- Cisco Community
- Technology and Support
- Networking
- Switching
- Hi Keith,In which interface
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Whats causing Input drops and overruns between 3502lap and 3750g switch?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-03-2014 08:50 AM - edited 03-07-2019 08:37 PM
At our HQ we have 6 3502 LAPs terminating into a 3750g switch stack. We have an issue with performance in some instances which I think is RF related, however in doing all due diligence I am looking at the Ethernet layer as well between the switch and the AP's in the area's of the performance issues.
I am seeing some Input Overruns and Input Drops on all of the AP's at the HQ location. One I am looking at now has 330 overrun and 34564 input drops. I have other remote sites and when checking those interface statistics they have 0 input drops and overruns. The other difference is that the remote sites are in flex connect mode whereas the HQ is in local mode.
Are the input drops and overruns a concern, or is it just because there's a lot more traffic at the HQ?
Thanks for your assistance!
- Labels:
-
Other Switching
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-03-2014 09:45 AM
Hi Keith,
In which interface do you see the input drops and overruns? Is it the connection between the HQ AP and its switch?
Can you provide a "show interface (port)" and a "show run interface (port), please?
I believe you would not need flex connect mode if you are already in your HQ.
Kind regards,
- Ed
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-03-2014 09:52 AM
Ok here is the port this AP is connected to that I referenced above.
GigabitEthernet1/0/30 is up, line protocol is up (connected)
Hardware is Gigabit Ethernet, address is 6416.8dc9.609e (bia 6416.8dc9.609e)
Description: Access Port Connection to Cisco Lightweight AP
MTU 1500 bytes, BW 1000000 Kbit, DLY 10 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Full-duplex, 1000Mb/s, media type is 10/100/1000BaseTX
input flow-control is off, output flow-control is unsupported
ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:19, output 00:00:01, output hang never
Last clearing of "show interface" counters never
Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 46951
Queueing strategy: fifo
Output queue: 0/40 (size/max)
5 minute input rate 52000 bits/sec, 3 packets/sec
5 minute output rate 30000 bits/sec, 31 packets/sec
113080164 packets input, 47601198717 bytes, 0 no buffer
Received 2211359 broadcasts (1347169 multicasts)
0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored
0 watchdog, 1347169 multicast, 0 pause input
0 input packets with dribble condition detected
711149027 packets output, 153496944729 bytes, 0 underruns
0 output errors, 0 collisions, 1 interface resets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier, 0 PAUSE output
0 output buffer failures, 0 output buffers swapped out
Here is the ports configuration:
interface GigabitEthernet1/0/30
description Access Port Connection to Cisco Lightweight AP
switchport mode access
ip access-group acl1 in
end
Doesn't look too bad on the switch, but on the cisco wireless controller for this AP in question (and others in the HQ) it shows the drops and overruns. I uploaded a picture of that screen.
If I change it to local, will it still allow other VLAN's through or would I have to change the switchport to a trunk?
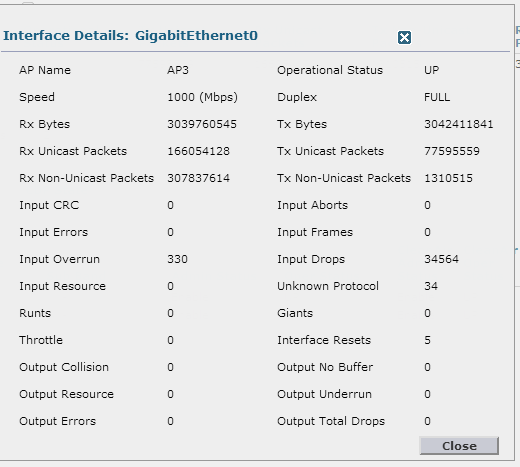{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-03-2014 10:29 AM
Keith,
The HQ APs should remain in local mode. Remote sites APs should be okay in flex connect.
Input drops in the AP are the total number of packets dropped while receiving on the interface because the queue was full.
Input Overruns are the number of times the receiver hardware was incapable of handling received data to a hardware buffer because the input rate exceeded the receiver’s capability to handle that data.
I believe the reason in your scenario is that all the APs receive more traffic and some is dropped when entering Gi0, but if there are performance issues it definitely has to be looked at.
Do you use GUI or CLI to manage the APs?
How many clients are connected per AP?
Are all the APs in non-overlapping channels?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-03-2014 12:12 PM
I use the GUI to the 5508 wireless lan controller to manage the AP's.
In the room where they are having problems, maybe 8 PC's and a few iphones are connected?
It appears that they are non-overlapping channels.
For instance some of the computers that jump to a further away AP 3 floors up I see are on channels 44,48 and 3 floors up that AP is on channels 60,64. For 2.4 Ghz the AP in the room is channel 1 and the AP 3 floors up is 11, and the AP 1 floor up is 6.
I think I may make a post in the wireless forums to progress further on some SNMP traps I see: Though I just wanted to make sure the switching / Ethernet layer was well taken care of also.
Interference Profile Updated to Pass for Base Radio MAC: 50:1c:bf:80:25:e0 and slotNo: 0
Interference Profile Failed for Base Radio MAC: 50:1c:bf:80:5f:d0 and slotNo: 0
Rogue AP : 00:15:ff:46:ce:9d removed from Base Radio MAC : 50:1c:bf:80:5f:d0 Interface no:0(802.11b/g)
Rogue AP : 00:15:ff:46:ce:9d removed from Base Radio MAC : 50:1c:bf:80:25:e0 Interface no:0(802.11b/g)
Coverage hole pre alarm for client[1] d8:d1:cb:97:5a:02 on 802.11b/g interface of AP 58:35:d9:39:5d:90 (AP4). Hist: 1 3 1 4 4 7 6 14 10 8 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
etc.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-20-2016 08:15 AM
keithsauer507, did you ever get this issue resolved? We have the same problem with our 3502, 3602, and 3702 LWAPs. Only difference is that we're not getting output drops on our switches feeding the problem LWAPs. All of the LWAPs hanging off this switch and others (4510R+E, 3560X-48PS, etc.) are getting Input Overruns and Input Drops. The problem's not isolated to a particular switch or type of switch, but seems to be prevalent on the entire subnet. In other words, some subnets have zero to minimal input buffer issues, and every LWAP on other subnets have the errors. I'm thinking it’s a traffic issue (multicast, broadcast, etc.) on the LWAPs management VLAN but don't see anything obvious.
Got a TAC Case open since last week with no luck so far.
Thanks,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-16-2016 01:43 PM
Update, TAC suggested that we configure our multicast handled by the controllers to multicast (not unicast, which is how we're configured). We are looking into making this change, without enabling multicast service on the rf side of the house to help reduce the additional cpu cycles when unicast packets are created by multicast seen by the controller's management interfaces. However, after two weeks of working with TAC, we noticed that we were no longer getting input overruns, and input drops were minimal so are taking our time with the change and closed the case.
Plus, cpu cycles don't seem very high (around 50% for our 7 controllers and 4000 users, so no rush.
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide