- Cisco Community
- Technology and Support
- Security
- Network Security
- Patching and enabling a port on ASA caused outage
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-07-2017 12:57 AM - edited 03-12-2019 02:28 AM
Hi,
I've recently taken over working on one of our clients from the previous tech and have been tasked with providing a post incident review - involving determining the root cause of an outage involving a Cisco ASA firewall.
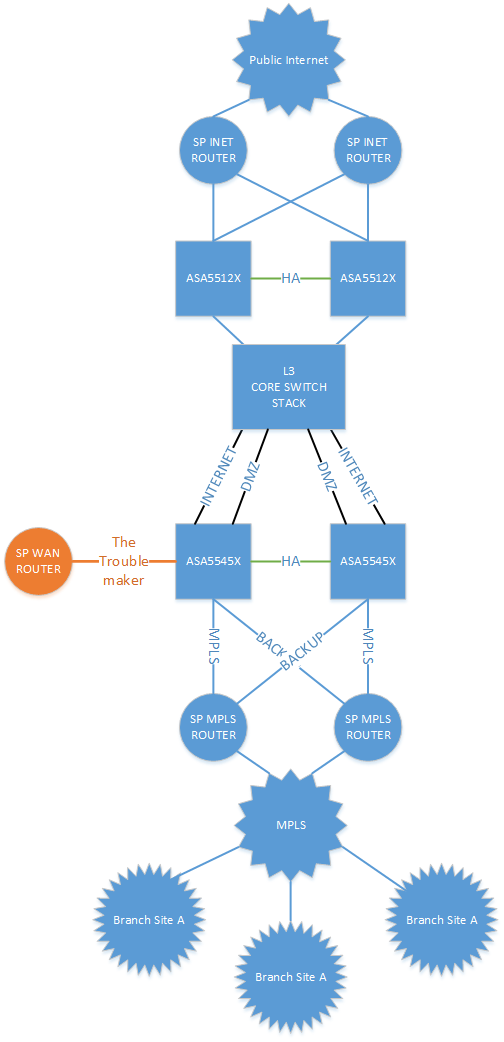
Firewall is 2 x ASA5545X's running as a active/passive pair.
The version is 9.2(2)4
Turns out there's currently no support contract on the ASA so unable to log a case with TAC at this stage.
The firewall sits in a data centre and is responsible for connectivity to the company MLPS and also to the core L3 switch, acting as a leg into an internal DMZ (server VLAN) and also through to another pair of 5512's which are sitting on the perimeter of the DC out to the public Internet.
Just before taking over, the previous tech attempted to patch an interface on the active ASA to a port on a WAN provider's router (not the same as the existing MPLS provider). Note that all tagging, etc. is handled on MPLS router kit. BGP is used across the WAN and is configured on the ASA5545 pari for routing across the existing MPLS.
The interface that was patched in has not been included in any peering config and, therefore, should not have received or advertised any routing to the device connected to this port.
When the patching was done and the interface was changed from shut to no shut, suddenly access to the internal DMZ was lost (server VLAN).
There may have been a complete loss of access to everything, including Internet. Unfortunately I wasn't working on it at the time and have no historical logs or specific symptoms provided or available to me.
The BGP setup on the ASA5545's includes "redistribute static" - but not "redistribute connected". There are no other routing protocols configured on the firewall.
The port that was patched into and enabled was set to a security level of 0, had an IP address configured that does not exist anywhere else on the network, and while the tech had created an access-list for it, he hadn't actually applied the access list to the interface (access-group command).
The MPLS interfaces also have a security level of 0
While the DMZ and Internet (patches into the 5512 internet firewall pair) interfaces have security level of 100.
There are access-lists applied to the two MPLS interfaces but none on the INTERNET & DMZ interfaces.
There is no "same-security-traffic" commands applied to the firewall at all (inter or intra).
The default route to the internet is via static route.
The DMZ route is also static to the switch.
I can't see any reason why simply patching in this interface and enabling it would've caused this outage. My only thoughts are that it may have something to do with the security level of the interface...even then I am doubtful.
Hoping someone on here might have some idea if that's a possible cause or other possible causes.
Solved! Go to Solution.
- Labels:
-
NGFW Firewalls
{kind=link}
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-06-2017 01:21 AM
There is the slight chance, that while patching, the failovercable had a loss of signal, or any other port on the active firewall, which caused the failover.
You should see in the logfile of the firewall (if you log it to a syslog) the reason for the failover.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-07-2017 11:37 AM
Hello,
Refer to the following: https://supportforums.cisco.com/document/139171/asa-interface-monitoring-failover-and-its-impact
It may be the interface monitoring. By default, physical interfaces are enabled for monitoring. When one physical interface goes down, the ASA will failover. You can probably try doing "no monitor-interface WAN2" to help avoid unnecessary failovers as there is no redundant connection for that link.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-29-2017 07:50 PM
*bump*
Anyone?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-04-2017 08:00 PM
Okay, found out partially why this happened.
Turns out the cables were patched into the standby device. When the port was enabled, the active firewall failed over to the standby.
Not sure, yet, why connectivity was not resumed when the standby took over but that's another story.
Anyway - I can only assume that it's some default behaviour that when one unit has more active links than the other, it becomes active. If anyone has any links to detailed info that would confirm or deny this I wouldn't be terribly upset :)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-06-2017 01:21 AM
There is the slight chance, that while patching, the failovercable had a loss of signal, or any other port on the active firewall, which caused the failover.
You should see in the logfile of the firewall (if you log it to a syslog) the reason for the failover.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-07-2017 11:37 AM
Hello,
Refer to the following: https://supportforums.cisco.com/document/139171/asa-interface-monitoring-failover-and-its-impact
It may be the interface monitoring. By default, physical interfaces are enabled for monitoring. When one physical interface goes down, the ASA will failover. You can probably try doing "no monitor-interface WAN2" to help avoid unnecessary failovers as there is no redundant connection for that link.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-10-2017 03:52 AM
Hi,
Hope I have got it right
Sorry if you find me irrelevant
Seems to be routing problem
Routing table was updated with a connected route which is prioritized over static route.
All traffic ment for DMZ & internet from end sites were directed to wan interface.
May be you can try configuring access list for the same, assign access list and then go for the no shut command(enable wan interface).
Bye
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-10-2017 10:05 PM
Thanks for your response.
Thing is the connected network (WAN) isn't a public routable range and isn't in use anywhere on the network. As far as I'm concerned, even if the WAN network was (rightly) added to the routing table, it wouldn't have any relevance to the network - nor the gateway of last resort.
I did find that the ports were patched to the standby device and that when the ports were enabled (via commands on the active device) - it caused a failover to take place - making active become standby and standby become active.
This is the primary reason for the outage. Next will be to figure out why after about 10 minutes, the previously standby unit, now active, didn't resolve the outage. It wasn't until the cables were unplugged/interfaces shut and the units failed back to their correct respective active/standby roles and connectivity was restored. Suspect nobody ever tested failover scenario and it has been poorly configured on all devices in the mix. That's another story for another day lol.
I believe that next time these are enabled, we won't have an outage as they won't switch active/standby roles as a result.
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide
