- Cisco Community
- Technology and Support
- Networking
- Switching
- switch stack takes 30 seconds to come up
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-09-2010 02:58 PM - edited 03-06-2019 09:13 AM
Hello Everyone,
I am preparing a group of switches for production and noticed some interesting behavior. I am interested in getting some feedback on it.
Allright, This is the enviornment. I have two 3750G switches stacked via the stacking cable. I have two 2960 switches connected to those via redundant connections as etherchannels. Here is a diagram:
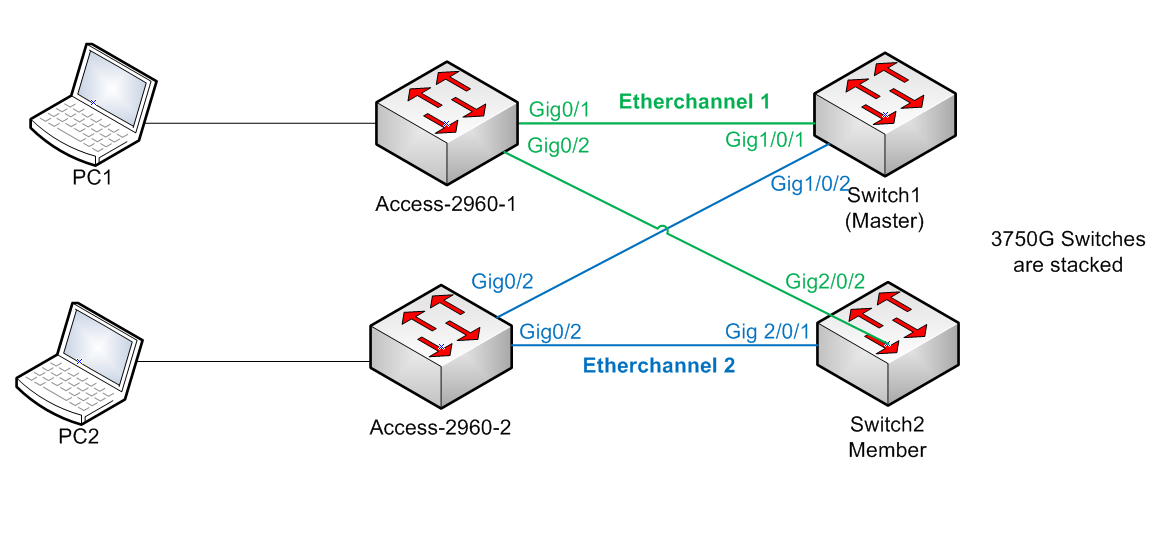
So, I have it connected and I am concurrently pinging everything. Each PC is pinging:
- The other PC
- It's own Access Switch
- The other Access Switch
- The core switch stack
These are all continous pings and the all is well. I also checked the device manager to verify that the traffic is being spread across both links in the etherchannel. However, If I pull power from one of the 3750 Switches, it takes approx 30 seconds for the traffic to be successful. (the ping to it's own access switch doesn't miss a beat). Once all the pings start coming back, I plug the switch back in. Once it (the switch that went down) fully boots, I drop a few pings to the stack and everything is fine.
I have tested it several times and there appears to be a few differnet variations of the results. Sometimes other devices come back faster than others. Seems like if I kill the master it takes a harder hit than if I kill the member. But, generally speaking I can't expect a full recovery for 30 seconds.
So, my questions are...
is this normal?
Should I expect faster recovery via a stack like this?
Is there anyway to improve this?
I did not configure persistent mac address in the stack configuration. Could that impact this?
If it's not indicative of a problem or misconfiguration, I am inclined to let it be. I think a 30 second automated recovery is within the scope of the availability expectations. However, if it means that I might have done it wrong, I'd like to get it corrected.
Thanks,
Ben
Solved! Go to Solution.
- Labels:
-
Other Switching
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-11-2010 11:14 AM
Hello Ben,
if the stack is the root bridge for the vlan take in account the following notes about STP and stacks
If the stack master fails or leaves the stack, the stack members elect a new stack master, and all stack members change their bridge IDs of the spanning trees to the new master bridge ID.
•![]() If the switch stack is the spanning-tree root and the stack master fails or leaves the stack, the stack members elect a new stack master, and a spanning-tree reconvergence occurs
If the switch stack is the spanning-tree root and the stack master fails or leaves the stack, the stack members elect a new stack master, and a spanning-tree reconvergence occurs
So the fact that things are worse when you switch off the stack master is explained by STP activity.
30 seconds out of service is compatible with backbone fast.
you can check spanning-tree using commands like
show spanning-tree summary
show spanning-tree vlan vlan#
You should see a change in bridge-id after failure of stack master.
I wonder if Mac address persistency could provide a better result by hiding this change of master.
Hope to help
Giuseppe
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-09-2010 05:06 PM
Hello Ben
Have you turned on portfast on the interfaces facing the PCs? if not turn it on by using "spanning-tree portfast" command and try again.
The failover should not take 30 seconds.
HTH
Reza
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-09-2010 07:48 PM
Hi Ben,
I agree with Reza. These are the following things I would start looking for:
1. STP portfast enabled on the access ports?
2. Are there any SmartStack errors or are the stacking cables connected correctly?
Are you pinging, for instance, the Management VLAN of the 3750 stack which also happens to be the default gateway of the PC?
Failover should be fast but the recovery, on the other hand, is different. When the Master recover, there's an election. This is the killer. You can try by manually setting the master with a higher priority (switch 1 priority 15) with the slave a lower priority (switch 2 priority 9).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-10-2010 07:29 PM
Hi Ben, I agree,
The 30 seconds is the Re-election of the Stack.. Manual setting of priorities should fix this.
Dion
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-11-2010 10:46 AM
Thanks to everyone for you input. looking at the electin aspect for a moment, A couple of points:
1. I already have the priority configured. see below:
Core-3750-1#sh switch
Switch/Stack Mac Address : 6416.8d85.9a00
H/W Current
Switch# Role Mac Address Priority Version State
----------------------------------------------------------
*1 Master 6416.8d85.9a00 10 0 Ready
2 Member 6416.8d9a.bd80 5 0 Ready
this is prior to me posting the initial question in this thread.
2. on the console of the switch that doesn't get powered on, I get the below output within the first 1-2 seconds:
1d19h: %STACKMGR-4-SWITCH_REMOVED: Switch 1 has been REMOVED from the stack
1d19h: %STACKMGR-4-MASTER_ELECTED: Switch 2 has been elected as MASTER of the stack
1d19h: %CFGMGR-6-APPLYING_RUNNING_CFG: as new master
does this indicate that it's probably a spanning tree issue and not a election issue?
3. There is something that I don't quite understand. Obviously, I am not an expert or I wouldn't be asking you all. But, I only have two switches. Why should the election process take 30 seconds? And if the priority is configured, how does that decrease the election time. IE if Switch 2 has a priority of 5, how does that decrease the election time when there is no other switch attached? If the standard election time is 30 seconds, can we reduce it?
4. Is there a debug command that I can use during the election process to track it?
Also attached (SwitchLog.txt) is the sh run on the core switch.
I will try the spanning tree portfast next.
Thanks guys,
Ben
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-11-2010 11:05 AM
Ben,
It should not take 30 seconds.
Stack master elections occur over a 10-second time frame on switches running releases earlier than Cisco IOS Release 12.2(20)SE3.
And here is the entire document:
HTH
Reza
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-11-2010 11:14 AM
Hello Ben,
if the stack is the root bridge for the vlan take in account the following notes about STP and stacks
If the stack master fails or leaves the stack, the stack members elect a new stack master, and all stack members change their bridge IDs of the spanning trees to the new master bridge ID.
•![]() If the switch stack is the spanning-tree root and the stack master fails or leaves the stack, the stack members elect a new stack master, and a spanning-tree reconvergence occurs
If the switch stack is the spanning-tree root and the stack master fails or leaves the stack, the stack members elect a new stack master, and a spanning-tree reconvergence occurs
So the fact that things are worse when you switch off the stack master is explained by STP activity.
30 seconds out of service is compatible with backbone fast.
you can check spanning-tree using commands like
show spanning-tree summary
show spanning-tree vlan vlan#
You should see a change in bridge-id after failure of stack master.
I wonder if Mac address persistency could provide a better result by hiding this change of master.
Hope to help
Giuseppe
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-11-2010 11:28 AM
Try enabling Uplinkfast on both of your Access Switches and try again.
HTH.
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide