- Cisco Community
- Technology and Support
- Collaboration
- Contact Center
- Ask the Expert: Troubleshooting Unified Contact Center Enterprise
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Ask the Expert: Troubleshooting Unified Contact Center Enterprise
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-29-2014 05:15 PM - edited 03-14-2019 01:01 PM
 With Goran Selthofer
With Goran Selthofer
Welcome to the Cisco Support Community Ask the Expert conversation. This is an opportunity to learn and ask questions about integrating Unified Contact Center Enterprise into your environment and troubleshooting the many features that are available with the Unified Contact Center Enterprise solution.
Cisco Unified Contact Center Enterprise delivers intelligent contact routing, call treatment, network-to-desktop computer telephony integration (CTI), and multichannel contact management over an IP infrastructure. It combines multichannel automatic call distributor (ACD) functionality with IP telephony in a unified solution. This makes it easier for your company to rapidly deploy a distributed contact center infrastructure.
Goran Selthofer is a team lead for the Cisco TAC EMEAR Contact Center team based in Brussels. He has supported UCCE, UCCX, CVP, and UCCE applications for the past seven years within the Cisco TAC. He has more than 13 years of overall experience in the industry, with broad experience in Cisco Unified Communications infrastructure solutions as he has been also working for Cisco Gold Partner prior to joining Cisco TAC. Goran also provides internal training to TAC engineers on Contact Center topics. He graduated with a master's degree at the Technical Military Academy - Belgrade University. He also holds CCIE certification (number 27211) in voice as well as VMware Certified Professional certifications.
Remember to use the rating system to let Goran know if you have received an adequate response.
Goran might not be able to answer each question due to the volume expected during this event. Remember that you can continue the conversation in Collaboration, Voice and Video community, sub-community, Contact Center discussion forum shortly after the event. This event lasts through February 14, 2014. Visit this forum often to view responses to your questions and the questions of other community members.
- Labels:
-
Other Contact Center
- acd
- ask_the_expert
- ate
- call_treatment
- cisco_unified_contact_center_enterprise
- computer_telephony
- computer_telephony_integration
- contact_management_over_ip_infrastructure
- contact_routing
- cti
- multichannel_automatic_call_distributor
- multichannel_contact_management
- network_to_desktop_computer_telephony
- troubleshooting
- troubleshooting_ucce
- ucce
- unified_contact_center
- unified_contact_center_enterprise_solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-03-2014 03:11 PM
Hi Goran,
Thank you for covering this topic. My question is which logs do I need to check if I have issues with UCCE calls routing?
Thanks.
Jackson
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-04-2014 02:05 AM
Hi Jackson!
First of all I want to thank you for participating!
The most important thing to know first is THE CALL FLOW!
Knowing your call flow in details will reveal all nodes and processes which you should or can troubleshoot within logs.
Now, basically, there are different types of nodes being: Central Control, Peripheral Gateways, different peripherals and CTI services (server and desktops). Each of those have their own specifics in setting and collecting traces.
Therefore, we have published the following Tech Note to help partners/customers with setting and collecting logs:
http://www.cisco.com/en/US/products/sw/custcosw/ps1844/products_tech_note09186a0080c177d7.shtml
More details around that and much more serviceability is given within following guides:
Please let me know if this is sufficient for you!
Once again, thanks for participating!
Goran
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-03-2014 11:40 PM
Hi Goran,
What is the best/proper way to troubleshoot replication issue between Rogger/Logger A & B?
Is there an easier way to monitor the communication between A & B?
Thanks!
-JT-
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-05-2014 05:17 AM
Hi JT!
Thank you for the question!
…and…it is a very a good one … so it requires a very long answer
Ok, so usual confusion on that topic comes from the fact that users often think this should be similar to Microsoft SQL Replication. Thus, users expect to see something like GUI or visual presentation of that replication.
However, MSSQL REPL is not used here. Therefore, we need to understand architecture before we can think of ‘monitoring’ it. Also, to be very clear from the beginning, there is no ‘easy way’ of ‘monitoring’ it as there is no ‘tool’ for that.
Now, first, we need to separate Router from Logger because they get their data in a different way hence they have different way of syncing that and that is why they are to be observed separately.
Routers have MDS (Message Delivery Service process). Loggers do not have that process. However, Loggers use MDS of ‘same side’ Router. Logger on one side will never talk with Router on another side.
MDS is a sync zone, meaning every bit of data which comes to Router on one side is replicated through MDS to the Router on another side. Knowing that UCCE architecture utilizes two types of networks, MDS uses PRIVATE network for that communication. It is very active process since Routers sync their MEMORY. Therefore, that needs to be a perfect sync.
However, data which Router gets, router commits to the local DB and since Router doesn’t have DB, it means router commits that to the same side Logger’s DB. That is how Logger gets data. So, data bit which came from PGA to RTR (not relevant how at this point) ends up first in MDS on Router A side (assuming PGA has active link with RTRA) which is replicating it to Router B where it ends in both routers’ memory. Now, EACH router commits that to its own respective Logger.
Bottom line here is the following:
- Routers sync their memory and that cannot be easily ‘monitored’ but RTR processes are designed in such a way that if there is a difference then they will for sure complain and it will go even up to the point that one side process will not even be able to start or it will restart if not able to go in sync. So:
- MDS though would be good start point to check if something goes wrong as it will report process or peer disconnects
- Also, RTTEST tool can be used to check if any failover happened and when or from which side sync was done.
- MDS though would be good start point to check if something goes wrong as it will report process or peer disconnects
- Loggers do get their data from respective Routers but Loggers also have a possibility to ‘sync directly’. This kind of sync is done via socket connection by RECOVERY (RCV) process and it can be monitored via RCV logs (in a basic logical fashion way – is there any errors or unusual behavior or not). So:
- RCV process logs for checking if it is all healthy on that side
- ICMDBA tool to quickly see if replication of new data is happening (Space Used Summary option from Data menu when Logger DB is selected) by monitoring Max date.
- RCV process logs for checking if it is all healthy on that side

Maybe not as you hoped to be but I have tried to give an overall perspective for other users reading it later as well…
Thanks,
Goran
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-05-2014 11:43 PM
Hi Goran,
Great explanation!
In the same line, I'm trying to get some clarification in regards to the automated truncation process in both UCCE and CVP database
a) there are default retention days for certain UCCE tables (some 14, 100, 1095, etc)
b) if not mistaken CVP is also 1095 days
My questions
a) Will ICMDBA start to auto truncate the tables once the threshold has been passed? (80%). How will it select which tables/data need to be truncated first?
b) If it's compulsory for me to keep all data at least for 1096 days, those retention period can be changed to reflect that? Dependency on sql db & disk space of course
c) Can we disable this automated truncation process?
c) How does it work in CVP report server?
Thanks!
-JT-
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-06-2014 10:40 AM
Hi JT,
Thanks!
Again very interesting questions!
Ok, so I will have to limit to UCCE side in this answer and leave CVP for other people in other sessions.
But I think CVP part is already well described in the CVP SRND/Guides.
Here is the story about PURGING in UCCE.
There are 2 categories with total of 3 types of PURGE which can happen from UCCE point of view:
Category 1: Scheduled Purge
--------------------------------
1. Daily scheduled purge
based on this RETENTION parameters:
HKEY_LOCAL_MACHINE\SOFTWARE\Cisco Systems, Inc.\ICM\
Tables are purged usually at 00:30 every day - controlled by this parameter:
HKEY_LOCAL_MACHINE\SOFTWARE\Cisco Systems, Inc.\ICM\
Category 2: Emergency Purge
--------------------------------
There are 2 parameters to control this under this path:
HKEY_LOCAL_MACHINE\SOFTWARE\Cisco Systems, Inc.\ICM\cim\Distributor\RealTimeDistributor\CurrentVersion\Recovery\CurrentVersion\Configuration\Purge\Automatic
1. AdjustmentPercentage Purge on 80%
2. PercentFull on 90%
Both are set to purge 1% when DB reaches respectively 80% or 90%.
WARNING: ABOVE REGISTRY KEYS SHOULD NOT BE CHANGED!!! DOING THIS WILL MAKE YOUR SYSTEM UNSUPPORTED!
Reason for this is very simple: ICM processes are in charge of filling data into DB hence ICM needs to keep DB under 80% in order to compensate for the data burst while at the same time ensuring proper performance on process level interacting with DB.
Now, how is the PURGE done is very simple: Purge oldest data but fist but start from Tables starting with letter A.
So, usually it will be oldest data in Agent tables to be purged first.
Here is the drawaback of that approach:
Since it is set to purge 1% of data, just to make DB go under 80% usage, so to 79%, that means that if Agent table is purged with certain number of rows which dropped usage of DB to 79% then purge will stop. However, if there are still incoming data into DB making DB to go to 80% again, then again PURGE will be triggered with the same logic - start from A and purge 1%. So, if your DB is bouncing between 80% and 70% then it can easily happen that your Agent_ tables are purged totally thus making your reporting which depends on those tables not possible.
90% purge works the same way however, when it reaches 90% no new data will be allowed into DB.
So, you can argue with this but you have to keep in mind one SIMPLE RULE:
This is an EMERGENCY action.
Your tasks as system admin or system architect is to design the sytem in that way to AVOID reaching 80% full DB at any time.
So, answer to your a) question is above. keep in mind that it is not ICMDBA tool who is doing that but the code itself.
Answer to your b) question is also above (keys for retention). Of course, you should use ICMDBA tool here, option to Estimate your DB size based on required retention periods and then ensure you have that disk space there already before increasing retention times.
Asnwer for c) - NO. Definitelly NO!
Thanks,
Goran
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-06-2014 01:15 PM
Hi Goran,
That clarifies several doubts
To confirm
a) There is no dependency between scheduled & emergency purge. i.e. tables with pass the retention period will still be purged regardless of how full/empty the database is?
b) Is there a reference/link/doc that states all the current default retention period?
c) What is the trend seen for financial customers in relation to the retention period? Higher retention for interval/halfhour tables & lower retention for detail/event based tables?
d) If data grows faster than initial calculation, i would still be able to expand the database (subject to disk space availablity)? This link is also applicable for the current version?
http://www.cisco.com/en/US/products/sw/custcosw/ps1001/products_tech_note09186a0080094927.shtml
Thanks!
-JT-
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-07-2014 12:12 AM
Glad to hear that JT!
to answer your questions:
a) There is no dependency between scheduled & emergency purge. i.e. tables with pass the retention period will still be purged regardless of how full/empty the database is?
Answer: CORRECT
b) Is there a reference/link/doc that states all the current default retention period?
You can find it in Admin Guide:
I don't think HDS is mentioned there but for 'All Other Historical Tables' in HDS I believe it is 1095 days.
c) What is the trend seen for financial customers in relation to the retention period? Higher retention for interval/halfhour tables & lower retention for detail/event based tables?
Answer: CORRECT. However, mind that there are also some different rules forced by law in some countries telling how long data should be kept.
d) If data grows faster than initial calculation, i would still be able to expand the database (subject to disk space availablity)? This link is also applicable for the current version?
http://www.cisco.com/en/US/products/sw/custcosw/ps1001/products_tech_note09186a0080094927.shtml
Answer: CORRECT and CORRECT.
However, PLEASE do not take that as 'a primary line of success' - meaning - I will just put now what I 'think' it is good as anyhow we can expand it later. That decision might cost your customer some data loss since UNTIL you are enaged back to expand it, almost for sure there has been a problem already and data started to drop.
Therefore, probably daily we have at least one TAC CASE opened asking 'where is my data'. This is because improper estimation is done during the deployment about retention periods compared to DB size. So, customer wanted to retain 3 years of data and retention periods are set according to that WISH. and that is nothing more than a WISH. However, in order for that to become reality then DB size also needs to follow that WISH. Well, DB size was left to 40 GB and then 'suddenly' everyone is wondering 'why I am losing data since I have configured retention period on 3 years'
I hope I have given you a clue - why is that
Also, if reporting is so important to customer, we do recommend HDS on both sides and regular backups and DB maintenance.
Cheers!
Goran
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-10-2014 01:03 AM
Hi Goran,
In relation to log reading that Cisco TAC does, is there a reference/list of the common errors that will appear in the respective processes.
For example
a) Connection to Central Controller side A failed
b) Connection to Central Controller side B failed
c) Connectivity with duplexed partner has been lost due to a failure of the private network, or duplexed partner is out of service
d) others
Other logs typically have certain key identifier if that particular log is just info, warning, error, fatal, etc Something like this will definitely speed up the troubleshooting process.
Thanks!
-JT-
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-10-2014 12:06 PM
Hi JT!
Good questions!
However, the least Cisco TAC is doing when reading logs is that it is using some ‘magic cheat sheet’ to decode all traces.
No, we simply work as per experience and read traces knowing or getting ‘good’ examples or simply reading ‘error’, ‘exception’, ‘fail’, ‘timeout’ keywords and take it from there.
It is a long and hard process to read logs and the more you do it the more it starts to get some meaning - like Matrix ••J
So, bottom line: No, there is no reference/list of common ‘process’ errors except for what is already published for maybe Router here:
http://docwiki.cisco.com/wiki/Router_Error_Codes
Also, as described in one of the above posts you can use checke tool to see what is the peripheral error mapping – code to description:
- Peripheral Error Code Descriptions
A quick way to obtain the description for UCCE Peripheral Error Codes is to log onto a UCCE system is to open a command prompt and navigate to C:\icm\bin directory and "checke
Now, although most of the processes are not completed from serviceability point of view to document/list all possible errors, intention of BU is to directly write in logs as much details as it can be done to give more clues of what is happening.
Examples of Error messages in logs:
Failed to update the database.
The Update succeeded at the controller but was not propagated back to the Distributor.
Check the status of UpdateAW on the Distributor.
Or:
Failed to update the database.
Another user has changed the configuration data. Re-retrieve the data and try save again.
If the problem persists, you need to reload your local database. You can do this using
the Initialize Local Database tool.
Thanks,
Goran
Cisco TAC


- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-04-2014 06:25 AM
Goran,
Troubleshooting Finesse issues seems to be a huge pain, do you have any tips for that? For example, sudden logout errors, sudden failover messages, etc.
Thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-05-2014 08:40 AM
Hi David!
Thank you for being part of the event!
Indeed! Finesse can be a bit tricky as it is a fairly new product...compared to CTIOS or CAD.
However, luckily we have our internal engineers in CAP, BU and TAC, who are creating more and more use cases in internal and external knoweledge databases about Finesse.
As a result the following pages are made externaly visible the same way as we have them internaly:
http://docwiki.cisco.com/wiki/Troubleshooting_Cisco_Finesse
I definitelly advise that you check those!
Examples:
Problem Solving process:
http://docwiki.cisco.com/wiki/Additional_troubleshooting_information_for_Cisco_Finesse_8.5
Client Error: Client requests constantly result in "503 Service Unavailable" Error:
Replication issues:
http://docwiki.cisco.com/wiki/Replication:_Check_status_and_fix_replication_errors
Or, here is an useful tip which you might not find there yet:
How to check the Health of your Finesse Server
The SystemInfo API doesn't require authentication and will provide you with either an "IN_SERVICE" or "OUT_OF_SERVICE" status
Point your browser to the following url
http://
The status wil only show IN_SERVICE when all Finesse components are on-line.
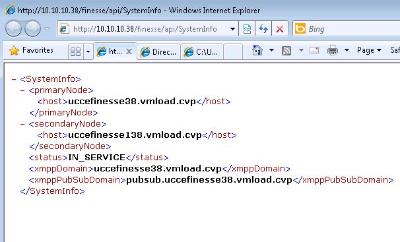
Not to repeat links, I will also post in the next reply below the link for troubleshooting Finesse Agent Login Trace with the Use of Logs since below question is more specific to that part...
I hope I have given you a clue but if anything else is needed, you know where to find us
Thanks,
Goran
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-07-2014 08:52 AM
Goran,
Going back on the Finesse issue(s). I'm experiencing an issue where the phonebooks changes aren't reflecting to the agent desktop. Any thoughts on how to troubleshoot this?
Thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-07-2014 10:17 AM
David,
Unfortunatelly, Finesse version is not shared and also more details like - i.e. phonebook changes are not reflecting but is it consistent for both servers if duplex server deployment) or only for one...all changes from certain time, all the time or intermittent...etc...etc...
In above post I shared Problem Solving process where there are lots of questions shared which might help to isolate.
This is probably not very popular to be asked to answer as some think that is a waste of time but this is how TAC resolves more than 65% of cases believe it or not
Those questions actually come from well-known Kepner-Tregoe Problem Analysis methodology and are used in troubleshooting diffent issues, not only in IT. Every Cisco TAC engineer is required to pass KT training so to be able to use it.
OK, so back to the issue, I will assume you are not on 10.0 release hence it might be that you are hitting known issue:
CSCul20619 CCE and CCX: PhoneBook update not shown on desktop after DB restart
There are some issues in seeing this defect from outside currently but it is marked as external so will be visible in the future. Anyway, the workaround is to restart Cisco Tomcat.
Please check if that resolves it for you and let me know. (Note: restart Cisco Tomcat out of production hours).
Now, if you want to troubleshoot Finesse for that issue then here is what usually you do for logs:
Substitute your primary Finesse server IP Address in this url for collecting the logs.
http://XXX.XXX.XXX.XXX/finesse/logs/webservices/
Capture of the Web Services logs, but in this sequence:
All on primary Finesse Server:
1) Agent logs out of Finesse
2) Stop Tomcat Service
3) Start Tomcat Service
4) Make some changes to phone book (note what exactly)
5) Agent logs into Finesse
6) Agent attempt to make call and options window is open showing available phone books.
7) Collect Web services logs from the time Tomcat is restarted until just after the attempt to make a call and missing or incomplete phone books are observed.
Be careful, this is service impacting, so do it after hours. Also note, Tomcat restart might resolve the issue as well as mentioned above so you might not be able to reproduce it.
How to collect the Error and Desktop logs for review:
1. When agent sees that issue on the desktop have the agent hit "Send Error Report" on the desktop.This will send the client side logs to the Finesse server.
2. Use the cli command to collect all Finesse logs - file get activelog desktop recurs compress
3. Collect CTI server logs from the time of Finesse tomcat restart to the time the agent sees the issue on the desktop. (Healthcheck)
I hope this helps!
Have a great weekend!
Thanks,
Goran
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide