- Cisco Community
- Technology and Support
- Networking
- Switching
- Re: spanning tree vs loss of services
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2013 10:47 AM - edited 03-07-2019 12:01 PM
Hi,
Curious if spanning tree topology change can cause this problem.
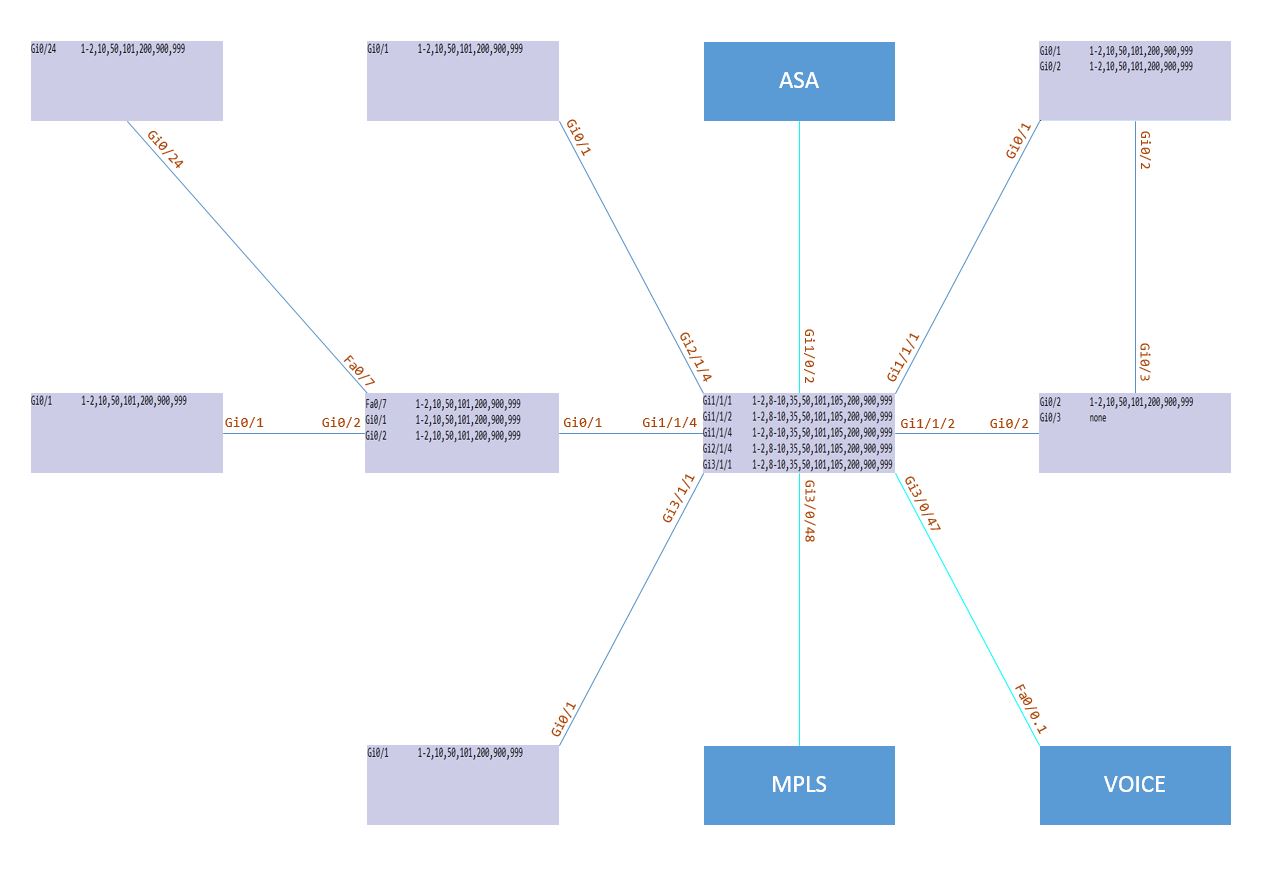
Please see graphics (2nd graphic shows vlans being forward on each switch). Core is 3750X stack and others are 3560s (no ip routing on those)
Users attached to switch E1 (and/or E2, not specified precisely) lose services when switch W1 is disconnected from the core.
Given loop in network switch E1 is blocking on port Gi0/3.
How could I determine if spanning tree is an issue in this scenario? What does "shr" port status mean in spanning tree detail?
Appeciate your helpful input.
Thanks.
Solved! Go to Solution.
- Labels:
-
Other Switching
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2013 06:47 PM
Do you recommend these ?
running UDLD and Loop Guard with RSTP
Enable BPDU Guard on portfast-enabled ports with RSTP
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2013 06:59 PM
Hello
As the Cisco Best practices documentation states:
BPDU Guard is recommended in portfast enabled ports.
Loop guard complements the protection against unidirectional link failures provided by UDLD. They work better together.
Regards.
Wilson B
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2013 07:16 PM
Sorry I have to ask:
Best Practices for a 6500 are exactly the same for a 3560 in this case?
Thanks for the link.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2013 07:28 PM
Hello
Thank for your question, the answer is Spanning-tree works the same way in a 2960s, 3560s, 3750s, 4500s, 6500s, 7600s................. the fact the platform changes doesn't make stp different. Off course just for spanning-tree in this case there're other features mentioned on the artitle that are not even supported in 3560. : )
Regards
Wilson B.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-18-2013 08:08 AM
Getting ready to make these changes. Is this the correct way to implement these features?
spanning-tree mode rapid-pvst
spanning-tree loopguard default
spanning-tree portfast bpduguard default
spanning-tree extend system-id
udld aggressive
errdisable recovery cause udld
errdisable recovery cause bpduguard
errdisable recovery cause channel-misconfig (STP)
errdisable recovery cause dtp-flap
errdisable recovery cause link-flap
interface GigabitEthernet1/0/1
switchport access vlan 700
switchport mode access
storm-control broadcast level 30.00
storm-control multicast level 30.00
no cdp enable
spanning-tree portfast
spanning-tree guard loop
interface GigabitEthernet1/1/1
switchport trunk encapsulation dot1qswitchport trunk native vlan 900
switchport trunk allowed vlan 1-1005
switchport mode trunk
switchport nonegotiate
storm-control broadcast level 80.00
spanning-tree guard loop
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2013 08:39 AM
")
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2013 09:00 AM
Hello,
Is that why pvst+ is sending out frames twice a second, since it doesn't have anyone (on the core) to talk to?
I am not quite certain if I understand your question. But from what I see in the attached JPG, there are PVST+ BPDUs for two VLANs being sent, VLAN 50 and VLAN 101. Each BPDU for a particular VLAN is being sent each 2 seconds which is the default Hello timer setting in STP.
The exhibit shows a perfectly normal propagation of PVST+ BPDUs in two different VLANs.
Best regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2013 09:10 AM
The shr device is an old printer.
The outage lasted several minutes until the switch was reconnected (mistakenly disconnected).
Does this add up to a spanning tree cause?
Thanks much for all of your help.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2013 09:32 AM
Hello,
Hmm, this does not really look like an STP issue after all (although your STP setup is currently not in the best shape). Are you by chance running VTP Pruning?
Best regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2013 09:37 AM
I didn't see VTP pruning running (need to recheck), but I did see more than one switch configured as a VTP server.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-09-2013 02:36 AM
Hello,
I apologize for not contacting you earlier... Is this issue still relevant? Please let me know. Thanks!
Best regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-09-2013 12:42 PM
Hi Peter,
Thanks kindly for checking back.
This issue will remain since I have to plan all of the changes with this company that we already discussed (getting all switches on one flavor of STP, etc). They have near zero tolerance for down time.
I agree the cause didn't sound like it was STP related based on the client comments about the timing of the resolution, but what else could it be?
I thought possibly since these two flavors of STP don't see eye to eye and they do have a planned loop in their network for redundancy the perhaps disconnecting a switch on the west side of the core triggered a topology change the other switches could not understand. The loop is in the East building and is on the switch directly connected to the core.
West Building (pvst)---->Core (rstp)---->East Building(pvst)
- « Previous
-
- 1
- 2
- Next »
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide