- Cisco Community
- Technology and Support
- Collaboration
- Collaboration Knowledge Base
- Integrate UCCX with any SQL database with XML over HTTP
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
")
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 01-31-2013 11:52 PM

Problem: UCCX, especially the newer Linux based versions (8.0+) support four database types only (Oracle, IBM DB2, Microsoft SQL, Sybase). It's a common requirement, however, to integrate UCCX with other popular databases like MySQL or PostgreSQL or any other less known and/or exotic ones, like Apache Derby DB.
Analysis: some people choose to create a custom JAR with Java code to communicate with such unsupported databases. While this works, it introduces unnecessary burden to the UCCX administrator: scripts contain a call to a method which is hidden from the standard debugging facility of the UCCX editor and engine, making error detection difficult. From the administrative point of view, regular tasks like a password change may mean a disaster when replacing the custom JAR with the updated information.
The author is a Java enthusiast, but strongly believes custom JAR's should be used only as a last resort after all other possibilities have been examined thoroughly.
These other possibilities may include using UCCX's HTTP and XML and XPath capabilities. Of course, we need to introduce a proxy application that would translate HTTP queries into a language understood by the database server.
Solution: A Grails CRUD application. Why?
- It uses JDBC - so it can use virtually any database, with JDBC support.
- On the top of JDBC, it uses Hibernate, so we don't need to know any specifics of the underlying database system - chances are we don't need to write SQL queries at all.
- Supported languages are Groovy and Java. For those with Java background: take your seat and start coding, but if you want, you can also join the Groovy guys: it's basically a leaner Java on steroids. If you are new to Java, not a problem, Groovy is way easier to comprehend.
- Grails application = Java web application. Package it into a web archive (WAR) file, drop it into a Java application server (Tomcat, Jetty, JBoss, IBM Websphere, Oracle WebLogic are the best known, among others), use it immediately.
- Grails has excellent documentation and community background, backed by SpringSource (a division of VMWare)
- Scaffolding. You get an application that can be used in a web browser on your computer, for free, with minimal no effort. Serious.
How? A global view:
The Grails proxy application - which is running in a Java application container - uses Hibernate and JDBC to talk to a Database. It also has two interfaces accessible by HTTP: a HTML and an XML one, the first is meant to be used with a web browser, the second - well, in this case, UCCX, but it may be used by any other application as long as it understands XML.
For this purpose, let's pretend we are asked by a large movie rental chain to provide them with an application, which is able to create, read, update and delete information in their database of customers, which contains the following information:
- first name (optional),
- last name (mandatory),
- age (optional),
- phone number (mandatory).
Using this application, the employees of the company would be able to check whether the customer is an adult (so they can rent a dirty movie) and also the customer's phone numbers (so they can be notified if they forgot to bring back the dirty movie).
It's essential that this application is IVR based, so that the employees may call in and check and also update the necessary information. They have got Cisco UCCX already for other IVR services and they also have a customer database already in place. Unfortunately, it's not among the supported ones, and they are not willing to spend extra money on migrating their database to a supported one.
The step-by-step guide:
1. Download and install the Java Development Kit (JDK) - make sure it's the JDK, not the JRE.
2. Download Grails. Installation instructions are there, too, but just in case you're in a hurry and happen to use Windows:
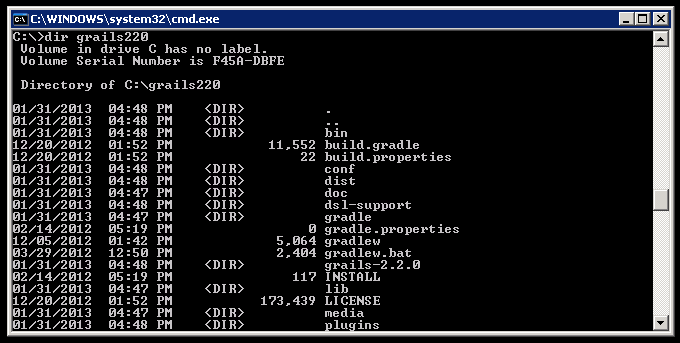
2a. Unzip the contents to a new directory, named C:\grails220:
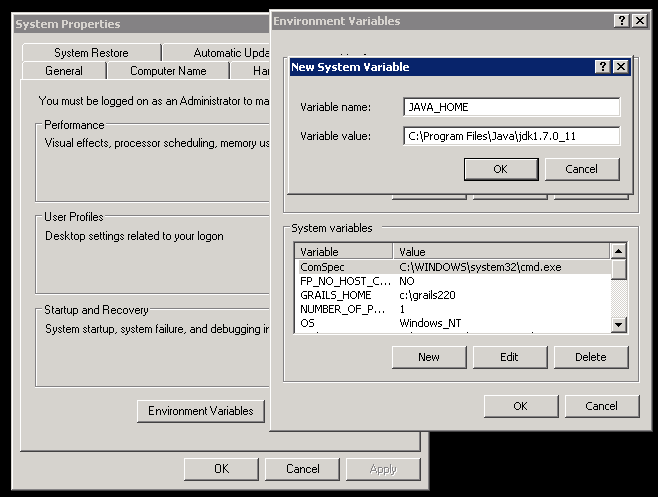
2b. Set the following system environment variables:
JAVA_HOME - the installation directory of JDK: in my case, it got installed into the C:\Program Files\Java\jdk1.7.0_11:
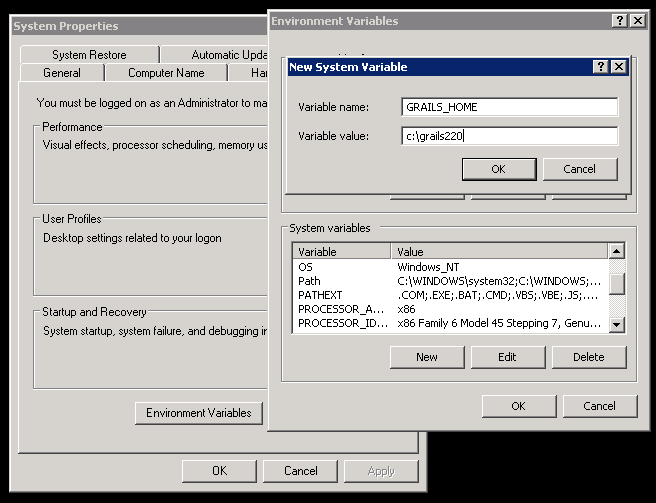
GRAILS_HOME - the installation directory of Grails (C:\grails220):
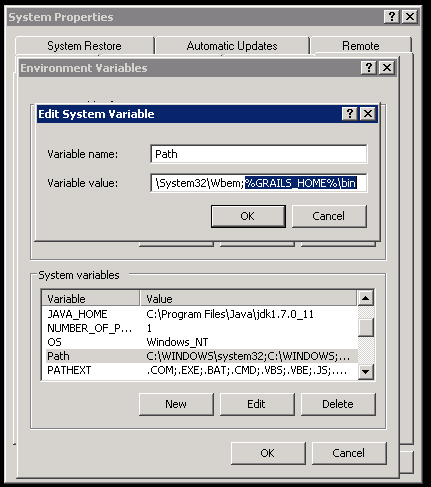
Finally, modify your Path system variable. Add a semicolon (;) and the following %GRAILS_HOME%\bin so that the executables under c:\grails220\bin can be run from anywhere in the command line:
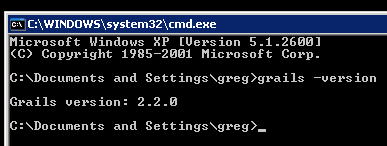
Now open command line (Start > Run, type cmd) and type: grails -version. If you see this, congratulations, you've got Grails installed correctly.
3. Create a working directory, which would contain all Grails applications, for instance, in the root (C:\) directory. Name it grails-apps, for instance.
4. Create a new Grails application: in this example, I am going to use the Apache Derby DB database (light, fast, excellent for development) - remember, it's all JDBC and Hibernate, so you can replace the underlaying databases easily! So the name is derby_crud.
Issue the following command in the grails-apps directory:
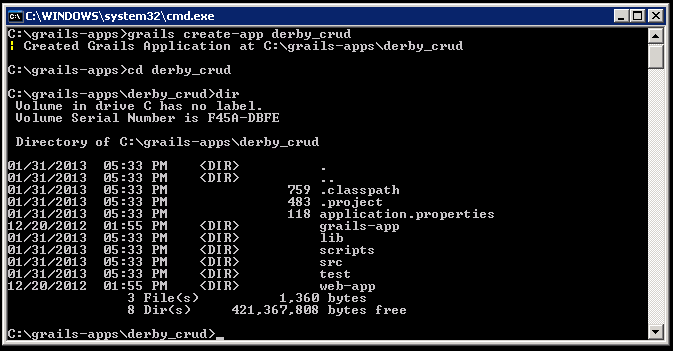
grails create-app derby_crud
This creates a new directory named derby_crud with the following structure:
4a. If you have not done that yet, change your working directory to the new one (see above), derby_crud.
Take a moment to observe the directory structure. Alright, we are not going to touch scripts, src, test and web-app - for those who are interested, there's the Grails documentation web.
But at this point we certainly need to know about the lib directory - as the name suggests, it's for the additional libraries our application may need.
What libraries? For instance, the JDBC driver JAR's.
5. Download the JDBC driver of your choice and copy its JAR file into the lib directory.
- Derby: http://db.apache.org/derby/derby_downloads.html
- PostgreSQL: http://jdbc.postgresql.org/download.html
- MySQL: http://dev.mysql.com/downloads/connector/j/
Here's another excellent Grails feature. It actually forces you to have at least three environments:
- development: where you develop your application,
- test: you test your application here;
- production: prime time for your application.
How does this relate to the JDBC driver? Simple. I am using Apache Derby in my development environment, but the customer may use MySQL in its production environment. What do I do? Copy all JDBC driver JAR's (for both Derby and for MySQL) into the lib directory.
5a. This screenshot actually shows that I copied the JDBC driver JAR of Derby and the JDBC driver JAR of MySQL into the lib directory:
6. Now that we have the drivers in place, let's set up the connection to the databases. Use your favorite text editor - I am using Notepad++ - to modify the C:\grails-apps\derby_crud\grails-app\conf\DataSource.groovy file (yes, grails-app contains Grails specific files, conf for configuration):
In the dataSource section, change the driverClassName setting to the JDBC driver class name.
- Derby: "org.apache.derby.jdbc.ClientDriver"
- PostgreSQL: "org.postgresql.Driver"
- MySQL: "com.mysql.jdbc.Driver"
For now, it's going to be "org.apache.derby.jdbc.ClientDriver"
Now read on the contents of the DataSource.groovy file, section by section.
First of all, ignore the hibernate section. It's for advanced users.
Next, you should see a section like this:
environments { development { etc
So here are our three environments I was talking about before.
Let's not worry about test and prod for the moment, and focus on the development one. What we need here is four settings:
- dbCreate: in development, it's "create-drop" by default. CHANGE IT NOW. Remember, we have got a database already set up, containing information, and we don't want to (re)create and drop it every time we start our application in development. So change it to "update".
- url: the JDBC URL.
- username: the username of the database user connecting to the daatabase specified in the JDBC URL.
- password: well yes, the password of the above user.
About the JDBC URL: different JDBC driver vendors require different JDBC URL formats. For instance:
- Derby: jdbc:derby://<server>[:<port>]/<databaseName>[;<URL attribute>=<value>]
- PostgreSQL: jdbc:postgresql:[<//host>[:<5432>/]]<database>
- MySQL: jdbc:mysql://<hostname>[,<failoverhost>][<:3306>]/<dbname>[?<param1>=<value1>][&<param2>=<value2>]
- JTDS for Microsoft SQL: jdbc:jtds:sqlserver://<server>[:<port>][/<database>][;<property>=<value>[;...]]
- JTDS for Sybase: jdbc:jtds:sybase://<server>[:<port>][/<database>][;<property>=<value>[;...]]
In this example, in my development environment, I have a Derby DB running at 192.168.210.36, with the database name of testdb, and I am connecting as the user "derby" with the password "derby":
dbCreate = "update"
url = "jdbc:derby://192.168.210.36/testdb"
username = "derby"
password = "derby"
Or, if you prefer a screenshot:
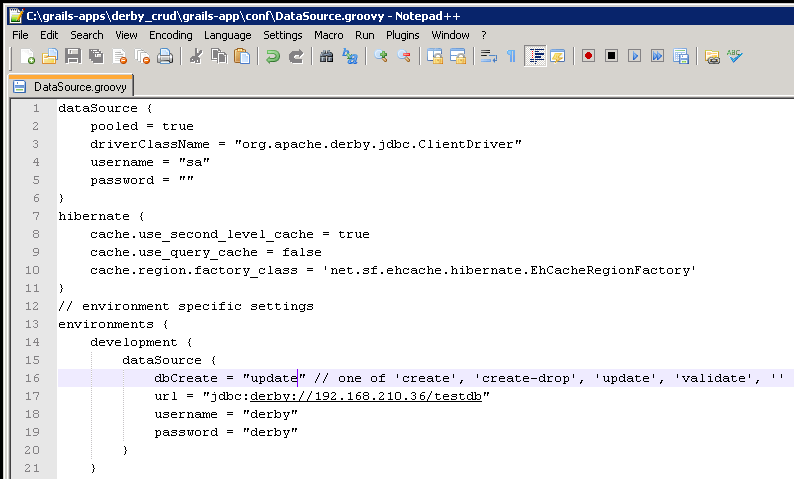
You might ask, the driverClassName setting is not within the development dataSource section - yes, for the moment, it's global, but we will take care about this later.
A more important thing: our database is already in place. So we don't create it from scratch, actually, we have no control over its structure, only its contents. We must somehow extract its structure and make it available to Grails. This is where we meet another excellent feature of Grails: its plugin system.
There are hundreds of plugins - most of them very good quality - available for your Grails application, each represent a specific function. There is a plugin for the Quartz scheduling system, there's a plugin for LDAP Security, etc.
The plugin we need here is the one that can reverse engineer a database: db-reverse-engineer.
7. Let's install the db-reverse-engineer plugin into our application, using command line:
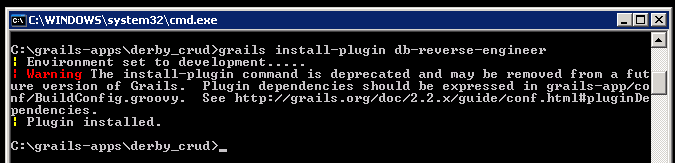
Alright, plugin installed. It's safe to ignore that Warning message.
8. Stop for a moment to take a look at the database structure we are going to reverse engineer.
For simplicity's sake, it's only one table named "CUSTOMERS" with 5 columns:
- ID: type int, auto generated, primary key, auto increment, start with 1, icrement by 1;
- FIRSTNAME: type varchar, max length 50, nullable;
- LASTNAME: type varchar, max length 50, not nullable (must contain a value);
- AGE: type int, nullable;
- PHONE: type varchar, max length 50, not nullable, must contain a value.
My Derby DB administrator was kind enough to show me this sample of creating the above table, inserting a row into it and show its contents:
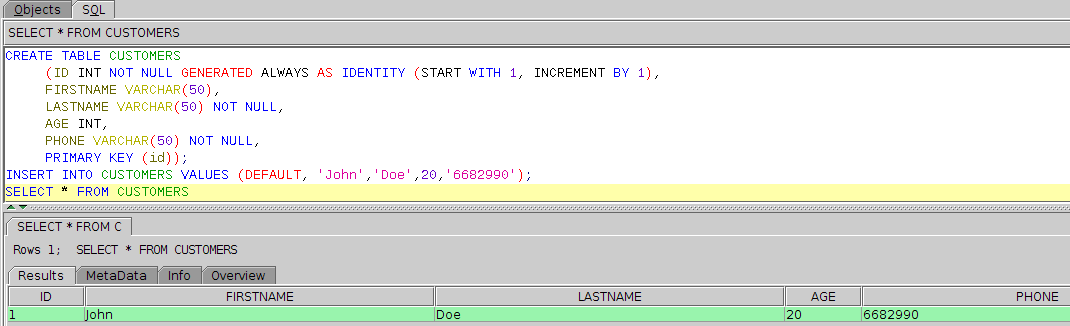
So this is the table we are supposed to "teach" our Grails application.
Fortunately, the db-reverse-engineer plugin will take care of that. It already knows, which database to connect to (it's specified in the DataSource.groovy file, remember?). By default, it will extract the whole database structure, which, in most cases, is quite unnecessary or undesired. So we prefer to tell the plugin the name of the table we want it to extract, nothing more.
If we take a look at the configuration options of this plugin, we see this setting: grails.plugin.reveng.includeTables.
Where to put it? To the 'main' configuration file of our Grails application: C:\grails-apps\derby_crud\grails-app\conf\Config.groovy.
Simply insert this line to specify, which table to reverse engineer:
grails.plugin.reveng.includeTables = ['CUSTOMERS']
(If you want to include more tables, you can, use the following format: ['table','table2','table3'])
9. Time to reverse engineer our CUSTOMERS table, by invoking the following command: grails db-reverse-engineer:

That's it. Now you may ask: what just happened?
Well, time to explain another Grails feature: MVC - which is not specific to Grails, many modern web frameworks use this principle.
In Plain English:
- M - Model: data.
- V - View: representation of data.
- C - Controller - a set of actions operating on data.
So if a web client contacts an MVC application, it actually invokes one of its controller's actions, which does something with the model and presents its representation, the view.
Guess what, our db-reverse-engineer plugin just created the model - out of the existing database table.
10. Exploring the domain class - the model - created by the db-reverse-engineer plugin: let's take a look at the grails-app\domain directory of our application. We see a new file there, named Customers.groovy. Let's open it with a text editor.
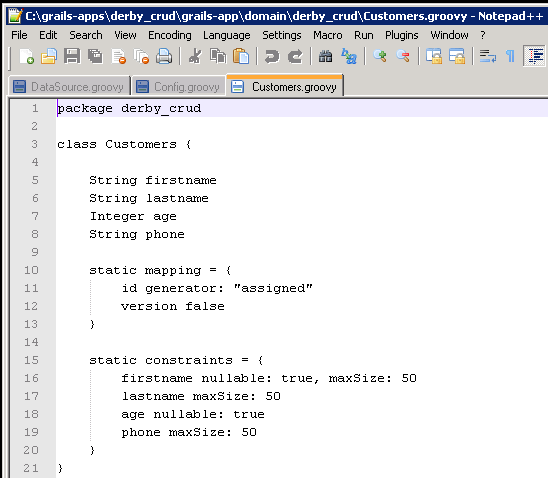
What we see is the structure of our CUSTOMERS table.
It has four regular columns. A firstname (type String ~ VARCHAR), lastname (type String ~ VARCHAR), age (Integer ~ INT), phone (String ~ VARCHAR). The ID column is not mentioned here, since it is special, but is there in the static mapping section.
This is something we need to change. Comment out the id generator: "assigned" line (as it was incorrectly detected by the plugin) and let's just tell grails to use the column named "id" as the ID column:
id column: 'id'
Now the static mapping section looks like this:

You may ask why we did that. Reverse engineering is - well, reverse engineering, and it cannot be perfect. It was intelligent enough to see that there's a special column named ID, so it did not include that among the regular columns (like firstname, lastname, etc). But it was wrong to say "id generator: assigned" as this implies when we create a new row in the database table, we assign its ID's value, which is incorrect - as we can see, the database generates it for us.
Reading along, the static constraints section, we can see all our constraints for the above columns. For instnace, firstname can be null (nullable), and its maxSize is 50.
Alright, now what. Are we going to write tons of servlets, JSP's, and what not?
No way. Ladies and gentlemen, put your hands together for yet another excellent Grails feature: scaffolding.
11. Scaffolding the HTML view.
We need a hammer, a box of nails - nay, we need to issue one command:
grails generate-all derby_crud.Customers

That took care of everything. It created a controller and a couple of views. We are going to check it out right away.
A quick note: remember, the first row in our Customers.groovy domain class file was package derby_crud. It was auto generated and it's just a nice organizational feature. It means that this class of ours belongs to the package named derby_crud - and it's kind of like FQDN's.
Nevertheless, the generate-all command expects the full name, including the package.
12. Already tired of this manual, right? Let's see some action. Start up the application.
Now you may say: hey, wait a minute. You said this Grails thing is supposed to be running in a Java application server. And we ain't got none.
Well, yes, but I did not tell you Grails can run your application without an application server. Just for testing.
So issue the following command:
grails run-app
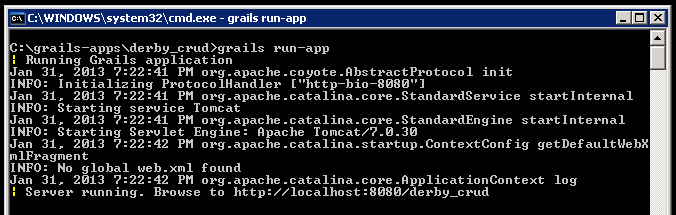
What it does: starts up a lightweight Tomcat server, with our Grails application in it, and most importantly, with the development settings.
See, it tells us to browse to http://localhost:8080/derby_crud
Are we brave enough? Yes, certainly.
This is what we should see:
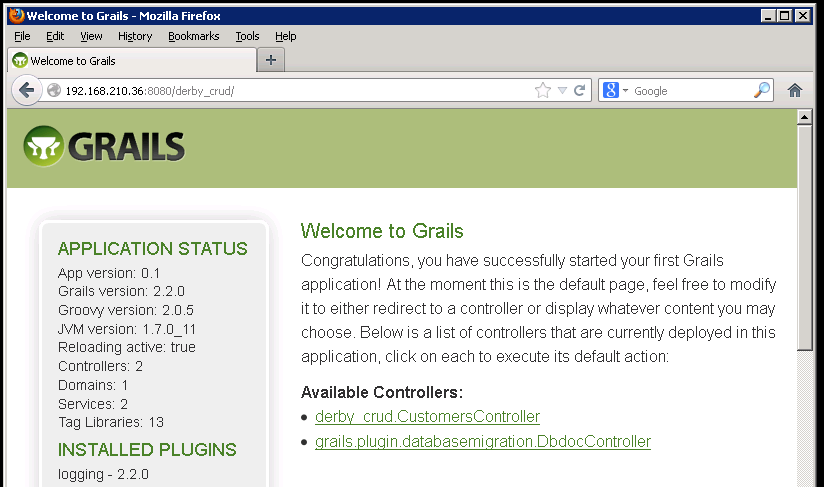
Let's click that CustomersController link.
Now, where does this list come from? From our CUSTOMERS database table, of course.
Did we do anything special, like write a single Java code, or SQL queries? Nope.
What we did was: we copied a JDBC driver file and we changed a couple of lines, like the JDBC URL. But this is nothing special.
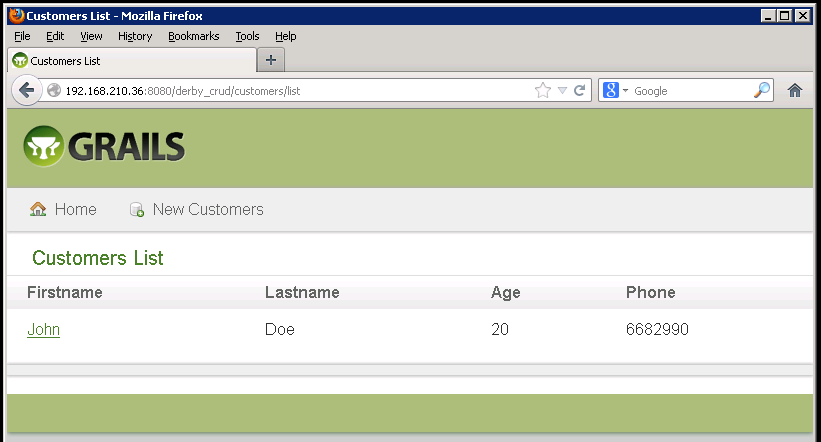
Now, for CRUD: can we create? Yes, sure. Click the New Customers link.
I happen to insert a new customer, named Jose Manuel, age 22, phone number 2121234567.
Now let's take a look at the database:

As we can see, the ID is auto generated (the web page told you, too). Everything perfect.
We can update and delete, too.
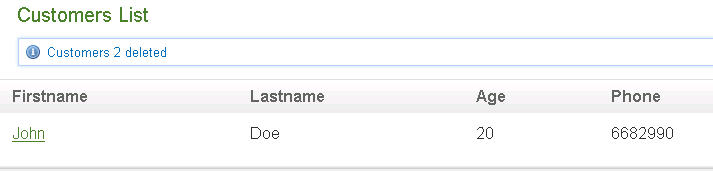
And it disappeared from the database table, too:
![]()
This is the bonus steak we got. Let's enjoy it.
13. Modifying the controller to make it produce XML for UCCX.
Bumpy road ahead. We are actually going to write some Groovy code (finally!).
13a. First of all, let's introduce a create operation: inserting a new customer into the database.
Pretend, we have already got a UCCX script that collects the firstname, lastname, phone number and age of the customer, probably using ASR or DTMF. These are already assigned to the following script variables:
- firstname
- lastname
- age
- phone
So we need to send this information to our proxy application, which, in turn, saves this information into the database, and returns something, either an error message, or a status code that inform us whether the operation was successful.
Open the controller class file - guess what, it is grails-app\controllers\CustomersController.groovy.
See all those def index() and def list etc sections? Those are the actions in the controller. Do not touch them (yet).
Insert the following code instead, at the very beginning of the file, but right after the package declaration:
import grails.converters.*
import groovy.xml.*
Then, already in the class declaration, preferably after the static allowedMethods line, the following code block:
def insertXML() {
def customersInstance = new Customers(params)
if (!customersInstance.save(flush: true)) {
render (contentType:"text/xml",encoding:"UTF-8") { error { message('INSERT_FAILED') } }
return
}
render customersInstance as XML
}
A screenshot:
The two imports - well, they import necessary objects and methods. Let's not worry about them.
That other thing: it's a new action in our controller, named insertXML.
What it does:
- creates a new, instance of a "Customers" object: it's like telling the database: create a new line in the CUSTOMERS table. The params variable is the HTTP parameters. Yes, it's easy as this. So if we call this action in this controller over HTTP by specifying the necessary parameters, it will create a new line with the values of those parameters;
- tries to save this new line (flush:true means immediately). The save operation returns a true or false value. If it's false, send back - render - an error message, and return; otherwise send back - render - the new Instance, as it says, "as XML". Like English. Groovy.
About that error message: see, how easy it is to create an XML? All you need to do is this:
render (contentType:"text/xml",encoding:"UTF-8") { error { message('INSERT_FAILED') } }
So we specify the content type (text/xml), the encoding (UTF-8), and a structure. What does it look like - fancy a guess?
As we see, I did not send any HTTP parameters, and the database did not let me create a new row - it has some columns with the NOT NULL constraint.
If, however, I send all the information, this is what I am supposed to see:

Take a look at the address bar.
- http://192.168.210.36:8080/ - the server and the port
- derby_crud - the application name
- customers - the controller name
- insertXML - the action name
- firstname, lastname, age, phone - the HTTP Get parameters.
Why ID 3? Remember poor Jose Manuel who got deleted? His ID was 2.
The CUSTOMERS table contents at this point:

Now, let's insert another record, this time with the help of our UCCX script:
As I said, I've already collected the necessary input, probably over ASR or DTMF, all the same and we are about to create the following customer: Ted Enger, 30 years old, phone number 212 991 5581.
- firstname: Ted
- lastname: Enger
- age: 30
- phone: 2129915581
All we need to do is to insert a Create URL Document step. Like this:
Basically, we are constructing the same URL like we did just a while ago, with Joshua Gannon. Set your timeout to a reasonable value, 10000 should be adequate.
Remember, Create XML document step does not actually issues the HTTP request. First, we need to call the Cache Document step (so we don't issue multiple HTTP requests when runinng multiple XPath queries - we want this customer to be saved only once).
And only then we cast the document into an xml one:
Finally, let's check this using the Get XML Document Data step: are there any errors?
XPath: /error/message
With the help of a simple If node, we can evaluate the value of result (which is of course, type String):
- If null, fine, this means XPath produced no match and we can continue.
- If not null, however, we can't continue and we save the error message text (most probably "INSERT_FAILED") for future reference.
Let's assume everything went perfectly, so the proxy application returned an XML representation - view - of the new customer.
Let's use XPath (with the Get XML Document Data step) to filter out our new customer's ID.
XPath: /customers/@id
And now the result variable should contain the value of the ID column of the new record in the database.
A screenshot of our testing script:
If we run step-by-step debugging, we should be able to see that the value of the result variable is indeed the next ID, 4.
The value of the xmldoc variable (contains the XML we got from the proxy application):
TEXT[<?xml version=\"1.0\" encoding=\"UTF-8\"?>\r\n<customers id=\"5\"><age>30</age><firstname>Ted</firstname><lastname>Enger</lastname><phone>2129915581</phone></customers>]
Voila: the database now contains this:
So let's sum it up again:
- we integrated UCCX with a relatively unknonwn and absolutely unsupported (by UCCX) database, Apache Derby DB,
- without writing a single line of SQL,
- without worrying too much about the database structure;
- we got a nice HTML web application for free,
- we got a nice XML interface for - well, almost free.
(... to be continued: this was C from CRUD, next, we will take a look at the R, U and D).
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Excellent article. Totally what I was looking for, right up to the point where you explain the URL document step in the UCCX script. Here this web page does not display the images, so I am none the wiser!
Can you take a look at your article and rectify the broken images?
Thanks
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi,
well, I am afraid I can't fix it easily. Ever since they changed something around this forum's engine the images (of documents created using the old forum engine) magically disappear and reapper, at least, some of them.
I am planning to create a newer version of this document or just update this one, hopefully, there would be no problems with images.
G.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks. Annoyingly, I have already created my Grails environment pretty much exactly as you had described, and I was wanting to understand how the Create URL / Create XML / Cache Document steps in UCCX are used to CRUD my web app, but those are the images which are broke!
So, if you update this it would be hugely helpful to me. (Or if you can point me to another resource that would help with the UCCX steps).
The really nice thing about using the method you've described to access databases (apart from being able to interface with non-standard DB's) is that Grails also handles multiple datasources seamlessly, as in the case where you have 2 SQL's mirrored for failover.
i.e. in your Grails datasource config you can include a 'failoverPartner' in the URL definition, which just does the magic stuff for you if the primary DB failsover to the secondary one. The alternative would be to handle this in the UCCX script which is not nice.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi,
actually, that part is quite simple. I am attaching a screenshot taken from a UCCX script that does the same: accessing a URL, getting and parsing an XML using an XPath expression:

There is, of course a variable of type Document named doc and a String type variable named result.
About that failoverPartner part: I assume you are trying to use a MS SQL Server with the MS JDBC Driver, is that correct? Actually, Grails would take whatever the underlying data layer (most likely, Hibernate) provides. And Hibernate would work as long as the JDBC connection is alive. So it's really up to the JDBC driver - and perhaps the database system used - whether such automatic failover is supported or not.
G.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi,
Thanks very much! I'll get on and start playing to see if I can make this all work now.
Yes, I am using the MS JDBC driver, and so thanks for explaining in more detail how what I am doing actually works. It's useful to know, in case I ever decide to swap to another DB and driver.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Okay, good luck with your project. Let me know if you get stuck.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Just got back onto this. I've re-created your suggestions above, but it hangs when I hit the Cache Document step. Any clues? The script validates, and running reactive doesn't help in that it just sits there when it hits that step.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi, did you try opening that URL in a browser? Does it display anything?
G.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Yep, and it worked fine. (I had to do some surgery on the Grails app because I am using a Filter to provide authorisation/authentication for my web app, which I'd forgotten about, so I've created a new controller to handle unathorised/unauthenticated requests like this that the filter ignores).
It works ok when I use a browser, but I did wonder if it was because I was using https, rather than http?
(IE pops a message saying it is showing only secure content, and I have to click a button allow it to show all content, and when I do I see the XML just fine, and a record appears in my DB. )
But the uccx script still hangs on the Cache Document step.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi,
SSL might be an issue, I know some people ran into this when trying to read from a HTTPS URL. To be honest, I did not have the chance to test it myself. I might give it a spin later.
Did you take a look at the UCCX MIVR logs? There might be a clue.
G.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Gergely,
We are interesting about contract you to integrate CCX with postgreSQL. We are from Venezuela. We work with call manager Unity and CCX ( but with ccx we are not a expert). We need your help. And i would like to know as would your rate per hour and how many hours that you thing could be take to do this proyect.
Please send me the information to my e mail [email protected]
Thanks in advance
Carlos Arvelo
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: