- Cisco Community
- Technology and Support
- Collaboration
- Contact Center
- Ask the Expert: Troubleshooting Unified Contact Center Enterprise
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Ask the Expert: Troubleshooting Unified Contact Center Enterprise
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-29-2014 05:15 PM - edited 03-14-2019 01:01 PM
 With Goran Selthofer
With Goran Selthofer
Welcome to the Cisco Support Community Ask the Expert conversation. This is an opportunity to learn and ask questions about integrating Unified Contact Center Enterprise into your environment and troubleshooting the many features that are available with the Unified Contact Center Enterprise solution.
Cisco Unified Contact Center Enterprise delivers intelligent contact routing, call treatment, network-to-desktop computer telephony integration (CTI), and multichannel contact management over an IP infrastructure. It combines multichannel automatic call distributor (ACD) functionality with IP telephony in a unified solution. This makes it easier for your company to rapidly deploy a distributed contact center infrastructure.
Goran Selthofer is a team lead for the Cisco TAC EMEAR Contact Center team based in Brussels. He has supported UCCE, UCCX, CVP, and UCCE applications for the past seven years within the Cisco TAC. He has more than 13 years of overall experience in the industry, with broad experience in Cisco Unified Communications infrastructure solutions as he has been also working for Cisco Gold Partner prior to joining Cisco TAC. Goran also provides internal training to TAC engineers on Contact Center topics. He graduated with a master's degree at the Technical Military Academy - Belgrade University. He also holds CCIE certification (number 27211) in voice as well as VMware Certified Professional certifications.
Remember to use the rating system to let Goran know if you have received an adequate response.
Goran might not be able to answer each question due to the volume expected during this event. Remember that you can continue the conversation in Collaboration, Voice and Video community, sub-community, Contact Center discussion forum shortly after the event. This event lasts through February 14, 2014. Visit this forum often to view responses to your questions and the questions of other community members.
- Labels:
-
Other Contact Center
- acd
- ask_the_expert
- ate
- call_treatment
- cisco_unified_contact_center_enterprise
- computer_telephony
- computer_telephony_integration
- contact_management_over_ip_infrastructure
- contact_routing
- cti
- multichannel_automatic_call_distributor
- multichannel_contact_management
- network_to_desktop_computer_telephony
- troubleshooting
- troubleshooting_ucce
- ucce
- unified_contact_center
- unified_contact_center_enterprise_solution


- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2014 09:25 PM
Dear Goran,
Thank you for initiating the session and well explanation of the solutions.
having a query on CAD.
frequently, the agent log statistics in supervisor desktop doesnt display anything. it shows blank. could you please let us know how can we troubleshoot this issue. we frequently restart Cisco Enterprise service, Recording and Statitcs service and if the issue not resolved we go for Chat service and sync service.
but some time the issue doesnt get resolve. so kindly request you to give us how it works and what will be responsible for this.
Regards,
Shalid
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-10-2014 11:23 AM
Hi Shalid,
Thanks for the question!
OK, so CAD is one of the components which is integrated with CTI/CTIOS levels on ICM side. However, CAD is managed on its own with separate NT services and tools (like PostInstall).
Now, you didn’t send the version of your CAD (as there has been some changes in replication) but in general, Recording and Statistics Service is responsible.
Also, not sure if you are using Flat Files or SQL replication for RASCAL as that works totally in a different way. Also, people often mix LDAP and RASCAL replications.
Be Aware! LDAP and RASCAL are separate and independent databases.
- In current versions, RASCAL uses XML files (flat files) or SQL on the UCCE PG as the datastore (Informix in UCCX). It stores data in three tables: FCRasRecordLog, FCRasCallLogWeek and FCRasStateLogToday. Flat files are in \Program Files\Cisco\Desktop\databaseTeamName folder on both the Primary and Secondary CAD Servers.
- Sync Service uses LDAP (OpenLDAP), which syncs with the ICM AWDB to pull in agent, team and skill config information for the CAD Logical Call Center (LCC). Additionally, workflow group and phonebook customization is also stored within LDAP.
I imagine that you might have maybe issues with RASCAL replication there in your environment and that with restarts you are just triggering back working side. Due to the limitation of this ask/answer sessions I would invite you that you open case with Cisco TAC when you experience such issue so that it can be troubleshooted. In brief, Flat Files are NOT guaranteed mechanism of retaining statistics.
As a first aid, I can offer often used procedure done to re-establish broken or corrupted replica:
Login as LOCAL USER ADMIN on PGA side.
Start Post Install.
UNCHECK Rascal replica (select ‘Off’ for Recording and Statistics Replication and click Apply)
Follow prompts.
Once that is done then close Post Install and launch it again.
Now select ON for the same option and follow prompts.
This should re-establish replica if everything else is good.
Thanks,
Goran

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-10-2014 12:17 AM
Hi Goran,
When it comes to UCCE (ICM + CVP in comprehensive mode), what is the proper way to configure the system to be able to conference & warm transfer to an IVR, while maintaining the CTI data?
Note that we usually go for "send back to originator" configuration only when it comes to the network vru label. Is this correct?
Also, would that method require additional resources (media resources, licenses, ..) ?
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-10-2014 01:21 PM
Hi!
Hmmm… interesting questions… although this topic is limited to UCCE side of a story in order to avoid CVP as a potentially big session on its own, let me try to address this with quick answer here:
First, let’s clarify what UCCE means just to avoid confusion. UCCE is not ICM+CVP. UCCE is ICM+CUCM. And ICME is ICM+TDM ACD.
However, I do acknowledge that we have the same issue within some of our documents when referring to one or another.
Ok, now, let’s see about the transfers!
Not sure about the exact call flow and requirements there but here is where we specify which transfers are supported:
Transfer and queue calls with Unified CVP
Now, specifically for this there is a special chapter:
Unified ICME Warm Consult Transfer/Conference to Unified CVP
As far as ‘send to originator’ option goes, this is what needs to be known:
Three types of DNs work with Send To Originator: VRU label returned from ICM, Agent label returned from ICM, and Ringtone label.
Send To Originator does not work for the error message DN because the inbound error message is played by survivability and the post-route error message is a SIP REFER. (Send To Originator does not work for REFER transfers).
Note: For Send To Originator to work properly, the call must be TDM originated and have survivability configured on the pots dial peer.
On the top, there has been lots of discussions around this in the past on cisco forums. One of the best contributors there is Geoff and here you can find some example steps coming from his kitchen:
https://supportforums.cisco.com/message/3182315
Thanks,
Goran
Cisco TAC
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-10-2014 01:28 PM
Thank you very much for your replies
Sent from Cisco Technical Support Android App
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2014 09:43 AM
Hello Goran,
We upgraded a couple clients onto our HCS environment. Since we have had a couple outages where the A side loses connection with the B side. Normally this is related to some network interruption and it appears that way in the logs. However when I look in the system event viewer on the call server I see the following:
Log Name: System
Source: Tcpip
Date: 2/10/2014 6:39:07 PM
Event ID: 16501
Task Category: None
Level: Information
Keywords: Classic
User: N/A
Computer: USPHXXXXX
Description:
Computer QoS policies successfully refreshed. Policy changes detected.
AND
The Advanced QoS Setting for inbound TCP throughput level successfully refreshed. Setting value is not specified by any QoS policy. Local computer default will be applied.
I can match these up before every outage. As you guys know after 8.5 Cisco switched from packet scheduler based qos to the group policy. So I'm wondering if anyone else has seen this in 9.0. The first time I thought maybe it was coeincedence but since have seen it on other outages on completely seperate instances. The thing I wonder is if this is just an affect of an outage but I see this before is loses connection to the call server's duplexed partner. So believe it may actually be the cause. Any info you could provide on these messages I would appreciate. Because it is the first time we are seeing it with the upgrade to UCCE 9.0
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-12-2014 06:30 AM
Hi Jay!
Thanks for joining!
So, from MS site more info just when this is being read by someone who wants to have all info in one place :
Event ID 16501 — QoS Policy Update
http://technet.microsoft.com/en-us/library/dd379850(v=ws.10).aspx
Quality of Service (QoS) policies are applied to a user or computer account by using Group Policy. The QoS policies are applied to a Group Policy object (GPO), which is then linked to an Active Directory container, such as a domain, site, or organizational unit (OU), that contains the user or computer account.
Event ID 16504 — Advanced QoS Settings
http://technet.microsoft.com/en-us/library/dd392964(v=ws.10).aspx
"Advanced Quality of Service (QoS) settings provide additional controls for IT administrators to manage computer network use and DSCP markings. Advanced QoS settings apply only at the computer level, whereas QoS policies can be applied at both the computer and user levels."
OK, honestly, I cannot say I have seen this in 9.0 yet but I did see that in 8.5. Maybe 3-4 times so far.
One was related to the following known issue but that got resolved with 8.5.4 and 9.0.1:
https://tools.cisco.com/bugsearch/bug/CSCty16732
but that is only if you also see something like this in even viewer logs:
Tcpip 16710 None "QoS failed to read or validate the ""Local Port"" field for the computer QoS policy ""CISCO-ICM-QOS-RPORT-5000***""."
Another cases got resolved with following below recommendations to the letter (hard to pinpoint as sometimes multiple changes are done at the same time):
Basically:
===========
*** Ensure full redundant supported design is in place: Visible and Private should not share the same NIC, vNIC, vSwitch, switch...:
http://docwiki.cisco.com/wiki/UCS_Network_Configuration_for_Unified_CCE
*** Upgrade to last NIC drivers from NIC vendor or for UCS compatible as per:
http://www.cisco.com/web/techdoc/ucs/interoperability/matrix/matrix.html
*** Disable TOE, TCP Chimney, RSS and IPV6 on all servers. Disable LRO for ESXi ...:
and
http://docwiki.cisco.com/wiki/Contact_Center_Networking:_Offload,_Receive_Side_Scaling_and_Chimney
(for CSS)
*** Ensure that old ICM Security Template policy supplied for Windows 2003 is not applied to Windows 2008. That security hardening on windows 2008 is neither needed neither supported.
Please refer Security Best Practices Guide for Cisco UCCE 8.x,
"Note: Account policies are overwritten by the domain policy by default. Applying the Cisco Unified ICM Security Template does not take effect. These settings are only significant when the machine is not a member of a domain. Cisco Recommends that you set the Default Domain Group Policy with these settings."
Not directly related as above is about account policy but it is applying Domain Group Policy which in turn can also have above QoS features.
*** Upgrade of BIOS:
https://tools.cisco.com/bugsearch/bug/CSCty96722
Now, generally, for troubleshooting some of those 'connectivity' issues, you can start by using Client/Server tools within UCCE or much better ICMNetGen. So, within c:\icm\bin you will find all.
I am attaching document to explain usage of ICMNetGet and Client/Server tool.
Thanks,
Goran
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-12-2014 10:54 AM
Thanks Goran. Some really good info in your post. And we've seen lots a problems if your VM settings are incorrect. So that is always the first thing we visit when approaching an issue as this.
I have to think it's some type of defect. Interesting the defect in previous release. Although we don't see that message. Just one no one has seen yet. And tough to catch because the problems masks itself as a network failure.
We are going to try and re-run setup and disable all the policies. See if that takes care of the issue. If it does, then we know 100% this is the cause and we'll have to work with TAC on the defect.
But think you for taking a look and for the docs. Really appreciate the Netgen. Have never used that.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2014 11:45 AM
Hi Goran,
I understand that MS SQL Server will consume as much memory as possible since it wants to cache as much as possible into memory, however, I'm having a difficult time interpreting the Serviceability Best Practices Guide. I have a customer that's concerned with their memory utilization on their AW-HDS and Rogger, but I need to be able to decifer the formula in the guide to really dig into this more.
- Is memory utilization a good indicator to monitor strenuous events the server might be experiencing? I say no, but I'd like to hear the experts opinion.
- Referencing the image below:
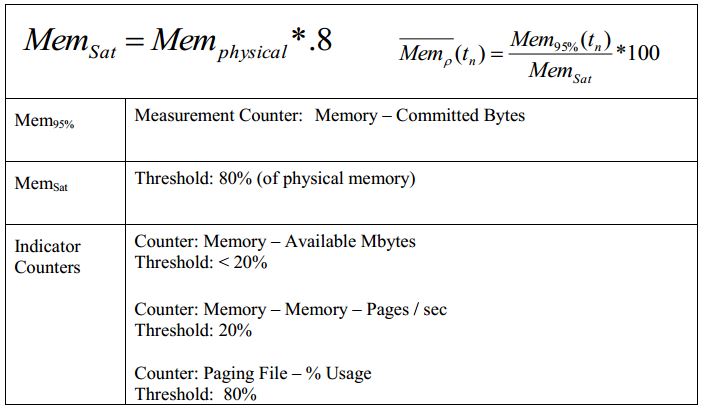
Let's take for example a Rogger that has 6GB of memory (6442450944 bytes) , I will use numbers that's displaying on the Rogger as of this writing:
Commited: 6442450944 bytes
Utilized: 6123421696 bytes
Free: 319029248 bytes
According to the image, anything less than 20% is crossing the threshold for available memory on the server.
(6442450949 - 6123421696) = 319029248 / 6442450949 * 100 = ~4.95 or 5%, which matches exactly what's in task manager. So the server is significantly lower than the 20% threshold, but again, how can this be a real indicator if SQL Server will take as much as it can? Am I misinterpreting all this? What exactly would be a good indicator, from an infrastructure perspective, that would tell me that a server is in fact healthy. I've attempted to leverage the counters that are collected by the node manager and saved to c:\icm\log, but again, I'm not sure what exactly is a good indicator to prove a healthy system.
Thank You
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-13-2014 10:04 AM
Hi Omar!
Sorry for the delay but you got me with these calculations now!
Ok, I am not sure where did you get figures from for that calculation as I was trying to use the same approach in my lab.
I will paste a screenshot here so that it is cleary which figures i used.
Now, one very important thing there. When it is mentioned like "Measurement Counter: Memory – Committed Bytes" that means Windows Perf Monitor counter.
Also, check page 104 in that document, under "8.1 Platform Health Monitoring Counters" there is a table for health monitoring. It lists Performance Objects. So, those are Windows Perf counters as well. You can use those for health check but with note below about SQL.
Now, calculation. Here is my snapshot:
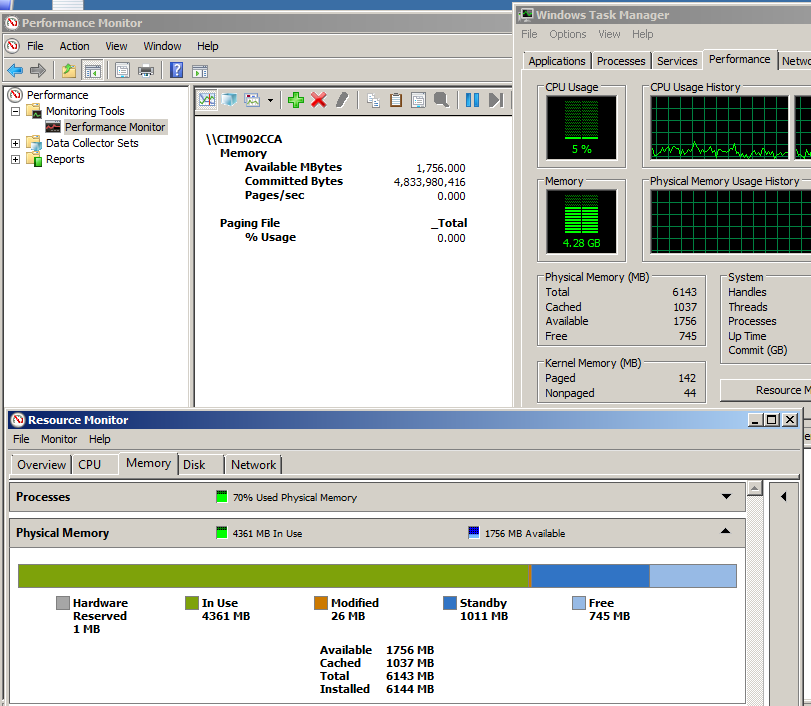
MEM physical = 6143 MB and that is 6441402368 bytes
MEM Sat = 80% of MEM physical and that is 4914 MB which is 5153121894 bytes.
My MEM 95% is Commited Bytes = 4833980416 bytes
So Mem p = 4833980416 / 5153121894 * 100 = 93.8
If you want to check Indicator Counter: Memory - Available Bytes with 20% threshold then my calculation is:
Counter: Memory - Available Bytes = 1756 MB
Total Memory: 6143 MB
Current threshold: 1756/6143*100=28.6%
In the end, SQL is indeed taking as much as it can and that is of no concern as per Microsoft:
http://support.microsoft.com/default.aspx?scid=kb;en-us;321363
"When you start Microsoft SQL Server, SQL Server memory usage may continue to steadily increase and not decrease, even when activity on the server is low. Additionally, the Task Manager and the Performance Monitor may show that the physical memory that is available on the computer steadily decreases until the available memory is between 4 MB and 10 MB.
This behavior alone does not indicate a memory leak. This behavior is typical and is an intended behavior of the SQL Server buffer pool.
By default, SQL Server dynamically grows and shrinks the size of its buffer pool (cache), depending on the physical memory load that the operating system reports. As long as sufficient memory (between 4 MB and 10 MB) is available to prevent paging, the SQL Server buffer pool will continue to grow. As other processes on the same computer as SQL Server allocate memory, the SQL Server buffer manager will release memory as needed. SQL Server can free and obtain several megabytes of memory each second. This allows for SQL Server to quickly adjust to memory allocation changes. When you start Microsoft SQL Server, SQL Server memory usage may continue to steadily increase and not decrease, even when activity on the server is low. Additionally, the Task Manager and the Performance Monitor may show that the physical memory that is available on the computer steadily decreases until the available memory is between 4 MB and 10 MB.
This behavior alone does not indicate a memory leak. This behavior is typical and is an intended behavior of the SQL Server buffer pool.
By default, SQL Server dynamically grows and shrinks the size of its buffer pool (cache), depending on the physical memory load that the operating system reports. As long as sufficient memory (between 4 MB and 10 MB) is available to prevent paging, the SQL Server buffer pool will continue to grow. As other processes on the same computer as SQL Server allocate memory, the SQL Server buffer manager will release memory as needed. SQL Server can free and obtain several megabytes of memory each second. This allows for SQL Server to quickly adjust to memory allocation changes."
On the top, if there is a legal concern of low memory and paging is often, then adding extra memory to VM is totally fine.
Cheers,
Goran
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-13-2014 10:28 AM
Wow, comprehensive and detailed. Thank you for the reply Goran!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-14-2014 09:01 AM
hehehe... thanks Omar! Please feel free to use those stars below the answer to let me know about the value of it!
and again, many thanks for engaging and asking those questions so that others can also benefit from it!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2014 11:51 PM
Hi Goran,
My question is about the AGPG failover mechanism..we faced a problem in one of our recent implementation where AGPG side B would not take over if we shut the services on side A, finally we had to involve TAC to sort it out.
He changed a set of registry settings on both the sides and it started working.
I wanted to know what all registry settings would I have to look into in such situations.
Thanks
Kishore
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-12-2014 07:00 AM
Hi Kishore!
Here is the simplest answer: NONE!
Well, what i mean to say is that there are no requirements to tweak registry settings for 'green field' deployments to make PGs to work duplex.
This is done by running PG Setup.
I am not sure which exact case you are referring to and what exact regsitry settings were changed but I can assume the following was the problem:
- ports used by MDS process were not matching.
Now, this can happen if you try to deploy more than 3 PGs on the same box (yeah, I know... customers will always say "No, we did not do it" ).
But, I am just giving one possible example. In that case, since only 2 are supported per box, MDS ports might get reused. Then, if you go back and forth via installer and changing PG numbers and/or sides then again you can end up in a similar situation due to the fact that previous setup was not yet finished.
Again, there should be no registry tweaks done normaly to make duplex works but you can ping me case number so I will take a look.
Cheers,
Goran
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-12-2014 12:21 AM
Hi Goran,
Thank you for initiating this discussion.
My question is what monitoring tools can be used to monitor UCCE in a perfect manner. Whether it is Cisco products or if you have an suggestion about third party tools.
Thanks
MK
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide