- Cisco Community
- Technology and Support
- Networking
- Switching
- Re: C2960-S - Spanning-Tree Protocol Issues
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
C2960-S - Spanning-Tree Protocol Issues
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2011 04:13 AM - edited 03-06-2019 03:46 PM
Hi,
We are experiencing problems related to the Spanning-Tree Protocol in our network. Our network consists of:
- CORE LAYER. 2 Cisco Catalyst WS-C6509-E Switches (IOS s72033_rp-ADVENTERPRISEK9_WAN-VM, Version 12.2(33)SXI5) in VSS mode.
- DISTRIBUTION LAYER: 2 Cisco Catalyst WS-C6504-E Switches (s72033_rp-ADVENTERPRISEK9-VM), Version 12.2(33)SXI4a) in VSS mode
- ACCESS LAYER: C2960-S Stacks (4 Switches) IOS:C2960S-UNIVERSALK9-M), Version 12.2(53)SE2
The Distribution VSS is connected to an Access Stack through a Mulichassis Etherchannel (MEC) as shown below:
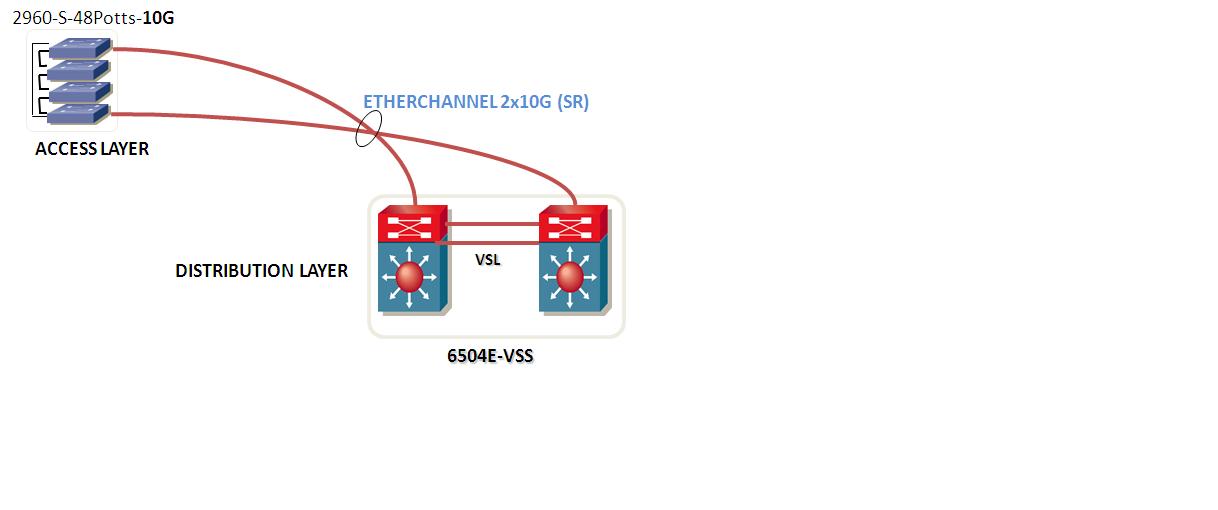
We have network outages due to Spanning-Tree re-calculations without link faillures or topology changes.
Feb 26 10:51:42.136 MET: RSTP(133): Po1 rcvd info expired
Feb 26 10:51:42.136 MET: RSTP(133): updt roles, information on root port Po1 expired
Feb 26 10:51:42.136 MET: RSTP(133): we become the root bridge
Feb 26 10:51:42.136 MET: RSTP(133): Po1 is now designated
Feb 26 10:51:42.194 MET: RSTP(133): updt roles, received superior bpdu on Po1
Feb 26 10:51:42.194 MET: RSTP(133): Po1 is now root port
Feb 26 10:51:44.217 MET: RSTP(133): Po1 agree (allSynced)
Feb 26 10:51:44.217 MET: RSTP(133): synced Po1
Feb 26 10:51:44.223 MET: STP[133]: Generating TC trap for port Port-channel1
Feb 26 10:51:44.238 MET: RSTP(133): transmitting an agreement on Po1 as a response to a proposal!!!
Feb 26 10:54:58.870 MET: %LINEPROTO-5-UPDOWN: Line protocol on Interface GigabitEthernet1/0/30, changed state to down
Feb 26 10:54:59.877 MET: %LINK-3-UPDOWN: Interface GigabitEthernet1/0/30, changed state to down!!!!!
RDS03-SW1#!!!!!!!!
Feb 26 11:08:34.341 MET: RSTP(180): Po1 rcvd info expired
Feb 26 11:08:34.341 MET: RSTP(180): updt roles, information on root port Po1 expired
Feb 26 11:08:34.341 MET: RSTP(180): we become the root bridge
Feb 26 11:08:34.341 MET: RSTP(180): Po1 is now designated
Feb 26 11:08:34.341 MET: RSTP(360): Po1 rcvd info expired
Feb 26 11:08:34.341 MET: RSTP(360): updt roles, information on root port Po1 expired
Feb 26 11:08:34.341 MET: RSTP(360): we become the root bridge
Feb 26 11:08:34.341 MET: RSTP(360): Po1 is now designated
Feb 26 11:08:34.351 MET: RSTP(180): updt roles, received superior bpdu on Po1
Feb 26 11:08:34.351 MET: RSTP(180): Po1 is now root port
Feb 26 11:08:34.351 MET: RSTP(360): updt roles, received superior bpdu on Po1
Feb 26 11:44:05.388 MET: RSTP(530): updt roles, received superior bpdu on Po1
Feb 26 11:44:05.388 MET: RSTP(530): Po1 is now root port
Feb 26 11:44:07.401 MET: RSTP(530): Po1 agree (allSynced)
Feb 26 11:44:07.401 MET: RSTP(530): synced Po1
Feb 26 11:44:07.406 MET: STP[530]: Generating TC trap for port Port-channel1
Feb 26 11:44:07.417 MET: RSTP(530): transmitting an agreement on Po1 as a response to a proposal
Feb 26 12:13:46.515 MET: RSTP(150): Po1 rcvd info expired
Feb 26 12:13:46.515 MET: RSTP(150): updt roles, information on root port Po1 expired
Feb 26 12:13:46.515 MET: RSTP(150): we become the root bridge
Feb 26 12:13:46.515 MET: RSTP(150): Po1 is now designated
Feb 26 12:13:46.515 MET: RSTP(304): Po1 rcvd info expired
Feb 26 12:13:46.515 MET: RSTP(304): updt roles, information on root port Po1 expired
Feb 26 12:13:46.515 MET: RSTP(304): we become the root bridge
Feb 26 12:13:46.515 MET: RSTP(304): Po1 is now designated
Feb 26 12:13:46.515 MET: RSTP(304): Gi1/0/13 not in sync
Feb 26 12:13:46.536 MET: RSTP(150): updt roles, received superior bpdu on Po1
Feb 26 12:13:46.536 MET: RSTP(150): Po1 is now root port
Feb 26 12:13:46.536 MET: RSTP(304): updt roles, received superior bpdu on Po1
Feb 26 12:13:46.536 MET: RSTP(304): Po1 is now root port
Feb 26 12:13:48.549 MET: RSTP(150): Po1 agree (allSynced)
Feb 26 12:13:48.549 MET: RSTP(150): synced Po1
Feb 26 12:13:48.554 MET: STP[150]: Generating TC trap for port Port-channel1
Feb 26 12:13:48.559 MET: RSTP(304): Po1 agree (allSynced)
Feb 26 12:13:48.559 MET: RSTP(304): synced Po1
Feb 26 12:13:48.565 MET: STP[304]: Generating TC trap for port Port-channel1
Feb 26 12:13:48.575 MET: RSTP(150): transmitting an agreement on Po1 as a response to a proposal
Feb 26 12:13:48.575 MET: RSTP(304): transmitting an agreement on Po1 as a response to a proposal
We have mitigated the outages by reducing the number of spanning-tree instances running on the access stacks but the problems still continue sporadically.
Any suggestions?
Thank in advance.
- Labels:
-
Catalyst 2000
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2011 06:22 AM
Is all you see in the logs? You don't have any interface problems on any of your switches? I mean a faulty SFP or faulty cable in the network? Do any of your ports go to err-disabled?
Something must be happening somewhere in the network for the topology change packet to be sent causing a recalculation. Even so, it's RSTP so the switchover should be immediate and not affect the network "much" unless it's constantly changing. If you shutdown the Po1 do the syptoms stop or simply move to another stack?
Regards,
Ian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2011 10:41 AM
Hi iwhitmore,
Thank you for your answer.
There is no link flaps in the uplinks and all SFPs and cables seems ok. There a few access ports that flaps but we don't think it is the cause of the problem (They are configured with the portfast command)
interface GigabitEthernet1/0/1
switchport access vlan X
switchport mode access
switchport voice vlan Y
storm-control broadcast level 10.00
spanning-tree portfast
spanning-tree bpduguard enable
We can`t disable Po1 because is the uplink.
We think that our problem is caused by CSCtj30652 Bug. We think that BPDUs packets are discarded because the CPU overflows. We have 38 STP instances running in the access switch and seems to much for the switch cpu. Reducing STP instances it mitigates the outages. For that reason we disabled all the STP instances on the access layer switches. We are waiting for the TAC answer.
Have anyone experienced a similar case?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2011 10:39 AM
hello
are your MEC's configured as per this documentation recommendations:
http://www.cisco.com/en/US/products/ps9336/products_tech_note09186a0080a7c837.shtml#mec
ie active-active (for lacp) or desirable-desirable (for pagp)
hth
andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2011 11:03 AM
Hi Andy,
We configured the thunk links this way:
Access Layer Switch
interface TenGigabitEthernet1/0/1
switchport trunk native vlan 5
switchport trunk pruning vlan 2-4,6-1001
switchport mode trunk
udld port aggressive
mls qos trust cos
channel-group 1 mode on
end
interface TenGigabitEthernet2/0/1
switchport trunk native vlan 5
switchport trunk pruning vlan 2-4,6-1001
switchport mode trunk
udld port aggressive
mls qos trust cos
channel-group 1 mode on
end
interface Port-channel1
switchport trunk native vlan 5
switchport trunk pruning vlan 2-4,6-1001
switchport mode trunk
Distribution Layer Switch
interface TenGigabitEthernet1/2/12
switchport
switchport trunk native vlan 5
switchport trunk pruning vlan 2-4,6-1001
switchport mode trunk
udld port aggressive
mls qos trust cos
channel-group 212 mode on
spanning-tree guard root
end
interface TenGigabitEthernet2/2/12
switchport
switchport trunk native vlan 5
switchport trunk pruning vlan 2-4,6-1001
switchport mode trunk
udld port aggressive
mls qos trust cos
channel-group 212 mode on
spanning-tree guard root
end
interface Port-channel212
switchport
switchport trunk encapsulation dot1q
switchport trunk native vlan 5
switchport trunk pruning vlan 2-4,6-1001
switchport mode trunk
mls qos trust cos
spanning-tree guard root
end
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2011 11:12 AM
hi daniel
i recently had intemittent connectivity problems with vss and L3 mec's - switched from on-on to desirable-desirable as per the recommendations which solved the problem for me. not sure if your seeing a similar problem.
regards
andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2011 11:17 AM
Yeah could be. I don't think its the VLANs on the 2960s. We have 2950s in our network core (over 50 switches) and have PVST+ and over 50 VLANs and never had this problem.
Recently we put in another 30 or so 2960s and changed to RSTP and still no problems.
Regards,
Ian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-27-2011 01:30 AM
Hi Ian,
Have you read CSCtj30652 Bug? I think that your switches are not affected by this bug but ours do.
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-27-2011 01:25 AM
Hi Andrew,
Thanks for your answer
What symptoms did you experience?
We are using L2 MECs and we have had no problems since we deactivated all STP instances on our access layer switches.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-27-2011 01:25 AM
Hi Andrew,
Thanks for your answer
What symptoms did you experience?
We are using L2 MECs and we have had no problems since we deactivated all STP instances on our access layer switches.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-27-2011 02:08 AM
hi marcos
network design was:
VSS --- L3 MEC --- 3750 --- PC
pc's were experiencing intermittent connectivity through the vss (if i pinged an affected pc from the other side of the vss, it would time out for a period and then start replying). i could see nothing in the logs of the vss or 3750.
i checked the vss config and worked my way to the 3750 when i realised the L3 mec was configured as on at both ends. changing the mec to desirable at both ends stopped the problem
the bug you mentioned seems to describe the issue you are experiencing. you mentioned you had a TAC open - see what the engineers think regarding the L2 mec setup
hth
andy
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide