- Cisco Community
- Technology and Support
- Networking
- Switching
- STP Loopback error and Keepalive : ETHCNTR-3-LOOP_BACK_DETECTED
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
STP Loopback error and Keepalive : ETHCNTR-3-LOOP_BACK_DETECTED
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-08-2016 12:37 PM - edited 03-08-2019 04:31 AM
Hi everyone, a week ago a strange behavior happened on my network where an STP loop occured on two different spanning-tree vlan instances causing the isolation of 4 switchs at the same time (errdisable). Here's the log on PSW01, PSW02, BSW01, BSW02 (see topology):
%ETHCNTR-3-LOOP_BACK_DETECTED: Loop-back detected on GigabitEthernet0/23.
%PM-4-ERR_DISABLE: loopback error detected on Gi0/23, putting Gi0/23 in err-disable state.
When looking for the cause of the problem, i found out that an STP loop could happen due to a unidirectional link failure. So I would like to know if is it possible that a unidirectional link failure could happen on a twisted pair cable (Ethernet cable) because I found that this type of problems usually occur on fiber optics when one of the two links fail so the device can't either send or receive keepalive packets causing the device to change the state of its port from alternate to forwarding causing by that a loop.
- Also, If unidirectional link failure can happen on twisted pair cable, could it be because of a huge amount of data being tranferred between two servers (database replication) one server is in vlan 10 and another is in vlan 20, through the distribution switch (catalyst 3560) causing its saturation (buffer saturation) so it didn't receive keepalive packets from its neighbor switch causing it to open the alternate port and causing a layer 2 loop.
Note: UDLD was not configured on any of the switchs.
Thank you in advance.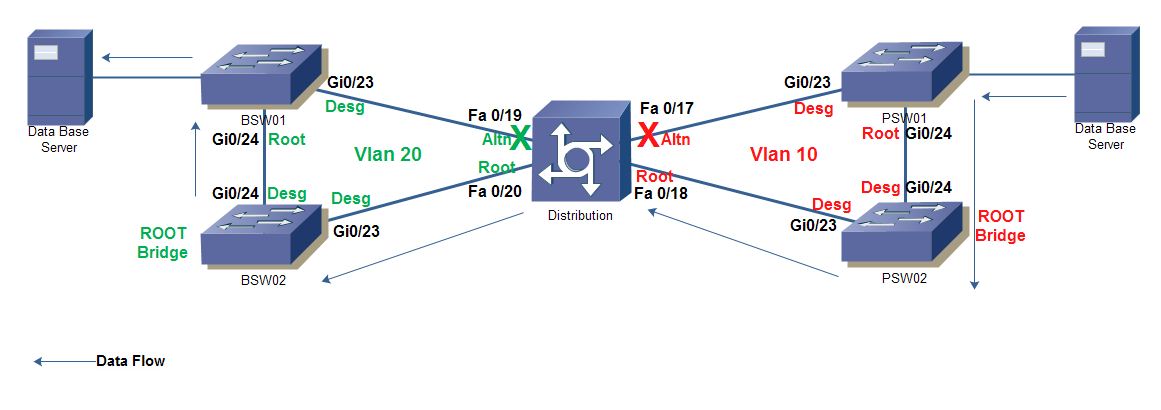
- Labels:
-
Other Switching

")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-08-2016 04:22 PM
The amount of data being transferred will not cause the issue. Spanning tree frames are sent at layer 2 with a high priority.
I guess a unidirectional failure could cause all sorts of bizarre issues - but this is not a common cause.
What type of Cisco switches are you using? Which spanning tree algorithm are you using? "standard", RSTP, PVST+, etc.
")
")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2016 01:05 AM
Hi Just to confirm unidirectional issues can occur on copper as well as fibre
good command for troubleshooting STP issues live ----
sh spanning-tree de | i ieee|occurr|from|is exec
VLAN0029 is executing the ieee compatible Spanning Tree protocol
Number of topology changes 9 last change occurred 26w1d ago
from GigabitEthernet1/0/26
Also rapid stp type and mst both have dispute mechanisms built in that can shut down a port so definitely would be good to know your type of stp configured
and your using a 3560 which can be effected by this known bug too just in case your on the IOS versions
https://supportforums.cisco.com/document/20111/error-ethcntr-3-loopbackdetected-catalyst-switch-runs-cisco-iosr-software
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2016 01:08 AM
Hi Philip, thank you for replying, I am using a cisco catalyst 3560 (IOS C3560-IPSERVICESK9-M, Version 12.2(55)SE6), and the other four switchs are cisco C2960 (IOS C2960X-UNIVERSALK9-M, Version 15.0(2)EX3). The spanning-tree algorithm being used is RSTP. The reason that made me think the issue was caused by the amount of data flow is that the problem happend at the moment when the replication was being processed. Also, is there a reason for the distribution switch to not receive the keepalive packet sent by PSW02 (interface Gi0/23) even though the link was UP?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2016 01:08 AM
IEEE 802.1D-2004 Rapid STP standard defines dispute mechanism that works similar to UDLD but on layer 2 of OSI model. Root bridge is sending Superiors BPDUs over it’s links and is waiting for replies from the neighbors. If an adjacent switch respond in a way suggesting it didn’t receive SBPDU, root bridge block its port, thus preventing the bridging loop.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2016 02:06 AM
Hi mark, so from your response I understand that the distribution switch may not have received the superior BPDU from PSW02. And if that was the reason of the problem, why would PSW01 put its interface (Gi0/23) in errdisable mode since it's not the root bridge and no STP loop exists ? . From the link that you shared, it says it's possible that the keepalive packet is looped back to the port that sent the keepalive, in my case, i woul like to know how this could happen?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2016 03:26 AM
You would need to debug the issue live to get that answer see exactly whats going on with the switches during the calculation while the unidirectional problem is occurring , unidirectional issues can produce varying and strange results from experience with stp.
Regarding looping keepalives how exactly it works im not 100% sure this is how Cisco have programmed there devices to check for the availability of ports using keepalives , if stp fails to converge quick enough keepalives will kick in from my understanding and block the port and put them into err-disable as stp couldn't do it
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2016 11:04 AM
Make the Cisco 3560, the distribution switch, the root of the infrastructure. I think this will give you the most stable solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-10-2016 11:57 AM
I was thinking - if these are Cisco 2960-X's then you can get stacking modules and stack them together.
If you stack them together then you'll get much more bandwidth between them, and you'll be able to do a multi-switch Etherchannel to the 3560 - and there wont be any spanning tree used, and all links will be able to forward packets.
All in all a much nicer solution and solves several problems at the same time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2016 01:34 AM
Hi Philip,
yes indeed, stacking them together will solve many problems and will also increase the performances. I will think about this solution. Thank you for your help, I very much appreciate it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2016 01:44 AM
Hello
To add to mark post, I would suggest apply UDLD aggressive on Fibre and copper ports and also manually prune any vlans that don’t require to traverse your trunks.
The latter can drastically negate the number of active stp logical and virtual ports instances being used across trunk interfaces
res
Paul
Please rate and mark as an accepted solution if you have found any of the information provided useful.
This then could assist others on these forums to find a valuable answer and broadens the community’s global network.
Kind Regards
Paul
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2016 02:05 AM
Hi paul, thanks for replying, all unnecessary vlans are pruned and of course I will apply UDLD aggressive on all trunks to avoid any future problems, but i would like to find an explanation to the problem that occurred.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2016 12:36 PM
Hello
just noticed in your topology diagram that you have what looks like edge switch(s) running as the root for either vlans taversng the distribution switch.---is this correct?
i would have assumed that your distribution would be the Stp root but again referring to your topology that switch is showing alternate & root ports!
res
paul
Please rate and mark as an accepted solution if you have found any of the information provided useful.
This then could assist others on these forums to find a valuable answer and broadens the community’s global network.
Kind Regards
Paul
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-10-2016 12:19 AM
Hello
The distribution switch isn't the root bridge, because most of the traffic goes between PSW01 and PSW02, we made PSW02 the root bridge so the traffic would flow throughout GigaEthernet ports instead of fastEthernet.
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide