- Cisco Community
- Technology and Support
- Collaboration
- Collaboration Knowledge Base
- Database Communication Error when Logging in to the Cisco Unified Communications Manager Publisher S...
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-06-2012 07:26 AM - edited 03-12-2019 09:53 AM
[PROBLEM]:
In a Cisco Unified Communications Manager cluster that has a few subscribers and a publisher, when you try to login to the publisher after entering the username and password, the [Database Communication Error] error message appears>
TO VIEW, HOW THE ERROR LOOKS_LIKE & WHERE IT DISPLAYS, DOWNLOAD THE ATTACHED FILE 1.PNG (AT LAST OF THIS DOC)
Database Communication Error when Logging into the Cisco Unified Communications Manager Publisher Server:
When trying to login to the Cisco Unified Communications Manager (CUCM) Publisher server, the [Database Communication Error] error message appears. This document provides information, how to troubleshoot this issue>
To Troubleshoot this issue, Cisco Recommends that you must have knowledge of these topics:
· Cisco Unified Communications Manager 6.1 and later
- Solution 1>
1. Revert the changes made back to the old settings in order to let you log in.
2. Go to Cisco Unified CM Administration > System > Server and make the required changes for the hostname or IP address.
3. Make the same changes via CLI or the OS admin page. The CUCM will restart itself.
4. After restarting check if services are loaded properly.
5. Use the utils service list CLI command in order to check if the services are up and running.
6. Restart the whole cluster manually again to have all the services loaded properly.
___________________________________
- Solution 2>
If there were no changes made to the CUCM Publisher and you still receive the Database Communications Error error message, then complete this procedure to resolve the issue:
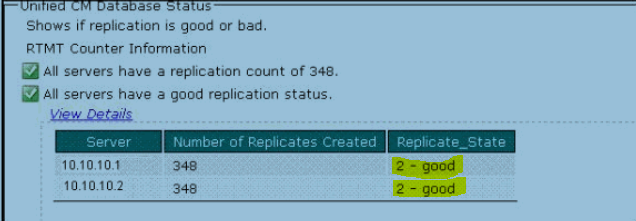
1. Check the database replication status on all the CUCM nodes (publisher and each subscriber) in the cluster to ensure that all servers replicate database changes successfully. You can check the replication state with RTMT by accessing the Database Summary and inspecting the replication status.
The Number of Replicates Created and State of Replication object provides information about the replication state on the system. Status 2 indicates that the replication is good. If you receive a status number of 3 or 4, it indicates either a broken database or that replication is not set up correctly between the publisher and subscribers.
If the Database Summary indicates that the replication on the Publisher is 2 and on the Subscribers is 3, go to the next step.
2. Check the DB replication using the utils dbreplication status CLI command and check what the output shows. If there are mismatched rows reported in the output file, run the utils dbreplication repair all CLI command to synchronize tables on all nodes.
3. Run the utils dbreplication stop command in all the subscribers and on the publisher. Then run the utils dbreplication reset all to reset replication on publisher and all subscribers. This command might take some time to complete.
4. After you run the commands, Verify it in RTMT. If the replication status shows 2 for both the Publisher and the Subscribers, then the issue is resolved.
[ IT SHOULD LOOK LIKE 2.PNG, ATTACHED FILE ]
You should be able to login to the Publisher and Subscribers without any error.
Note: If the issue is not resolved after you complete the above steps, restart the DBL service.
_________________________________________________________
Problem>
- A problem that can occur is the inability to access the Cisco Unified CM administration page of the publisher from the site because of database communication error informix not accepting any more connections. All connections are eaten by dbcef.
The utils dbreplication runtimestate does not work:
admin:utils dbreplication runtimestate
Traceback (most recent call last):
File "/usr/local/cm/bin/DbReplRTstate.py", line 578, in ?
fin = open(tfile, 'r')
IOError: [Errno 2] No such file or directory: '/var/log/active/cm/trace/dbl/sdi/getNodes'
- This issue is also documented by Cisco bug ID CSCtl74037 (For Registered Customers Only).
Solution>
- It appears this network's disconnects/flaps can help this issue to appear as connections between CEF and DB are not properly closed. The CEF connection leak occurs mainly in these two cases:
> There is a pub−sub cluster, and the network goes down. The CEF service is stopped on the pub. As a result, the subscribers run an algorithm to determine the host who will take over those tasks.
> In order to resolve this from the CLI, issue the command:
- · utils service stop A Cisco DB
- · utils service start A Cisco DB
- · Stop the CEF service from serviceability page
_________________________________________________________
This Document is Based on these Software & Hardware Versions:
CUCM 7.0.2
Source: Document ID: 111040 (Updated: Nov 18, 2009)
Thanks:
Mohit Grover
- =
- ?
- administration
- administration_error_login
- call
- cisco_error_login_cucm
- cisco_grover
- cisco_micky
- cisco_mohit
- cisco_mrvbrothers
- cisco_unable_to_login
- cli_error
- cluster_error_unable_to_login
- cm
- communication
- cucm_login_error
- cucm_publisher_error
- cucm_will_restart_itself
- database
- dbreplication
- error
- error_cisco
- error_login_cucm
- error_login_unified_administration
- grover_cisco
- grover_micky
- grover_mohit
- gui_error
- gui_error_cucm
- http://www.facebook.com/groups/unified.communications
- http://www.facebook.com/unifiedtechnology
- informix
- login_error_publisher
- micky_cisco
- micky_grover
- mohit_cisco
- mohit_grover
- mrvbrothers
- mrvbrothers_cisco
- mrvunity_cisco
- no
- or
- os_admin_page_error
- password_error
- password_username_error
- publisher_login_error
- publisher_publisher
- restart_error
- restart_the_ser
- restart_the_whole_cluster_manually
- server
- subscribers_cucm_error
- subscribers_error_cucm
- such
- system
- traceback
- troubleshoot_login_issue
- unable_to_login_cucm
- unified
- unified_technology
- unified_technology_cisco
- username_password_error
- utils
{kind=link}
{kind=link}
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: