- Cisco Community
- Technology and Support
- Networking
- Switching
- Problems with CAM table on multiple switches
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-26-2011 05:54 AM - edited 03-06-2019 05:12 PM
Hi there,
I have returned to work after a 3 month long holiday to find that we had some network connectivity issues. Every now and then random devices on the network would start to appear to be unreachable.
I had a look at my syslog server and could see that all my main switches (excluding my core switches) are reporting flapping between two ports. The flapping seems to only occur between the actual physical port where the device is located and the Port Channel which eventually leads back to the core switch which handles inter-vlan routing (Core switch 2).
Unfortunatly my company policies won't allow me to post my full configurations as I can't reveal IP addresses, hostnames etc to the public but I have created a basic overview of our 3 core switch (core 1-3), the main distribution switches (switches 10-14) and a local switch (switch 15).
The most common device to flap is our main server (Server 1), however every single devices on the network flaps (we have Solarwinds which polls all devices on the network).I think the only reason Server 1 flaps more often is because it sees a lot more data then any other device on the network
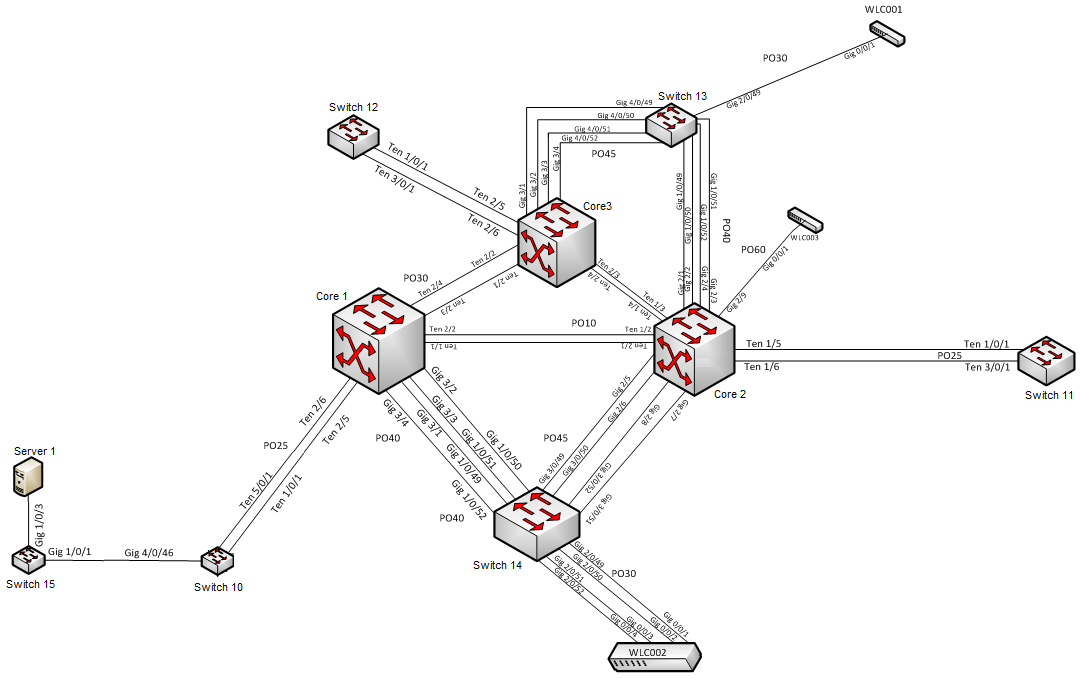
So I will therefore use Server 1 for my faultfinding. What I have found is that if I look at the CAM table when the server is responding on Switch 15, then it correctly reports that the mac address of Server 1 can be found on Gi1/0/3. Vice versa Switch 10 correctly reports that the mac address can be reached on its Gi4/0/46 interface.
However if I check the CAM table when the server is unreachable then I can find that Switch 10 reports that the mac address of Server 1 is on Po25 (which is obviously incorrect) and sometimes I can see that Switch 15 reports that the mac is on its Gi1/0/1 interface (however this is more rare, usually the problem occurs mostly on Switch 10).
Now as I said this happens to every single devices (across all VLANs and on any of the main distribution switches (10-14)). I am just using Server 1 as a example as it happens more often there and it makes the network topology a lot easier to draw.
I have spanning tree on and it seems to work fine. As a test I tried killing each redundant link so that the port channels only had 1 interface up and I also killed all redunant port channels to avoid any loops and the problem still continued.
My understanding is that a switch will look at any ethernet frames it receives and learn mac addresses from them? So if I am thinking correctly then that would imply that Switch 10 must receive a frame with Server 1's mac address as the source address coming through on port channel 25? What I don't understand is how this can be as there is no loop which could cause this?
Any ideas where I shall start to look? Im running,
Cisco IOS Software, s72033_rp Software (s72033_rp-IPSERVICESK9_WAN-M), Version 12.2(33)SXI1, RELEASE SOFTWARE (fc3)
Thanks for your help in advance!
Solved! Go to Solution.
- Labels:
-
Other Switching
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-26-2011 07:31 AM
Hello!
Does the server have only 1 connection to the network?
What is the switch model of switch 15?
If its a 6500, can you post the "show mod" output?
When the issue is present, what does show mac-address-table interface gi1/0/3 on switch 15? What is the output of show mac-address-table aging on all the switches?
Have you tried to check if there are any excessive TCNs seen using the command "sh spann de ac | i exe|Number of top|from"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-26-2011 07:31 AM
Hello!
Does the server have only 1 connection to the network?
What is the switch model of switch 15?
If its a 6500, can you post the "show mod" output?
When the issue is present, what does show mac-address-table interface gi1/0/3 on switch 15? What is the output of show mac-address-table aging on all the switches?
Have you tried to check if there are any excessive TCNs seen using the command "sh spann de ac | i exe|Number of top|from"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2011 03:04 AM
Hi Kapil,
Thank you for your quick response!
Switch 15 is a single nonstacked Cat 3750 and Server 1 which is connected to it has only 1 single ethernet port.
Aging time is set as follows,
Switch 15: 300
Switch 10: 300
Core 2: 480
I haven't been able to (or I am just not quick enough) to catch the problem when it happens to Switch 10. I do get flapping messages on Switch 10 at least once per minute, however the server still shows up on Gi1/0/3 even if I print my whole mac address table a second before the flap is logged, and again straight afterwards. The problem seems to mostly occur on Switch 15, however I have defiantly seen it happpen once on Switch 10 a few days ago.
This is reflected in the real life scenario as well as it seems devices which are connected locally to the same switch and on the same VLAN do not have problems reaching each other. It seems that 99% of the time when the CAM table gets messed up it only effects the next switch along which causes the rest of the network from reaching that device.
The last TCNs showing up were from 2 days ago when I decided to kill all redundant links and port channels to run a minimalistic linked network.
Thanks for your help! Very much appreciated!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2011 05:21 AM
Hi Kapil,
Sorry I just noticed that Core 2 actually has a lot of TCNs (anything from just a few seconds to 30 minutes).
Most of them have come from Port Channel 41 which is just a dual Gigabit connection to a small 8 port switch. I shutdown the port channel and all the TCNs stopped and I haven't seen any flapping messages yet (actually one or two but that was just the ports flapping back I believe).
Thank you very much for your help! You've made my day with that STP command
Any idea what could cause this (faulty gigabit switch?). I can't see any errors being logged and it is reporting both links as UP?
Thanks a million!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2011 06:46 AM
Hey,
Glad to know you could trace down the issue! Is that a Cisco Switch? If not, you might want to check with the vendor.. possible reasons for TCNs could vary.. usually faulty ports can cause this..
If its a Cisco Switch, we can try having a look.
Cheers!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2011 07:14 AM
Yes it is a 24 port Cisco 3560. The problem seems to be with phyisical cable going to Gi0/2 as I tried moving the gbics in the switch around and the problem persistent. Unfortuantly there are no spare cable runs down there and it is hard to run new cables to that location, so I might just have to live with just running with one connection to that switch.
Thank you very much for your help
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2011 07:18 AM
Glad to work with you on sorting this out! This thread can be marked resolved I suppose! :-D
Cheers!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-28-2011 07:08 AM
Yes it can, thank you ever so much for your help
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide