- Cisco Community
- Technology and Support
- Data Center and Cloud
- Application Centric Infrastructure
- Re: COOP issue , EP not updated
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 12:55 AM - edited 01-25-2022 12:56 AM
Hello,
We have some issues with end point update.
We have a multi pod architecture with 3 pods.
When I move an EP from POD2 to POD1, the POD1 leaf can see the new EP but the POD2 leafs are not updating.
I suspect a COOP issue, and i see this error on COOP protocol on the POD2 Spines :
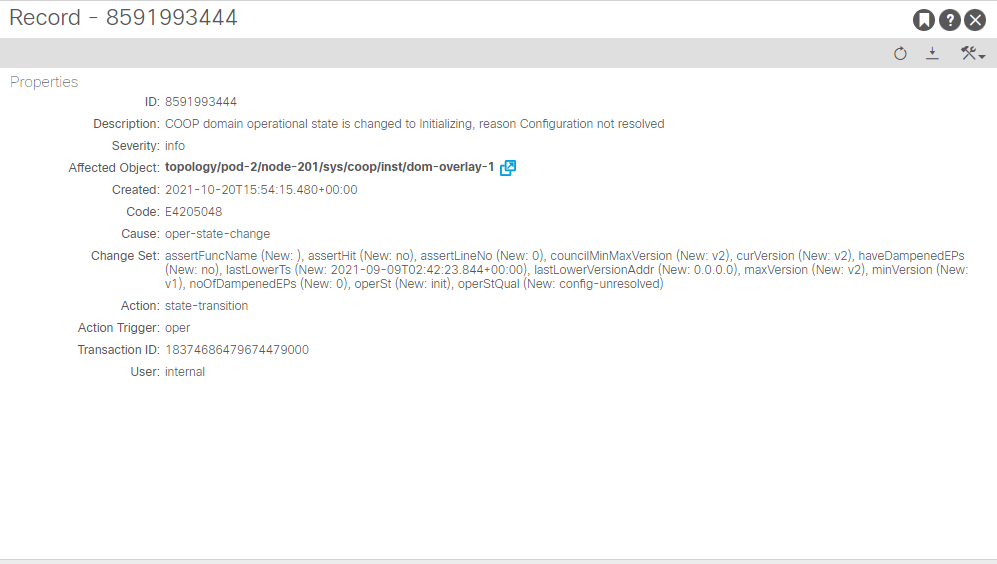
Operationnal state : initializing
Operationnal state qualifier : Configuration not resolved
We don't have any coop issue on POD1 et POD3, only on POD2
Is there a way to go deeper , reset COOP , restart something ?
I'm not an expert for COOP management
Thanks a lot
Maxime
Solved! Go to Solution.
- Labels:
-
Cisco ACI
Accepted Solutions

")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 06:01 AM - edited 02-02-2022 10:26 PM
For some reasons, it looks like "MPOD-CONFIGURED" flag is missing from the POD2.
Did any multi-pod related config changed?
First of all, although I was not able to find any external bugs related to this issue, I would suggest you open a TAC case.
If that is not an option, for whatever reasons, or you can do it but after you resolve first the problem, I would suggest you collect show tech-support files from all the spines & APICs.
Second of all, what I would do to try and recover from this state would be in this order:
1. Reload Spine201 - this is the COOP master
2. If not resolved, reload Spine202
3. If not resolved, clean reload of one spine at a time ("setup-clean-config.sh" + "reload" commands in CLI)
Hope this will solve your problem.
Stay safe,
Sergiu
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-01-2022 12:00 AM
Hi all
An update on this case.
The coop database seems ok now. I've reloaded the 2 POD spines and now MPOD-CONFIGURED flag is now present and I haven't any errors anymore.
When I move ands EP from POD to POD1 everything seems ok, POD1 leaf update and see the EP as local and POD2 bounce and see the EP through the tunnel.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 01:41 AM
Hi,
Is this a new setup? Was it working before? What version do you run in your fabric? Do you have the BGP RR configured?
Thanks,
Sergiu
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 01:54 AM - edited 01-25-2022 01:57 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 02:46 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 03:22 AM
We have 2 spines in POD2 :
First one :
S201# show coop internal info global
System info:
Local Adjacency (Pythia)
Flags status: f9 or_cfg: 1 ,
L2RIB Sharding status : L2RIB Sharding status : L2RIB Sharding status : L2RIB Sharding status : Addr : 10.192.16.64
Identity : 0.0.0.0
Name : overlay-1
HelloIntvl : 0
Operational St: 0
Last Contact : 0
Primary Key : 44274
Flags : 0x0
Shard Info:
Master Itvl [0x7fffffff, 0xffffffff]
Backup Itvl [0x0, 0x7ffffffe]
L2RIB MPOD Shard Itvl [0x7fffffff, 0xffffffff]
Minimum supported version : 1
Maximum supported version : 2
Running version : 2
Connection Mode : Compatible
Citizen Prefix : 10.192.0.0/16
Potential Upgradeable Version : 2
Last Citizen Lower Version TS : N/A
Last Citizen Lower Address : None
Time To Next Upgrade : 0 seconds
Max value of the minimum version advertised by all oracles : 1
ISIS Fabric Link State : UP
vpod-vSpine: 0, vpod-vTor 0, vpod_vPodId 2
vspine_hrep_alloc_allowed: No
vpod_subnet_count 0
vpod_mcast_hrep active count 0
Oracle Adjacency (Dodona)
Addr : 10.192.16.65
Identity : 0.0.0.0
Name : S202
HelloIntvl : 60
Operational St: 2
Last Contact : 1643109452
Primary Key : 45184
Flags : 0x0
Oracle Status : UP-ACTIVE , , , ,
Flags status: 5fbf or_cfg: 17 Illegal Pings: 0
Shard Info:
Master Itvl [0x0, 0x7ffffffe]
Backup Itvl [0x7fffffff, 0xffffffff]
L2RIB MPOD Shard Itvl [0x0, 0x7ffffffe]
Minimum supported version : 1
Maximum supported version : 2
Running version : 2
Non-secure TCP connected : Y
Secure TCP connected : Y
Secure CZ TX TCP connected : N
Non-secure TCP accepted : Y
Secure TCP accepted : Y
Secure CZ TX TCP accepted : N
Non-secure TCP ACTIVE : N
Secure TCP ACTIVE : Y
Second one :
S202# show coop internal info global
System info:
Local Adjacency (Dodona)
Flags status: f9 or_cfg: 0 ,
L2RIB Sharding status : L2RIB Sharding status : L2RIB Sharding status : L2RIB Sharding status : Addr : 10.192.16.65
Identity : 0.0.0.0
Name : overlay-1
HelloIntvl : 0
Operational St: 0
Last Contact : 0
Primary Key : 44473
Flags : 0x0
Shard Info:
Master Itvl [0x0, 0x7ffffffe]
Backup Itvl [0x7fffffff, 0xffffffff]
L2RIB MPOD Shard Itvl [0x0, 0x7ffffffe]
Minimum supported version : 1
Maximum supported version : 2
Running version : 2
Connection Mode : Compatible
Citizen Prefix : 10.192.0.0/16
ISIS Fabric Link State : UP
vpod-vSpine: 0, vpod-vTor 0, vpod_vPodId 2
vspine_hrep_alloc_allowed: No
vpod_subnet_count 0
vpod_mcast_hrep active count 0
Oracle Adjacency (Pythia)
Addr : 10.192.16.64
Identity : 0.0.0.0
Name : S201
HelloIntvl : 60
Operational St: 2
Last Contact : 1643109752
Primary Key : 45632
Flags : 0x0
Oracle Status : UP-ACTIVE , , , ,
Flags status: 5fbf or_cfg: 15 Illegal Pings: 0
Shard Info:
Master Itvl [0x7fffffff, 0xffffffff]
Backup Itvl [0x0, 0x7ffffffe]
L2RIB MPOD Shard Itvl [0x7fffffff, 0xffffffff]
Minimum supported version : 1
Maximum supported version : 2
Running version : 2
Non-secure TCP connected : Y
Secure TCP connected : Y
Secure CZ TX TCP connected : N
Non-secure TCP accepted : Y
Secure TCP accepted : Y
Secure CZ TX TCP accepted : N
Non-secure TCP ACTIVE : N
Secure TCP ACTIVE : Y
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 03:33 AM
and we have some difference with the POD1 , where we have no issues ...
S101# show coop internal info global
System info:
Local Adjacency (Dodona)
Flags status: f9 or_cfg: 0 ,
L2RIB Sharding status : MPOD-CONFIGUREDL2RIB Sharding status : L2RIB Sharding status : L2RIB Sharding status : Addr : 10.191.152.65
Identity : 0.0.0.0
Name : overlay-1
HelloIntvl : 0
Operational St: 0
Last Contact : 0
Primary Key : 44318
Flags : 0x0
Shard Info:
Master Itvl [0x0, 0x7ffffffe]
Backup Itvl [0x7fffffff, 0xffffffff]
L2RIB MPOD Shard Itvl [0x0, 0x7ffffffe]
Minimum supported version : 1
Maximum supported version : 2
Running version : 2
Connection Mode : Compatible
Citizen Prefix : 10.191.0.0/16
ISIS Fabric Link State : UP
vpod-vSpine: 0, vpod-vTor 0, vpod_vPodId 1
vspine_hrep_alloc_allowed: No
vpod_subnet_count 0
vpod_mcast_hrep active count 0
Oracle Adjacency (Pythia)
Addr : 10.191.152.64
Identity : 0.0.0.0
Name : S102
HelloIntvl : 60
Operational St: 2
Last Contact : 1643109592
Primary Key : 45466
Flags : 0x0
Oracle Status : UP-ACTIVE , MPOD-CONFIGURED, , ,
Flags status: 7fbf or_cfg: 15 Illegal Pings: 0
Shard Info:
Master Itvl [0x7fffffff, 0xffffffff]
Backup Itvl [0x0, 0x7ffffffe]
L2RIB MPOD Shard Itvl [0x7fffffff, 0xffffffff]
Minimum supported version : 1
Maximum supported version : 2
Running version : 2
Non-secure TCP connected : Y
Secure TCP connected : Y
Secure CZ TX TCP connected : N
Non-secure TCP accepted : Y
Secure TCP accepted : Y
Secure CZ TX TCP accepted : N
Non-secure TCP ACTIVE : Y
Secure TCP ACTIVE : Y
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 06:01 AM - edited 02-02-2022 10:26 PM
For some reasons, it looks like "MPOD-CONFIGURED" flag is missing from the POD2.
Did any multi-pod related config changed?
First of all, although I was not able to find any external bugs related to this issue, I would suggest you open a TAC case.
If that is not an option, for whatever reasons, or you can do it but after you resolve first the problem, I would suggest you collect show tech-support files from all the spines & APICs.
Second of all, what I would do to try and recover from this state would be in this order:
1. Reload Spine201 - this is the COOP master
2. If not resolved, reload Spine202
3. If not resolved, clean reload of one spine at a time ("setup-clean-config.sh" + "reload" commands in CLI)
Hope this will solve your problem.
Stay safe,
Sergiu
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 06:47 AM
multipod config didn't change
reload is planned on thursday morning ( need to plan it during some specific periods here)
I will update this post after that
If reload don't resolve the issue i will open a TAC case.
Thanks for your help
Maxime
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 07:19 AM
Make sure you collect the show tech files. Do them as fast as possible (now?) to avoid loosing any critical data/logs.
Keep us updated with the results!
Thanks,
Sergiu
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-01-2022 12:00 AM
Hi all
An update on this case.
The coop database seems ok now. I've reloaded the 2 POD spines and now MPOD-CONFIGURED flag is now present and I haven't any errors anymore.
When I move ands EP from POD to POD1 everything seems ok, POD1 leaf update and see the EP as local and POD2 bounce and see the EP through the tunnel.
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide


{kind=link}