- Cisco Community
- Technology and Support
- Data Center and Cloud
- Data Center Switches
- Questions about N1Kv design and software upgrade disruption
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Questions about N1Kv design and software upgrade disruption
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-05-2010 10:42 AM
Three questions on Nexus 1000v for the brains in this forum:
First, the 4.0(4)SV1(1) documentation, all N1Kv design guides, and the Nexus 1000v training curriculum all hammer home the point that packet, control, and management must be different VLANs. However, the 4.0(4)SV1(2) docs non-chalantly state that "Cisco recommends that you use the same VLAN for control, packet, and management." What's the story behind this total about-face?
Second, what sort of ESX cluster disruption can be expected during a Nexus 1000v software upgrade? Our planned environment is a bit unusual. Each ESX host has a vswitch for the SC and the VM networks used by VSM/vCenter. Each host also has a VEM dvswitch that all other VM's use.
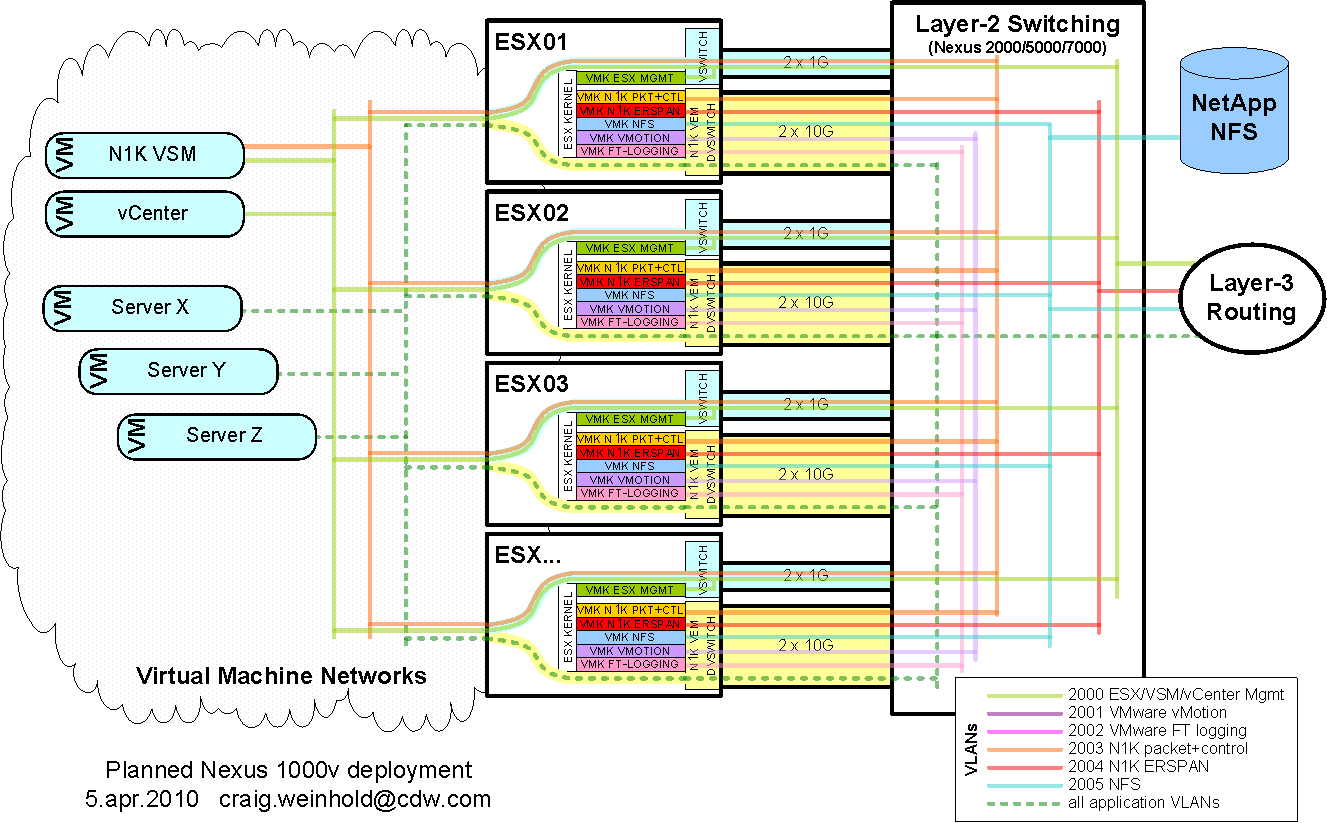
Nondisruptive VEM upgrades should be pretty easy, especially with DRS (move VM's off a host, upgrade its VEM, move the VM's back). However, the VSM upgrade itself will cause an outage. My understanding is that the outage occurs not when the VSM and VEM become disconnected, but when they reestablish connectivity and the VEM must be reprogrammed. Is this disruption a subsecond hiccup, a 1-5 second blip, or a 5+ second outage? Is this disruption longer if there are more VEM's?
Third (and related), could system VLANs be used to minimize the upgrade disruption? The docs state that "System VLANs must be used sparingly," but what is the real danger of defining all VLANs as system VLANs? It seems that it might be a good thing to ensure the VLANs are up and usable by VM's, even during a VSM upgrade process.
Thanks,
-Craig
- Labels:
-
Nexus 1000V
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-05-2010 11:34 AM
Scratch original message, some interesting quotes that are making me wonder about what I had originally thought. I'm interested to know if there is an intrusive period during VSM/VEM reconnect (post-VSM upgrade) as well, and if so, what the duration is.
If you did not shutdown the VMs during the VSM upgrade, and the following conditions are met:
- The system is now in a state where it is running software release 4.0(4)SV1(2) on the VSM.
- All the modules running software release 4.0(4)SV1(1) are reconnected properly.
Then you may use Vmotion of the VMs to avoid further service interruption while the VEMs are
upgraded. This applies to VMs that do not have VSMs.
Similar discussion here: https://communities.cisco.com/thread/9565?tstart=30
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide
