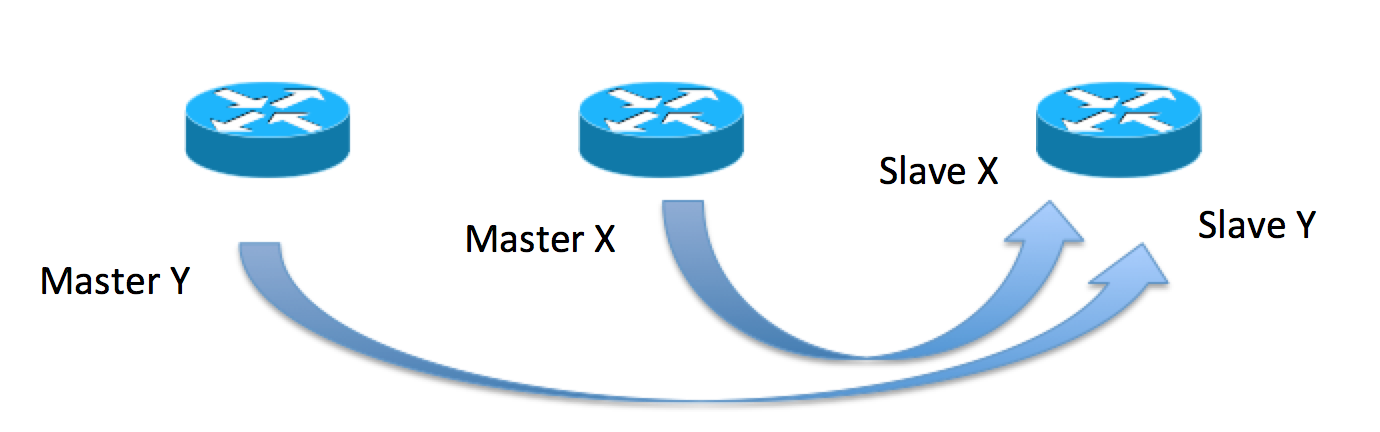
One of the basic pieces to that is the definition of what we in GEORED will call the Subscriber Redundancy Group (SRG).
Taking the picture from above, that shows the M:N or N:1 redundancy topologies, an SRG is the equivalent of the "X" or "Y" arrows:
Synchronization
Synchronization from “master” to “slave” is done over TCP on per SRG basis between routers using proprietary mechanism – BNG Sync
This mechanism serves the following purposes:
- Signaling failures and role changes
- Synchronization of subscriber sessions’ control plane states
- Communication of other events and commands
When BNG SRG peers connect, first the master slave determination is done, after which sync of state happens from master to slave followed by regular mirroring that happens without delay with without holding up the session provisioning on master.
Session mirroring takes care of complete state once the session is up; and when there is any change or when it is deleted
Roles
Master/Slave roles are defined by the SRG and not defined as a BNG router by itself. This simply means that SRG1 can be active on router ONE and SRG2 will be active on router TWO, and SRG1 will be standby on router TWO also.
active/active – (eg the M:N) BNG could be master for one SRG and slave for another
active/standby – (eg the N:1) dedicated backup BNG could be slave for multiple SRGs from different active BNGs which are masters for those respective SRGs
Role negotiated via BNG sync between routers on per SRG level
Where possible, role can be determined by the underlying access technology
In master role BNG will handle and process all control traffic it receives
In slave role BNG will ignore all BNG and related protocols traffic. It will receive state notifications of the session via the ICCP communication from the active node serving that SRG.
Modes of operation
GEORED can operate in two distinct redundancy operations. That is hot and warm standby.
Hot-Standby Mode (default)
Sessions provisioned on slave in sync with setup on master
Since the sessions are actively programmed on the standby, this will consume hardware resources on slave. Proper planning is necessary here, since if we have BNG node X and Y both serving 50k sessions each, the slave node needs to be able to support 100k sessions when they are actively programmed!
Minimal action on switchover; data plane is already setup for sub-second traffic impact, this is the highest level of redundancy you can achieve.
And especially useful in deployments requiring high and tight SLA
Warm-Standby Mode (for over-subscription)
Sessions data kept in “shadow” database on slave in sync with setup on master
Only consumes some additional memory in control plane for the shadow copy – no provisioning in hardware
Upon failover trigger, sessions are setup at rapid pace from shadow copy
This allows for over provisioning on backup for subscribers. While it still provides for a high level of redundancy, and the "outage" or forwarding loss is determined by the time it takes to hw program the sessions served by the SRG, the failover will result in some session loss (if the SRG serves high number of sessions that take longer to program then the keepalive/timeout of the session).
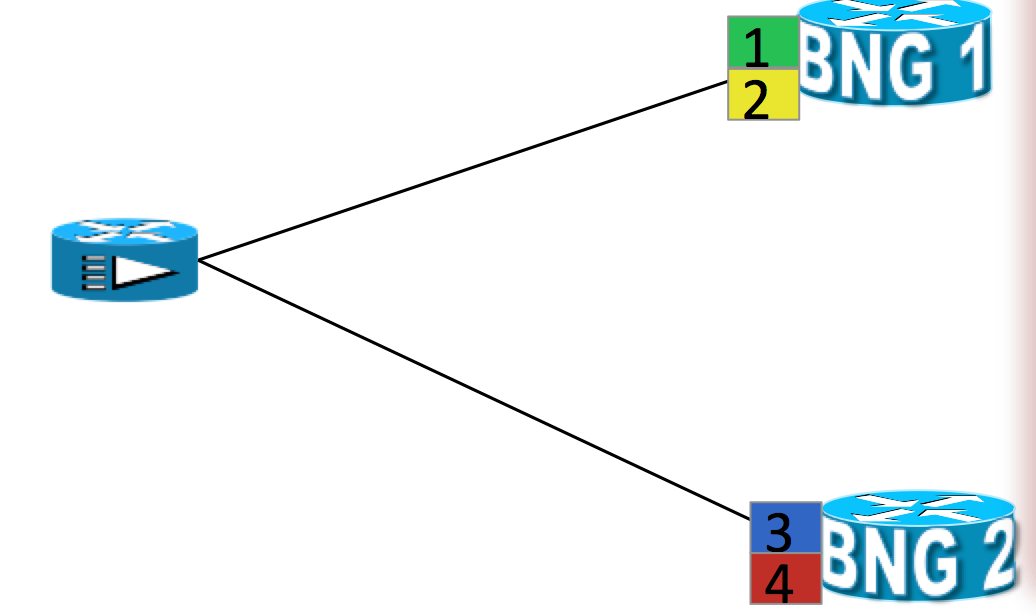
Session distribution
Example scenario with an active/standby, N:1 model:
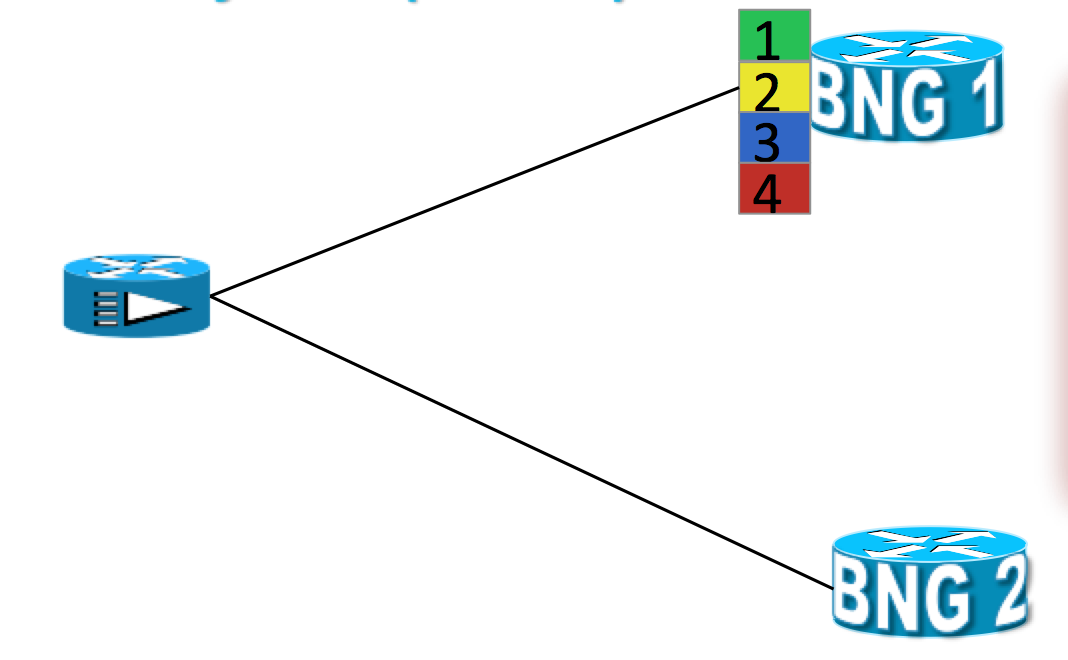
- Sessions are associated with partitions (vlan 1,2,3,4) on BNG1 with each VLAN mapped to different SRG configured with master role
- BNG2 IS acting as backup for all VLANs
- Each VLAN has 8k sessions terminated
Example scenario with an active/active, N:1 model:
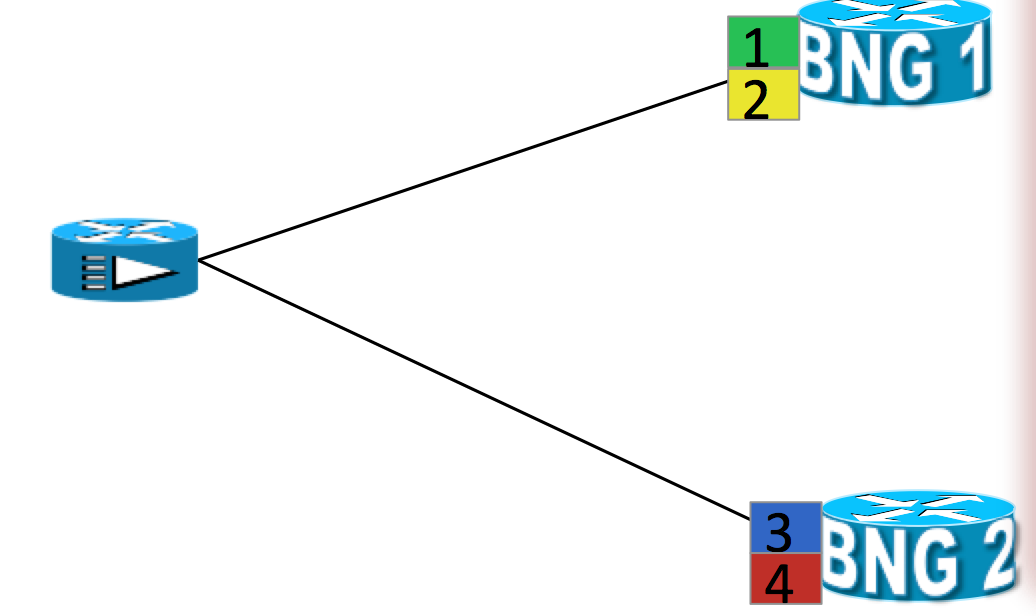
- Sessions are associated with partitions (vlan 1,2) on BNG1 with each VLAN mapped to different SRG configured to Master role
- Sessions are associated with partitions (VLAN 3,4) on BNG2 with each VLAN mapped to different SRG configured to Master role
- Each VLAN has 8 sessions terminated
- Each BNG has 16k session terminated
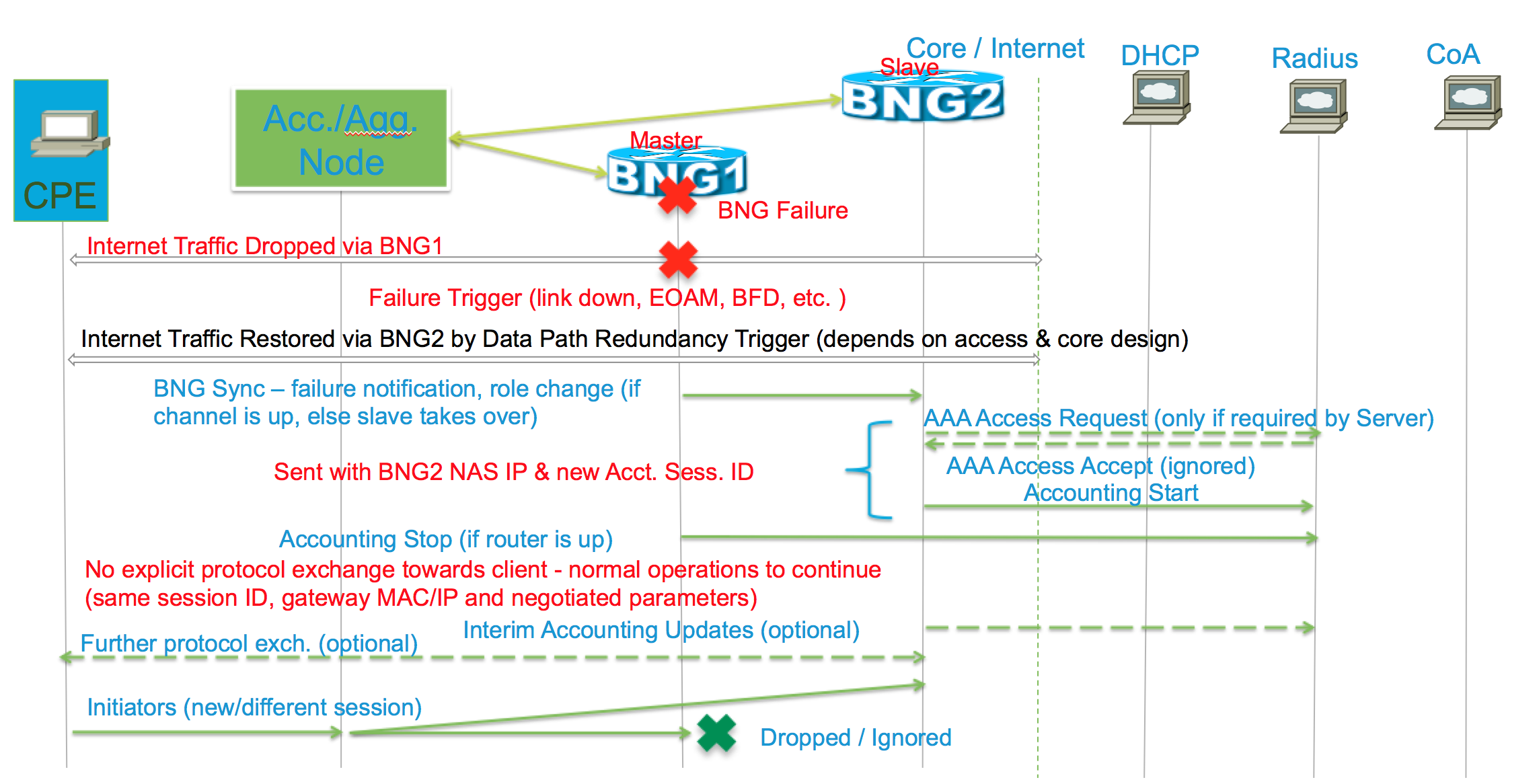
Radius Interaction
some important notes regarding radius accounting and authorization information
- Authentication/Authorization done only from the Master and all profile information is syncd to Slave. Slave does not reach out to radius and relies on the session information received from the active node.
- On Failover, Accounting Stop message is sent from old Master and Accounting Start from New Master.
- NOTE: Accounting Stop from old master sent on best effort basis and ordering is not guaranteed between it and the Accounting Start sent by the new master. A failover session should be handled as two separate sessions by Radius
- Radius (Accounting) messages from BNG are paced with jitter (especially around switchover) to avoid load on the server
Managing upgrades
One of the big advantages of GEORED that overcomes a painpoint of nV cluster is the sw upgrades.
In cluster, an orchestration is necessary to separate the cluster nodes, upgrade one and make a quick switch over to upgrade the other one.
In Geo Redundancy, the BNG nodes can run different sw versions even! and that is no problem. Although we wouldn't recommend too much version disparity between the devices and for the ease of deployment have all BNG nodes in the network, regardless of being part of the GEORED to be on the same sw version as much as possible with the same smu set.
The SW upgrade procedure would be opaque to the redundancy model chosen (N:1, M:N, active/active or active/standby).
Basically the steps include:
- Failover SRG's one by one running active on the BNG node to its standby
- If hot standby, step "1" will be quick. If warm standby allow for some time for the sessions to be programmed
- upgrade the BNG to the desired sw level
- pull back all sessions for the SRG's that need to be running active on this BNG
And do this for all the BNG nodes part of the SRG interaction.
NOTE: you can even setup GEO red just for the upgrade procedure. A node that is synchronizing its sessions during this setup is not affected whatsoever.
Session set up and call flow details
The following section graphs out the call flow and messaging between BNG SRG devices and the session.
Initial Session Setup
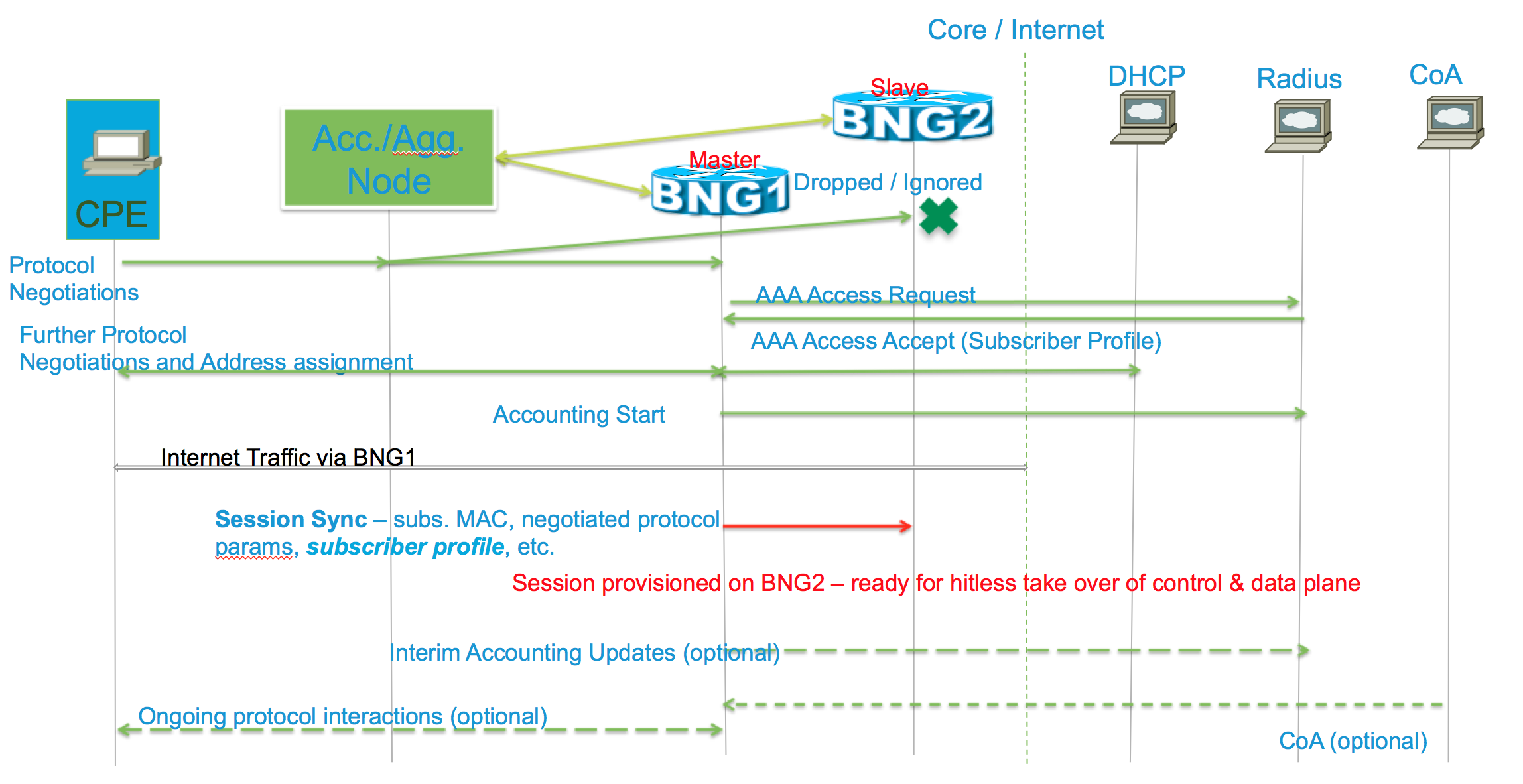
- Only Master does Radius/Policy server interactions for the subscriber using its NAS IP, NAS Port and accounting session ID
- In addition to protocol state, subscriber profile (including any further changes as result of CoA) are sync-ed across from master to slave
- Slave sets up the same subscriber with a different accounting session ID – it has different NAS IP and likely different NAS Port
- Redundancy design and Slave is invisible to Radius/policy server before the switchover. That is the radius/PCRF have no awareness of the fact that a session is synchronized.
Failure scenario
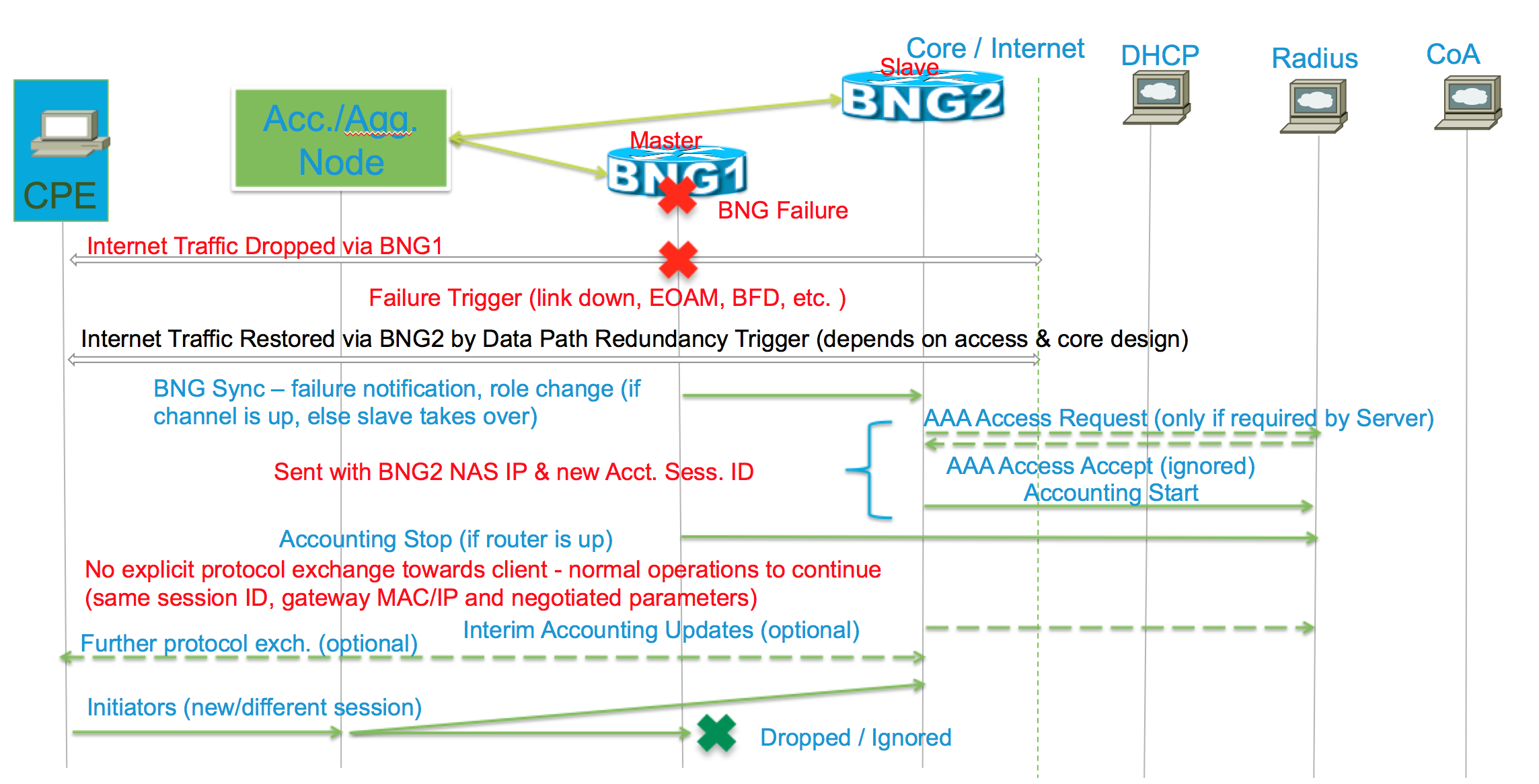
- Subscriber already provisioned on slave and ready to forward traffic even before switchover; Loss on fail-over depends on Access network failover or convergence
- Core network design – fast reroute, BGP PIC, core convergence
- BNG Sync channel used to signal failures and trigger switchovers between BNG routers; this is control plane sync.
- Accounting updates – start/stop/interims
- DHCP state machine on slave takes over without any client/server interactions
- Lease will continue on slave from when master started it
- PPPOE/PPP state machine on slave takes over from where master left without any client impact
- PPP keep-alive will start flowing from new master on takeover
Use cases
MSTAG
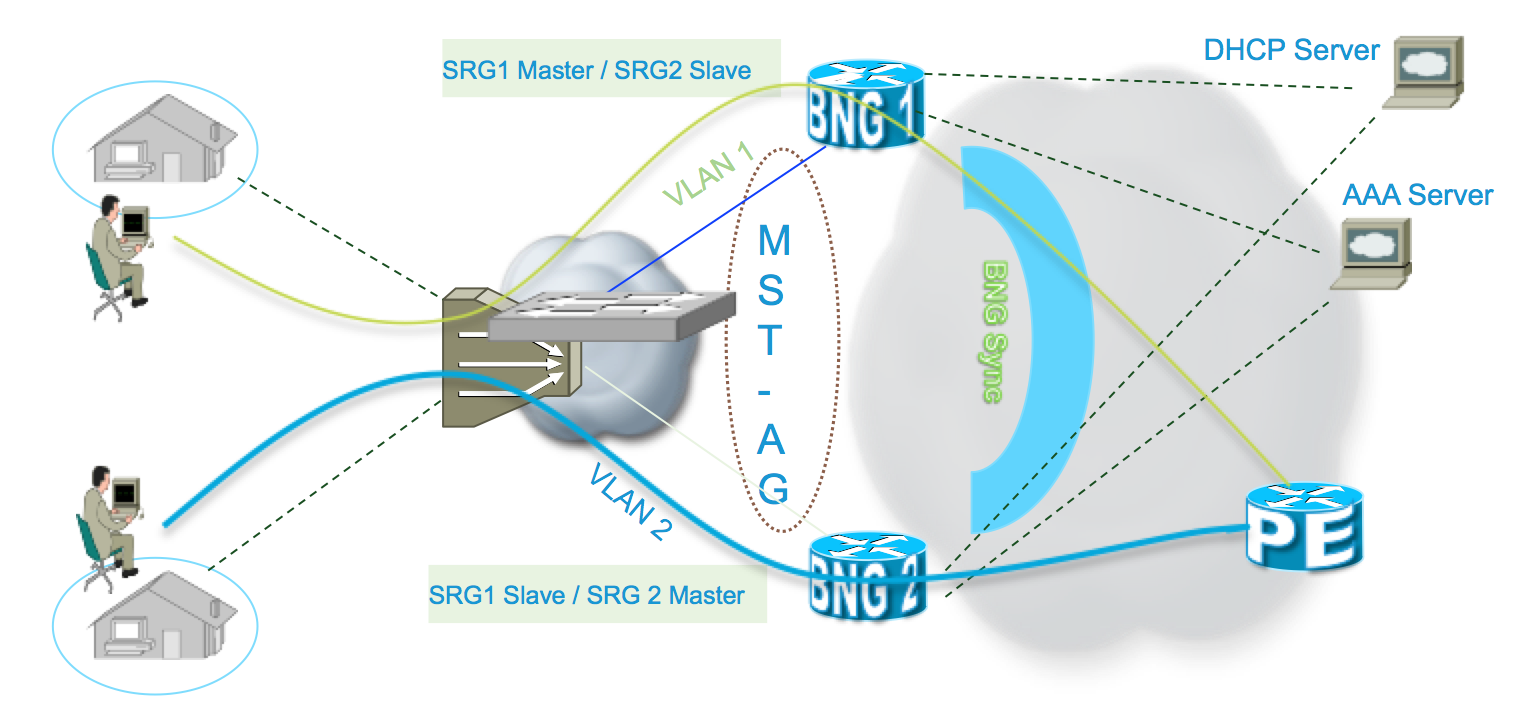
The MSTP protocol is used here to block standby path so we have only one active
In this case each BNG have their own MAC which is used for MST and other Ethernet protocols. In this scenario we need to setup SRG vMAC for BNG sessions. Which will act like an HSRP/VRRP virtual mac in the same facinity. The BNG's use their own mac for the STP communication, we'll use the vmac towards the sessions as their peering/communication point.
For dual homing two MST instances required with VLANs split across them to enable active/active load balancing to each of the 2 BNGs
MST provides “preempt delay” knobs to throttle switchovers and allow stabilization of subscribers on top of it after failure recovery.
Failure detection, or the improved detection for it is done via CFM sessions (at least one per MST instance in any of its VLAN). The CFM session is used to monitor connectivity and to detect which BNG has the forwarding path and which one has the standby/drop path (i.e. CFM session will be UP on active & DOWN on standby)
Coupling the CFM session via EFD with each of the BNG L3 access sub-interfaces on that interface will result in that sub-interface status tracking UP on active side and DOWN on standby side.
Access tracking object monitoring this sub-interface status (which is in turn controlled via EFD based on CFM session) is used for determining SRG role as well as controlling the subscriber subnet route advertisement
In event of failures, as MST re-converges and switches paths, the CFM session status changes and the L3 BNG sub-interfaces get notified of status via EFD such that the SRG role can be switched
MST and CFM timers can be as aggressive as supported by the access devices with stable operations even with full subscriber load
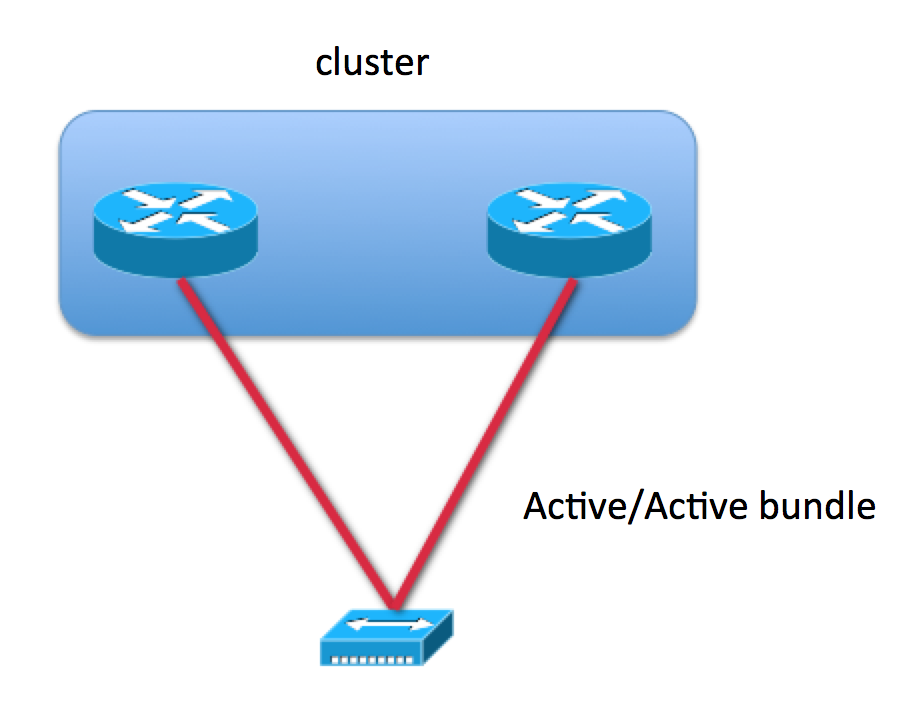
MCLAG
MC-LAG provides consistency of MAC and IP address across the two PoA (i.e. BNG routers). In this scenario there is no need for SRG vMAC since it is managed by MCLAG natively already.
The failure is induced by an object that directly tracks MC-LAG bundle interface status and signals to both SRG (for role determination) & the routing entity (to control the subnet/pool advertisement).
MC-LAG provides knobs to throttle switchovers and allow stabilization of subscribers on top of it in event of link flaps and after failure recovery
Parameters to consider when using MCLAG:
mlacp switchover recovery-delay – to ensure bundle remains slave after recovery from failure and allows subscribers to get sync and stabilized on it in slave mode
mlacp switchover type revertive – means that when the primary comes back, it will assume the primary role also and basically pull everything from the standby back. Like HSRP preempt.
lacp switchover suppress-flaps – to avoid switchover for transient link-flaps
BFD or CFM with EFD can be used for faster detection of failures in addition to LACP protocol mechanisms
LAC
Configuration and setup
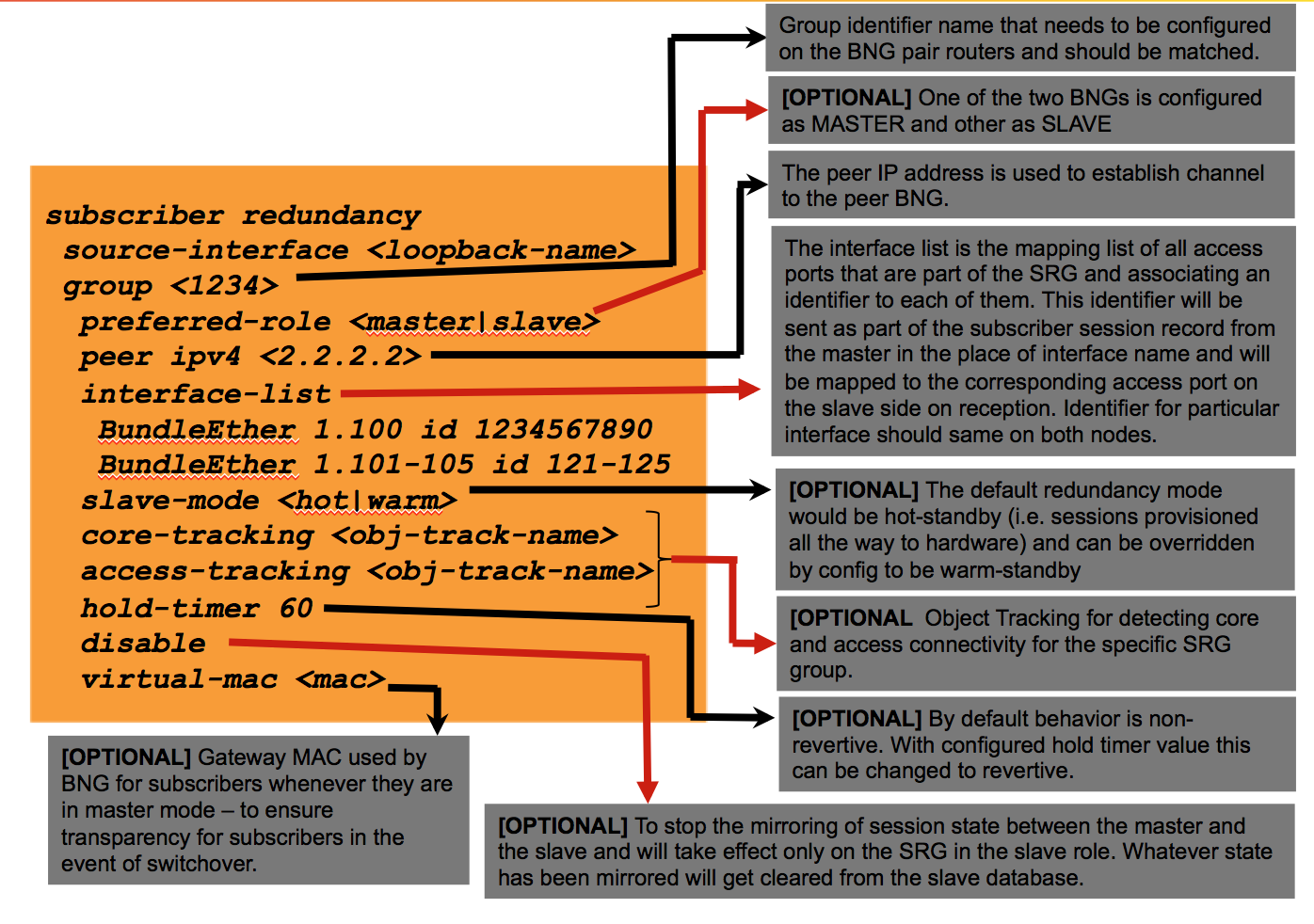
Now that you know everything about GEORED you want to go set it up right?! Here is a config piece and explanation what it is for.
| Enable BNG GEo Redundancy |
group 1 peer 1.1.1.1 |
|
Set up SRG and define which group holds which interface. Multiple groups can be defined. |
subscriber redundancy group 1 interface-list interface bundle-ether1 id 1 |
|
Setup Access Object Tracking for SRG and Summary Subscriber route. In this example we are tracking the interface bundle state that MCLAG is providing to us. If we see that the state is going down, that will result in a static route withdraw from the table. If we have redistribute static configured, the pool summary will be removed so that the previous standby, now active can start advertising the summary to start pulling the traffic. |
track access-mclag type line-protocol state interface bundle-ether1 subscriber redundancy group 1 access-tracking access-mclag router static address-family ipv4 unicast 10.0.0.0/24 null0 track access-mclag desc sub-pool-summ |
| Optional SRG configuration to determine more deterministically what the preferred role is and what redundancy mode should be run. |
subscriber redundancy preferred-role master slave-mode warm hold-timer 15 |
A little more detail of the subscriber redundancy configlet
Restrictions and limitations
As with everything in technology, there is always some trade off. This table below is what exists currently as know restrictions for the GEORED solution as of XR 5.3.3
Note that XR6 has quite a significant amount of improvements, that will be documented separately. Since XR 5.3.3 is the going release today for ASR9000 I thought it is important to know what you get and where you need to think about.
|
Limitation |
Recommendation |
|
With just Core tracking, if core interface goes down, SRG switchover is triggered causing traffic black hole on access |
EEM script can be used to shut access when core goes down |
|
RA will send with both SRG vMAC as well as interface MAC towards access |
use RA preference CLI under dynamic template or access-interface |
|
Accounting records may get lost if we do back-to-back switchover before they sync on master and slave |
we should wait for 15 mins before doing Switchover (128k sessions) |
|
Admin clear of sessions from the slave is prohibited |
1. If slave is out of sync from master, subscriber redundancy synchronize command can be issued from slave to replay
2. SRG clear command can be issued either from slave or Master to get slave back to normal state |
|
Master reload is not recommended on the access with non-revertive protocol support |
Enable revertive configuration on the access-protocol |
|
On flight vmac modification for IPv6 sessions is not supported |
Features not supported:
- Static subscriber
- DHCP Routed subscriber
- Packet trigger Sessions
- Multicast on subscriber and Qos Correlation
- SLAAC for subscriber
- BNG as DHCP server
- IPv6 ND as SRG client
- Diameter & Geo-redundancy interworking (6.2.x)
XR6 enhancements details
Miscellaneous
With great thanks to the GEORED dev team for some of the visualizations used in this paper.
PS. it is highly important not to use pppoe bba-group Global. This is a reserved keyword that is known to break certain SRG cases. name your bba-group to anything but global/Global.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Dear All,
We have issue when Core link recovery happens, when
Synchronization can be only via the Core link.
BNG1 core link goes down, all groups get the Slave role.
BNG2 loss Sync after timeout (~30sec) and all groups get Master role.
BNG1 core link recovers, Core Tracking goes up. All groups take Master role.
~10 seconds routing/MPLS up, SRG Sync recovers. Now both BNGs Master in all groups.
BNGs take Master role for groups preferred role master.
So, without synchronization failed BNG takes Master role where preferred. After recovery there are many session losses! CPEs recovers after lease expires.
After it there are many Sync error/warning sessions.
We found a solution, to configure 60 seconds delay in Core-tracking.
With it BNG1 Core link recovers but tracking stays Down. Routing/MPLS/SRG sync recovers ~10sec.
After 60 sec Core tracking Up. No role changes happen, but revertive-timer starts.
After revertive-timer expires, Preferred Master roles taken.
Use IPoE sessions with eXR 6.5.3 and upgrading to eXR 6.6.3 soon.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi All,
Anyone using SERG pool synchronization?
I have an issue, using 6.5.3 eXR with PPPoE.
If one BNG goes down, other takes master role.
BNG can not allocate IP address from pool on which it is the preferred slave. (but Master the current state)
I could overcome this situation to configure all groups on both sides as preffered master for the SERG pools!
PPP-MA[404]: %L2-PPP_MA-4-ERR_DAPS_IF : Bundle-Ether22000.403.pppoe318: Unexpected error encountered whilst Callback obtaining address 0.0.0.0: 'ip-daps' detected the 'warning' condition 'Warning: serg down, Address allocation failed'
sh session-redundancy group
---------------------------------------------------------------------------------------------------
Node Name | Group ID | Role | Flags | Peer Address | P/S | I/F-P Count | SS Count | Sync Pending
---------------------------------------------------------------------------------------------------
0/RSP1/CPU0 61 Master ESH- 10.162.200.204 T 2 0 0
0/RSP1/CPU0 62 Master EMH- 10.162.200.204 T 2 0 0
-----------------------------------------------------------------------------------------------------------------------
Session Summary Count(Master/Slave/Total): 0/0/0
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi, Xander:
In the 6.2 geored documentation, it says that MCLAG is recommended only for IPv4 subscriber sessions. What would be the redundancy environment recommended for IPv6 sessions? What is the problem with MCLAG and IPv6?
Thanks!
c.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
it would be good however to be on a more recent release like xr7 to leverage some of this BNG improvements.
cheers!
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Got it. Thank you very much for taking the time. @xthuijs
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi, Xander:
I'd like to ask your opinion regarding a possible revertive environment where you are using MCLAG as access redundancy technology. Both geored and mlacp have their timers, right?
I'm tracking my bundle interface and using that tracking for geored. I'm matching the timers for both geored and mlacp at 60s in my implementation. Is this the correct way of doing it? I ask because I see some erratic behavior when the environment reverts to its original state. Sometimes I basically lose no traffic and sometimes around 15-20s worth of traffic. I think we can live with the latter, but I thought I'd ask you if I'm missing something to make it more stable.
Thanks!
Carlos.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
in the geodred config you can add the interface to track that is a good option to use so that the geored state automatically follows
the interface state which is controlled by mclag.
xander
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Xander,
I have one questions about Geo-R. A big ISP would like to introduce Geo-R and they are asking about the max. latency between the BNG? I couldn't find it in the guides on cisco.com.
Could you let me know about the max latency for the link between the BNGs, because they would like to have proper Geo-R where the devices are hundreds of kilometers away.
 - Emeritus")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
hi Smail,
BNG Sync session is running over TCP. The isolation detection timer is set to 30 seconds (== TCP keepalive timeout). This is not configurable. So the isolation detection timer is long enough for it not to be a key factor in deciding how far can the two peers be. A more important factor is to enable quick and reliable comms between them, to keep the subscriber states in sync. Proper QoS along the path will be important if the peers are many hops away.
Hope this helps,
/Aleksandar
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Aleks,
thank you very much for the reply. It is good news that it is using TCP.
- « Previous
- Next »
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: