- Cisco Community
- Technology and Support
- Networking
- Switching
- Re: High latency issue in LAN....
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
High latency issue in LAN....
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-10-2010 07:04 AM - edited 03-06-2019 12:24 PM
Hi All,
This is my 1st post in this forum.
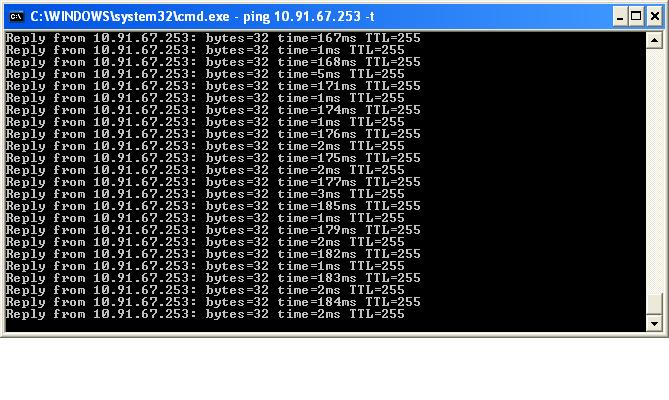
We have different vlans for different processes in our organization & all the vlans are created on core switch (Cisco 3750G). When im pinging any VLAN's gateway in our LAN network im getting high latency. This has not cause any problem in our network so far but i want to resolve this issue as early as possible. I have checked config in our L3 switch but found no issue.. have attached snap shot of IT vlan gateway........
Network Architecture :--
Machine-->Access Switch-->Core Switch-->Cisco ASA-->Packet Shaper-->Radware-->Internet Router-->Internet Link
Any Soln. on this issue? Thanx in advance.
- Labels:
-
Other Switching
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-11-2010 06:05 AM
@Vincent -- we have 2 core switches which are working in single bundle that is the reason we have 2 gateways. im facing this issue only when im pinging primary gateway. Yes i tried connecting machine directly to core switch but faced same problem.
@Jaison -- 1) When i ping any machine in same network from L3 i get arnd 200ms response in between.
2) Got same response when i tried pinging L3 from L2.
@Vijay -- Thanx for ur reply. im trying to ping gateway of my machine i.e interface ip of VLAN 167.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-11-2010 09:49 AM
Some useful commands to help.
You can check for spanning tree state changes if redundancy is involved as far as redundant l2 paths. This could cause issues if happening often.
show spanning-tree detail | inc ieee|occur|from|is exec
You can check for interface input queue drops as well on the switches to see if interfaces are getting overrun which
might lead to lost packets.
sh int | in Input|line
This will show you all interfaces for comparison to problem vlan 167
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-12-2010 04:16 AM
Hi Amit,
Could you please check the speed and encapsulation of both the switches connected(Core and other) and check the CPU Utilization whenever you ping both the gateway.
Change the port configured as a trunk and gateways to check the physical problem port of the Switch
Regards
Vinod Agrahari
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-12-2010 05:17 AM
Let me re-state the "problem".
Ping Round Trip time from a PC to a "gateway" (perhaps a Cisco 2960) alternates between 3ms and 200ms.
All other ping tests on network are 3ms or better.
"i guess its something related to core switch becoz when im pinging other devices in network im getting normal responsw 1ms"
The reason will be that the "core switch" is busy doing something else and takes a little time to get round to replying to the probe. On the face of it this does not seem very worrying to me. The 29xx switches do not have particularly fast CPUs and a slow ping response is not unexpected.
If this is a new behaviour then you might want to have a look to see what might be the cause. If so - check for high CPU on the 2960.
sh proc cpu is the place to start.
Note particularly that the 2960 does *not* use the CPU for switching traffic, only for managing itself. Traffic is switched in dedicated hardware. This is why I have few concerns.
You might I suppose want to collect the 1s cpu utilisation from the device with snmp.
As I have said, does not seem very worrying to me.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-12-2010 09:10 AM
@Vinod -- CPU utilization on L3 & L2 switches is normal (between 10-20 %). Also no physical prob. found on switch port.
@Douglas -- our core switch is of 3750G series. Im getting high latency only when i ping gateway of any vlans which are created on core switch. When i ping to other devices which are behind or after core switch i get proper response 1ms.
@Bradley-- NO issue found with the spanning tree. Core switch is a root switch in our network.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-12-2010 04:03 PM
Hi,
"@Douglas -- our core switch is of 3750G series. Im getting high latency only when i ping gateway of any vlans which are created on core switch. When i ping to other devices which are behind or after core switch i get proper response 1ms."
I am saying that 200ms *IS* a proper response.
There is not necessarily any problem. If you check the cisco web site you will find NO indication of any expected ping response time.
Can you post the output from.
sh proc cpu.
By the way - I have already mentioned this but you have not responded with any data.
It also might be VERY interesting to have the results of SNMP probes of the 1s CPU load.
I have also already mentioned that.
HA! I have just remembered that BPDUs are sent every 2 seconds. Maybe you have some weird STP design with excesive BPDUs?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-08-2011 12:22 PM
I have to agree with DouglasScott99 on this one, you need to provide more information.
But I can say, that in my experience when you see an output like the one you included in the original post you have asymmetrical routing occuring.
The best thing to do here is to complete a number of traceroutes to the destination IP from your host. You will probably see that it takes two different paths. One path with the low ms response time and one path significantly longer.
It would be easier to troubleshoot your problem if you provided more details about the infrastructure design and results of these traceroutes.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-08-2011 05:12 PM
Disclaimer
The Author of this posting offers the information contained within this posting without consideration and with the reader's understanding that there's no implied or expressed suitability or fitness for any purpose. Information provided is for informational purposes only and should not be construed as rendering professional advice of any kind. Usage of this posting's information is solely at reader's own risk.
Liability Disclaimer
In no event shall Author be liable for any damages whatsoever (including, without limitation, damages for loss of use, data or profit) arising out of the use or inability to use the posting's information even if Author has been advised of the possibility of such damage.
Posting
In general, neither switches or routers are designed to provide highly accurate ping response values. If your platform supports it, you might configure a SLA responder which should provide a more accurate ping response (if responding to a SLA request).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-08-2011 07:09 PM
Ping response is low on the priority list of things the switches do . Do not use this as more than a rudimentary test. Ping to devices through the switch itself on the subnet and not a given L3 interface or SVI .
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-13-2013 07:18 AM
The problem (which I have chased for years) is related to some sort of timing failure with the TCP/IP protocols..
The following seems to clear it up normally: (slight variation for Windows 2000, 8)
open an Administrator command prompt (press Windows key, type CMD and hold left Ctrl, left Shift and press enter, answer Yes)
type in the following commands: (Make note of your TCP/IP address and settings first if static.)
IPCONFIG /FLUSHDNS ARP -D GPUPDATE /FORCE NETSH INT IP RESET NULL NETSH WINSOCK RESET shutdown -r -t 0 -f
First, we clear DNS cache (important, and helpful)
Second, we clear ARP entries. (arp -a will list all connections, including MAC addresses. very handy to know)
Third, we force a PC/User group settings refresh (will happen at next boot)
Fourth, we reset the TCP/IP protocol settings to defaults. (This actually fixes some bottlenecking in protocol layers)
Fifth, we reset winsock (fixes timing issue, and both sections get resynced at boot. MUST BOOT at this point.
Last, we force an immediate reboot. (another handy command).
Once the system reboots, you are now in DHCP mode, and timings have been reset.
So why does this happen? After years of tracking how this gets caused, or better ways to fix it, the people who use video conferencing seem to make this fail more often, but I still can't figure out what is really happening yet.
This is the simple solution. If this fails, go into the protocol list for any adapter, click install, click have disk and point to "c:\windows\inf" and select TCP/IP. This is roughly the same as the procedure above, but changes other entries. Good for Win2k.
The last solution that fixes this when all else fails, go into Device Manager, remove the network adapter(s) [Leave drivers, Vista+], then immediately reboot. -- on reboot, drivers are reinstalled, new UniqueID for device generated, and all settings reset, firewall settings added to fresh installation, and other strange issues fixed.
Sorry this is 2 years to late, but I am dealing with this a lot lately, and can't find a solution yet either.
-- Note, "Null" is the output filename, which is normally listed as c:\temp.txt, but some windows versions won't allow writing to the root, and can be replaced with c:\windows\temp\temp.txt, since this directory is likely to exist.
Good luck, and I do hope to figure this out one day.
- « Previous
-
- 1
- 2
- Next »
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide