- Cisco Community
- Technology and Support
- Networking
- Switching
- Re: Runts and Overruns
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Runts and Overruns
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-14-2008 02:02 PM - edited 03-05-2019 10:59 PM
Hi
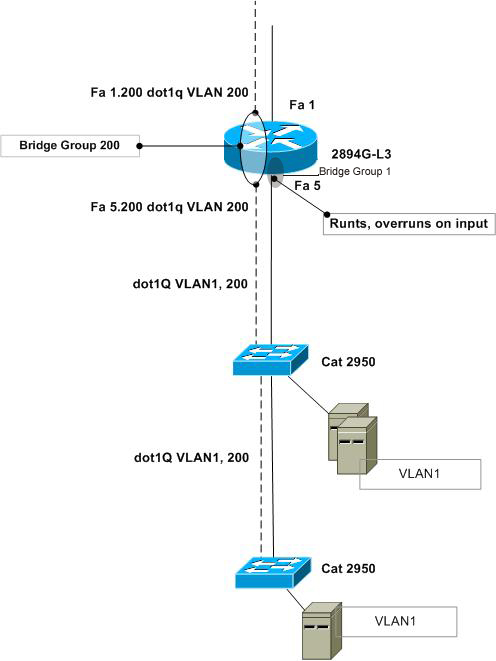
I have a network with a 2948G-L3 switch, a 2950 conected to it and another 2950 connected to the first 2950 (refer to the diagram). I am getting a lot of runts and corresponding number of overruns on the 2948 switch. It started a few days ago and seems to cause up to 100% of CPU load on the 2948G, 88% of witch are interrupts. The diagram should be self explanatory. Need help!!
- Labels:
-
Other Switching
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-14-2008 02:33 PM
Your network looks ok for the most part. One thing I notice is the 'daisy chaining' of catalyst switches. I'm not a big fan of this technique as it can cause undesirable network performance as network resource requirements grow throughout the network.
We must remember that a runt is simply a frame that is smaller than the accepted size for the specific L2 media in use; ie: 802.3 has a minimum frame size of 64 bytes.
Runts are created, for the most part, by collisions on the network or bad NIC hardware.
(sometimes nic software can be to blame)
A receiver overrun is when the buffer size of the interface, usually, is too big and it gets 'overrun' with data that it cannot process out of the buffers quickly enough. This causes data drops and, like collisions, TCP delays as the data has to be resent or in worst case scenarios, the tcp session has to restart with a SYN.
Likely it is collisions but the nic can be causing it as well.
Collisions are commonly the result of not enough bandwidth for the amount of traffic.
(or simply too many connections on a single L2 collision domain which can result in bandwidth exhaustion)
Since the problem is occuring on the Fa5 interface, if you can after hours, remove the connection from that interface and check if the problems cease. If they do, move down the line into the network.
(if the problems dont cease when disconnected, you could have faulty interface hardware)
Check the cabling, interface stats of the connecting switch(s), look for possible user systems connected to the switches generating alot of traffic, collisions or other errors.
If it turns out to be simply a 'bandwidth' issue, then think of creating load balanced links between the 2894 and 2950. (or etherchannels between switches wherever more bandwidth is required)
Please see the following link for info on etherchannels on 2950s:
http://www.cisco.com/en/US/tech/tk389/tk213/technologies_configuration_example09186a0080094bc5.shtml
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-14-2008 03:03 PM
The 'daisy chaining' is a legacy part of thenetwork which will be reconfigured shortly.
We have only 6Mb of truffic going through the interface 0n the 2948 and speed/duplex is fine on all uplinks between the switches.
The errors do stop and CPU load falls down to 4% from 100% if the Fa 5 is shut down, or the cable is removed.
All the interfaces on both 2950 are clear however. My conclusion was similar - one of the servers is to blame - a faulty NIC, or virus, or other software issue. I cannot however pinpoint the offending device, without shutting down interfaces one after another on the 2950s and monitoring CPU load on 2948 at the same time, which seems to be the only option left at the moment. We upgraded IOS on the 2948 and after that replaced the box - it did not help. Swapped the interfaces on the first 2950 and that did not help either.
A question - why runts would cause a high level of CPU interrupts?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-14-2008 11:04 PM
Normally, runts would not be passed through the switch, so I would tend not to suspect the servers. Runts are significant only on a single link. (Unless you have a cut-through switch.)
Runts will cause CPU interrupts because they ar exceptional errors, and so have to be handled in the CPU, Normally you should not have them.
Collisions normally do not produce runts. Collisions are a normal part of the contention protocol on a half-duplex connection. (Although some early versions of IOS on some switches do count them as errors, which is wrong.)
Except ... collisions can cause runts to be counted if you have a duplex mismatch. Suppose end A is playing full-duplex and end B is playing half-duplex. End B starts transmitting. End A sees the the frame coming in. End B has a frame to transmit, and believing it is full duplex, it goes ahead. End A says "whoops" and aborts its transmission.
End A counts this as a normal collision (which is not an error) or a late collision (which is). End B sees it as an aborted frame. If A has transmitted less than 64 bytes before it aborted, then B sees it as a runt as well.
Please check you duplex again ... not just the configuration, but the actually state as well. Your symptoms suggest maybe the middle Cat 2950 thinks it is half duplex, and the 4890 thinks it is full.
Is it possible the 2948 is forced full-duplex, and the 2950 is in auto?
Kevin Dorrell
Luxembourg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-15-2008 01:27 AM
Hi
Diplex is hard set to 100/full on both ends of the link between 2948G-L3 and 2950.
I also have a rather high level of cpu load on LSIPC BCAST PROC on 2948G-L3 - up to 13% sometimes and it seems to be related to how high the lvel of interrupts is at the moment.
Can a switch be configured as cut through? Is a 2950 a cut through switch?
Can a high level of EMI effect a cable and cause runts?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-15-2008 01:36 AM
If the duplex is hard coded, then that should be OK. In any case, if the duplex is full, the collision counters will always be zero. (There is no such thing as a collision in full duplex.)
As far as I know, none of the Cisco switches are cut-through. On the other hand, I don't know much about the 2948G-L3 blade, so that might be.
Yes, I suppose EMI could cause runts. In that case, you would most likely see a lot of CRC errors as well.
Could you post the counters so we can see what levels of what we are talking about?
Just to confirm, the link between the 2948G and the 2950 ... that is a normal crossed-cable link, without any intermediate hubs or anything, isn't it?
Kevin Dorrell
Luxembourg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-15-2008 02:01 AM
As far as we know it is a point to point link (we don't manage it) there may be some repeaters in it though.
Loggs:
CPU utilization for five seconds: 74%/62%; one minute: 74%; five minutes: 73%
29 155171016 54195552 2863 9.33% 8.18% 9.24% 0 LSIPC BCAST PROC
(the rest of proc are not taking anything)
*********************
CPU Interrupt Counters:
NP5400 Switch Fabric Interrupts 1862870813
Temperature Alarm Interrupts 0
Port Link Interrupts 185
PCMCIA Interrupts 0
FX1000 Interrupts 1710314212
Galileo and PCI Interrupts 32920841
Galileo Interrupt Counters:
Memory Address Out of Range 0
CPU Address Out of Range 0
Timer0 Overflow 32920841
PCI0 Master Read Errors 0
PCI0 Slave Write Errors 0
PCI0 Master Write Errors 0
PCI0 Slave Read Errors 0
PCI0 Retry Count Expired 0
PCI0 Address Errors 0
Memory Parity Errors 0
PCI0 Master Abort 0
PCI0 Target Abort 0
Spurious interrupts 0
PCI Interrupt Counters:
Fatal Bus Errors 0
Receive Watchdog Expired 0
Transmit Underflow 0
Receive Interrupts 0
Transmit Interrupts 0
*********************************
Show interface fa 5
MTU 1500 bytes, BW 100000 Kbit, DLY 100 usec, rely 255/255, load 1/255
Encapsulation 802.1Q Virtual LAN, Vlan ID 1., loopback not set, keepalive set (10 sec)
Full-duplex, 100Mb/s, 100BaseTX
ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:00, output 00:00:00, output hang never
Last clearing of "show interface" counters 00:52:03
Input queue: 0/75/5250/0 (size/max/drops/flushes); Total output drops: 0
Queueing strategy: fifo
Output queue 0/40 (size/max)
5 minute input rate 3586000 bits/sec, 791 packets/sec
5 minute output rate 543000 bits/sec, 523 packets/sec
2563204 packets input, 1471372905 bytes, 0 no buffer
Received 775 broadcasts, 5250 runts, 0 giants, 0 throttles
10500 input errors, 0 CRC, 0 frame, 5250 overrun, 0 ignored, 0 abort
0 watchdog, 729 multicast
0 input packets with dribble condition detected
1743676 packets output, 241267824 bytes, 0 underruns
0 output errors, 0 collisions, 0 interface resets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier
0 output buffer failures, 0 output buffers swapped out
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-15-2008 03:09 AM
I would ask the service provider whether it really is full-duplex. Maybe there is some half-duplicity in the middle.
Maybe it is auto in the middle, which would also explain your symptoms. Have you tried setting your switches both to auto and see what they negotiate?
- If it is straight point-to-point you will end up with full-duplex on both sides anyway, so good.
- If it is auto in the middle, you will and up with full-duplex on both sides, so also good because the thing in the middle will get to know you are using full-duplex.
- If there is something half-duplex in the middle you will end up with half-duplex at both ends, but at least they will be correct. So still good.
Kevin Dorrell
Luxembourg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-19-2008 10:39 PM
Victor,
Did you try auto at both ends, and/or asking the service provider if he does auto or hard-coded? I would be interested to hear the outcome so I can add it to my "experience bank".
Kevin Dorrell
Luxembourg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-23-2008 12:26 AM
Victor,
I don't know whether you have found a solution to your problem, but if you have it would be good if you could post it here. One of the motivations for people answering questions on NetPro is to benefit from each others' experience. Whether or not the suggestions were helpful, it would be useful to have some resolution. I have a particular interest in knowing the outcome of this particular problem.
Thanks in advnace.
Kevin Dorrell
Luxembourg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-15-2008 02:08 AM
1] Problem with IOS or bug in ios.
2] Problem with cables.
3] Change done in config for both the switch.?
4] Internal LAN change.
The point i have come down after going through this link.
I feel you need to really sit down and check your network for evry single machine.
http://www.cisco.com/en/US/products/hw/switches/ps700/products_tech_note09186a00800a7af0.shtml
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-15-2008 03:39 AM
Hi
I had a something of a similar experience, and it turned out that the path through the ISP wasn't set to 110/full at every point, so they had to correct that. It's quite a possibility that this can happen.
Dan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2008 06:33 AM
Hi
it took a while to sort out a change window and agree it with all the customers, hence a delay in my reply.
I shut down all the interfaces connected to customers servers on the 2950 switches one after another, while checking the number of runts on the 2948G-L3 interface and CPU load. It proved to be one of the servers at the end (an ISA server in fact).
Now I am trying to establish whether it is the interface on the 2950 switch (there are no errors on it by the way), to which the server is connected, or the actual server.
That will take some time cause we will need to agree to shut it down again. I'll keep you posted.
Accidently - anyone heard of a condition when an ISA server would cause runts?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-23-2009 03:02 AM
Nearly a year on and the problem has been resolved.
Even now I do not know exactly what traffic caused the runts and the high CPU load ( Even Microsoft could not help with it), but that it was generated, or passed on by a windows ISA server is a fact.
In order to get it all to work properly I ended up taking everything out of the VLAN1 (it was the original configuration, that I like to call "legacy") and shutting the VLAN1 down. That caused the 2948 switch to stop processing the "bad" traffic in software and hardware process it instead. Which in turn stopped all runts and overruns on the interface on the 2948 switch and the CPU load dropped from 99% to 5%. Everyone is happy.
One of the long lasting and utterly annoying problems has finally been resolved. Thank you everyone who got involved in the past :)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-23-2009 08:23 PM
Thanks for sharing this with us.
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide
