- Cisco Community
- Technology and Support
- Networking
- Routing
- [TCP Out-of-Order] and [TCP Dup ACK] - Whats going on???
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
[TCP Out-of-Order] and [TCP Dup ACK] - Whats going on???
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-03-2016 02:13 PM - edited 03-05-2019 03:16 AM
Continuation of another issue that is being researched by our provider, albeit snail pace
Transferring data sets is extremely slow, <1M on a 500M circuit.
This is not happening to ALL sites, 3 transfers at expected rates, the other 9 are dismal.
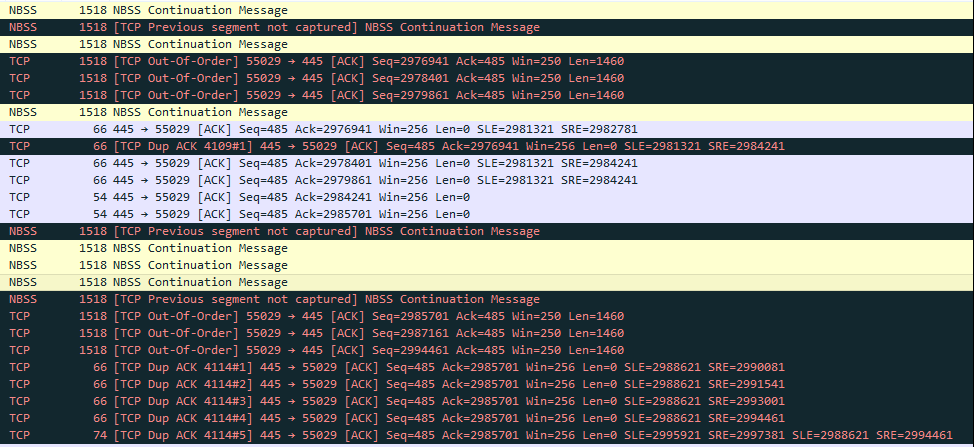
Attached screenshot cap of what is happening.
Cisco 4507 at each end. Happy to post any configs
- Labels:
-
Other Routing
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-03-2016 05:02 PM
As some transfers are ok, It looks like it could be the provider network.
What type of connection is it between the sites? Internet? MPLS? private?
perhaps share the relevant configuration, and do a show interface for the in question link for both ends.
regards
Richard.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-03-2016 05:19 PM
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-03-2016 06:19 PM
A couple of things I have noticed.
The Akl end is running 10Gbps and has flow control on
The Wlg end is running 1Gbps and has flow control off
You are running the link as a trunk but only allow one Vlan, so why not access port? or is this ready for future Vlans to go across the link?
I did a quick search on the internet for " TCP window size across MPLS"
and one link popped up very similar to your problem
http://serverfault.com/questions/644008/tcp-window-scaling-problem-over-mpls
HTH
Richard.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-03-2016 06:59 PM
Thanks Richard, checked other site config for flow control, they are all cookie cut. There are no pause frames detected on trunk interfaces, flowcontrol must be a red herring.
VLAN 4030 sets up BGP neighbor peers over our carrier ethernet service
Its a very odd issue, have included a hi tech graphical representation of affected areas, we can see WLG has lion share of egress issues, but why its not 100% accross all sites is beyond me.
Will keep hunting.... Thanks for taking a look :)
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-03-2016 10:36 PM
I think it is all to do with TCP window size and distance thru the MPLS network. I know in Ozz thru Telstra on our MPLS network Interstate the minimum ping time is 30ms no matter the size of the link.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-04-2016 07:07 AM
Disclaimer
The Author of this posting offers the information contained within this posting without consideration and with the reader's understanding that there's no implied or expressed suitability or fitness for any purpose. Information provided is for informational purposes only and should not be construed as rendering professional advice of any kind. Usage of this posting's information is solely at reader's own risk.
Liability Disclaimer
In no event shall Author be liable for any damages wha2tsoever (including, without limitation, damages for loss of use, data or profit) arising out of the use or inability to use the posting's information even if Author has been advised of the possibility of such damage.
Posting
TCP Dup Acks could be from lost packets or out-of-order packets, even when packets are not lost.
Lost packets, or enough out-of-order packets, cause the TCP sender to believe packets have been lost, which cause the TCP sender to slow its transmission, either backing down by half, congestion avoidance, or being pushed all the way back to slow start.
Lost packets that wait for timers to expire, really impact performance.
On high bandwidth paths, with high latency, TCP performance is especially slowed by lost packets (as congestion avoidance ramp-up is very slow). Additionally, if the receiving host doesn't provide a RWIN that can support the path's BDP, TCP will self limit its transmission rate (slower than the bandwidth supports).
So, you want to insure:
- packets are not being re-ordered along the way
- packets are not being excessively dropped
- the TCP receiver has a RWIN that supports BDP
Oh, and if you use RWINs greater than 64 KB, SACK may be a useful TCP feature.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-08-2016 05:42 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2016 02:28 AM
Disclaimer
The Author of this posting offers the information contained within this posting without consideration and with the reader's understanding that there's no implied or expressed suitability or fitness for any purpose. Information provided is for informational purposes only and should not be construed as rendering professional advice of any kind. Usage of this posting's information is solely at reader's own risk.
Liability Disclaimer
In no event shall Author be liable for any damages wha2tsoever (including, without limitation, damages for loss of use, data or profit) arising out of the use or inability to use the posting's information even if Author has been advised of the possibility of such damage.
Posting
. . . they do not manipulate on IP . . .
Yes, that's generally true, but that's not the issue. The issue is, whether packets are lost within the cloud and/or they come out the other end not in original sequence.
When it comes to service providers saying, there's nothing wrong with their network, that usually means either they don't know what they are doing, or it's a subtle issue.
For example of the latter, years ago I had one L3 VPN path (across provider MPLS), that just didn't seem quite "right" to me. So, I complained. No problem here, said the provider. Well I kept complaining, and complaining, until finally they found an out-of-date firmware on an interface card that would drop a low percentage of packets when under stress. They updated the firmware, issue resolved.
This only took 3 months. It was an international tier one service provider. With all my complaints, they even complained to my manager, but fortunately, my manager backed me.
If it is a provider issue, you often need to "prove" the issue is within their network. Like sending under CIR rate traffic, recording what goes into their network, on one end, and comparing to what comes out the other side.
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide