- Cisco Community
- Technology and Support
- Collaboration
- IP Telephony and Phones
- CUCM 8.6.2 to 10.5 Upgrade Fails at Installing DB Component
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
CUCM 8.6.2 to 10.5 Upgrade Fails at Installing DB Component
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-08-2019 07:31 AM - edited 12-08-2019 02:20 PM
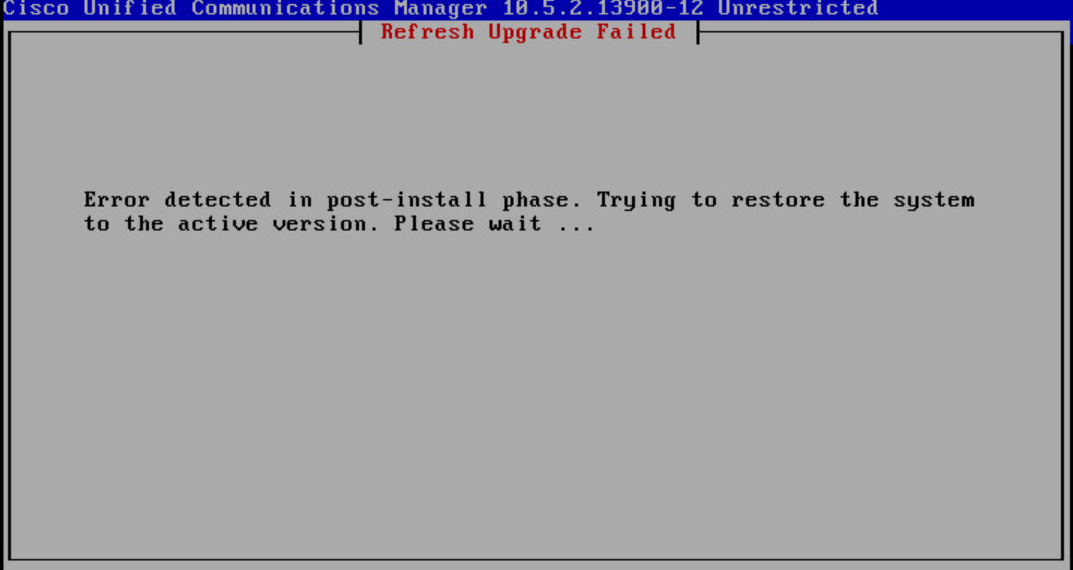
The following is the message I get when the post install / installing db components are at about 83% complete. I have rebuilt the server as multiple TAC cases have revealed that my CUCM server is possibly corrupted. This is the exact same thing that happened before the server was rebuilt.
The installation has encountered a unrecoverable internal error. For further assistance report the following information to your support provider.
"/usr/local/cm/script/cm-dbl-install RU PostInstall 10.5.2.18900-15 8.6.2.20000-2 /usr/local/cm/ /common/component/database /common/log/install/capture.txt " failed (1)
The system will now halt.
Sifting through the install logs more I find this:
12/08/2019 08:24:49 IPM|Internal Error, File:ipm.c:2011, Function: ipmReadNormalizedInputLine(), "/usr/local/cm/script/cm-dbl-install RU PostInstall 10.5.2.18900-15 8.6.2.20000-2 /usr/local/cm/ /common/component/database /common/log/install/capture.txt " failed (1)|<LVL::Critical>
12/08/2019 08:24:51 IPM| end-of-session "Installing database component": 1094.434 secs.|<LVL::Info>
12/08/2019 08:24:51 IPM|Close progress meter "Component Install"|<LVL::Info>
12/08/2019 08:24:51 component_install|Writing database into /common/log/install/component_failed.xml file.|<LVL::Info>
12/08/2019 08:24:51 component_install|File:/opt/cisco/install/bin/component_install:817, Function: exec_progmeter(), /opt/cisco/install/bin/progmeter failed (1)|<LVL::Error>
12/08/2019 08:24:51 appmanager.sh|Internal Error, File:/usr/local/bin/base_scripts/appmanager.sh:276, Function: refresh_upgrade(), failed to refresh_upgrade infrastructure_post components|<LVL::Critical>
12/08/2019 08:24:51 post_install|File:/opt/cisco/install/bin/post_install:1021, Function: install_applications(), /usr/local/bin/base_scripts/appmanager.sh -refresh-upgrade failed (1)|<LVL::Error>
Any insight would be greatly appreciated, I am running
CUCM 8.6.2
1 Publisher, no subs
~ 250 Phones
VMWare 5.5
I went ahead and posted my trace logs from database and install / upgrade
- Labels:
-
Unified Communications
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-08-2019 11:32 PM
I would strongly suggest to open a TAC case with Cisco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-09-2019 02:23 AM
I am assuming you have already checked the used/available disk space.
You might want to reduce the syslogging size on the nodes.
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide