- Cisco Community
- Technology and Support
- Collaboration
- Collaboration Knowledge Base
- Chalk Talk: What Not To Do With UCCX
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 03-05-2013 10:18 PM
At TAC, we know that a Contact Center Express environment is rather sensitive; it needs careful handling, especially since the High Availability UCCX cluster is often the main “face” of our customers; the cash cow, so to speak.
We know that our customers handle everything to do with networking and Cisco at their end, and we try to help by explaining as much as possible, pointing out good reference documents, and explaining what we do and why. This helps you all resolve your issues before you need to reach out to TAC, and hence this article: “What Not To Do With UCCX”.
DRS Backups
We have a great backup and restore system that is as good as a snapshot built into CUCM and UCCX. However, when we ask “How old is your last-known good backup?”, we seldom hear what we want to.
Taking frequent backups is a good thing to do; it's a great way to ensure that a catastrophe does not cause your historical reporting, or those skillsets and application configs that you so carefully fine-tuned to vanish. Whether you take scheduled backups or a manual backup, always spare five minutes to read the Cisco Unified CCX DRF logs and ensure that the backups are successful. Just searching for "error", “exception”, or "fail" using WinGrep or a similar text file search tool is good enough.
We saw quite a few customers face major issues with silently-failing DRS backups, documented in Field Notice 63565 (http://www.cisco.com/en/US/ts/fn/635/fn63565.html): the backups would be reported as “successful”, but a crucial component (the LDAP database, A.K.A. the CAD component) would silently fail.
This is what their CCXCOMPONENT backup logs should have ideally shown:
**************************************************************************************************************
2012/04/16 10:24: Start: Backup CAD Component
2012/04/16 10:24: **************************************************************************************************************
2012/04/16 10:24: Calling CAD component backup scripts
2012/04/16 10:24: Executing cmd: /opt/cisco/uccx/drf/backup/cad_do_backup.py /common/drf/backup.log
2012/04/16 10:24: Create Temporary directorys in staging area
2012/04/16 10:24: Backup LDAP
2012/04/16 10:25: Done executing Backup LDAP Script
2012/04/16 10:25: Backup recording files
2012/04/16 10:25: Backup config files
2012/04/16 10:25: Backup TUP file
2012/04/16 10:25: Backup Client MSI files
2012/04/16 10:25: Backup *lapd.conf file
2012/04/16 10:25: CAD component backup completed
2012/04/16 10:25: **************************************************************************************************************
2012/04/16 10:25: Finish: Backup CAD Component
2012/04/16 10:25: **************************************************************************************************************
However, this is what it was instead, in each case:
**************************************************************************************************************
2012/04/03 10:41: Start: Backup CAD Component
2012/04/03 10:41: **************************************************************************************************************
2012/04/03 10:41: Calling CAD component backup scripts
2012/04/03 10:41: Executing cmd: /opt/cisco/uccx/drf/backup/cad_do_backup.py /common/drf/backup.log
2012/04/03 10:41: Create Temporary directorys in staging area
2012/04/03 10:41: Backup LDAP
2012/04/03 10:41: Backup LDAP Script failed to work
2012/04/03 10:41: CAD component backup completed
2012/04/03 10:41: **************************************************************************************************************
2012/04/03 10:41: Finish: Backup CAD Component
2012/04/03 10:41: **************************************************************************************************************
Months later, when customers tried to restore these backups, they would be faced with a blank LDAP database and no way to recover it unless the High Availability server had not been touched by the DRS restore. This of course meant that agents and supervisors could not log in, and all workflows, skill information, and resource information was lost. All that pain could have easily been avoided by simply grepping through the backup logs for "error", “exception”, or "fail" and contacting TAC when it turned up positive. In fact, if you use OpenSSH on Cygwin or a Linux server, you can automate this grepping process with a simple BASH script.
Switch Version Failure
Another way data often gets lost is when customers lose patience with the switch-version section of a UCCX 8.x or 9.x upgrade: the switch-version process does not show a progress update and all too often, customers reboot the server because they think the process “hung”. During a switch-version, all data from the old version is copied across to the new version. Interrupting this process will result in the data becoming corrupt, and unusable. Switching version to UCCX 8.5(1)SU3 and above includes an option to recover from this. However, it is simply better to prevent; you can read the logs instead of wondering whether the process hung. Use the CLI command
“file tail install /uccx-install.log”
to get a scrolling display of the current status of the switch-version, from the install logs. That will give you a continuous progress update.
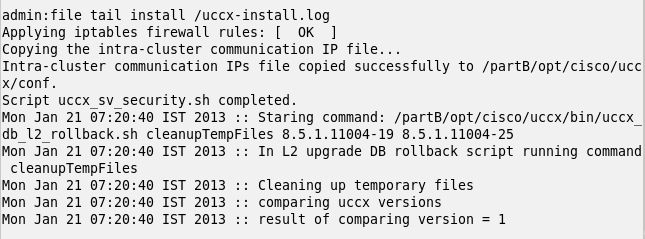
Figure one: scrolling progress for "utils system switch-version"
Reading Logs
Now that logs have been mentioned, let's talk about reading them. The UCCX Guides are a great place to start learning how to read logs. You can start with the Command Line Reference, from where you can get commands to view and search through the relevant logs. You can also use the UCCX Serviceability & Administration Guide to determine which logs to read for what issue and how to set the logging levels so that you get the information you need.
Again, searching for "error", "exception", or "fail" is a good way to start, although you will get false positives: “Exception=null” just means that there was no exception. Of course, if the Unified CM Telephony Subsystem is in PARTIAL SERVICE, just search for “partial” in the logs of its parent service: the Cisco Unified CCX Engine. The Serviceability & Administration Guide will tell you that “SS_TEL” refers to this subsystem, and searching for “partial” will show you lines where SS_TEL explains why it is in partial service.
Of course, you can also use the RTMT “Telephony Data” feature under the “Cisco Unified CCX” tab to identify why your Unified CM Telephony Subsystem is in PARTIAL SERVICE. This feature will clearly tell you which triggers (CTI Route Points), call control group members (CTI Ports), or JTAPI Provider users are in trouble and need to be fixed.
Log analysis is quite easy, once you understand how to go about it. Of course, you may want to start slow, perhaps by analyzing a log file where only 1 call is present. Here's a simple way to read a UCCX call as you would read a debug on a voice gateway:
- Find out which UCCX Engine log file is currently active, i.e. which log file is currently open. We know that UCCX Engine logs are named “Cisco001MIVRxxxx.log”. So, running this command should tell us which is the current active log:
show open files regexp Cisco001MIVR - Next, get all the telephony-related information in a scrolling display. You run “file tail” again as with the switch-version, but this time use the Engine log and include an option to only display lines matching the regular expression “SS_TEL”, which is the Unified CM Telephony Subsystem.
file tail activelog /uccx/log/MIVR/Cisco001MIVRxxxx.log regexp SS_TEL - Dial the UCCX trigger number and see the call scroll on your screen.
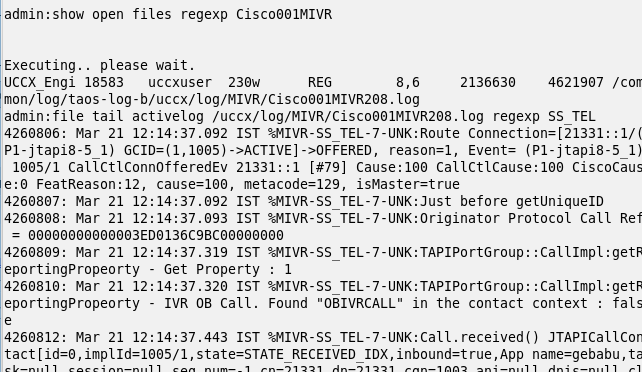
Figure 2: Scrolling progress for Engine Telephony Subsystem logs, with a call in progress
The Control Center and Datastore Control Center in the Cisco Unified CCX Serviceability portal are the best places to start gathering information on what's going wrong with your system.
Ensure that all your services in the Control Center show up in the status “IN SERVICE”. If any show a different status, use the drop-down button against the service name to identify which child service is not IN SERVICE.
For example: if your agents are unable to login, check the status of the RmCm subsystem under the Cisco Unified CCX Engine, Subsystem Manager.
The Datastore Control Center talks about database replication. If historical reports say that there is no data when the Publisher is the Master Node, but produce data when the Subscriber has Mastership, check the replication status.
In the “Replication Servers” page, both servers should be listed as “Active” and “Connected”.
In the “Datastores” page, each datastore should have read and write access enabled, and the replication status should be “Running”.
Network Time Prototocol
The importance of logs cannot be underlined enough. Log analysis is how TAC operates most of the time, especially when providing the root cause for issues that happened in the past and no longer occur. As UCCX is integrated with CUCM, TAC often needs to read logs from both products to fully understand the situation, and provide the most effective solution. It is essential to get the right time-frame from the customer for log analysis, as this helps narrow the focus and also ensure that the same calls are looked at within UCCX as well as in CUCM. However, time loses all meaning when the servers are not on the right time, and are in a situation of time drift. Unified Communications products use the Network Time Protocol (NTP) to ensure that the correct time is always maintained.
NTP is highly important for a Contact Center Express deployment: not only for correctness of logs, but also for historical reporting (imagine calls being reported as days-long because of NTP drift!) and with all communications going outside the UCCX server.
When your NTP goes out of sync on the UCCX/CUCM or worse, when your NTP server itself goes awry and starts reporting the wrong time, havoc breaks out. I have seen deployments where agents are unable to login because their PCs are reporting a different time than the UCCX, and all callers to UCCX hear a reorder tone because CUCM and UCCX are on different times.
UCCX sends a message timestamped “2013, March, 1st, 1200 hours” and the current time on CUCM is “2013, March, 2nd, 1200 hours”. CUCM thinks that the message received is a day old, and of course ignores it. Hence, CUCM and UCCX, as well as CAD and UCCX, are unable to talk to each other.
The lesson here? Always ensure that NTP is in sync on your CUCM and UCCX, and that the UTC time on UCCX and CUCM is the same. Try to use the same NTP server(s) for both, so that they follow the same leader.
The command
“utils ntp status”
will give you the NTP server which is currently being referenced and the current system time.
Please ensure that you only use Linux servers or IOS gateways as NTP sources; Windows NTP servers use a slightly different version of the protocol, and this will cause issues. Also, ensure that the stratum of the NTP server used is within 1-4.
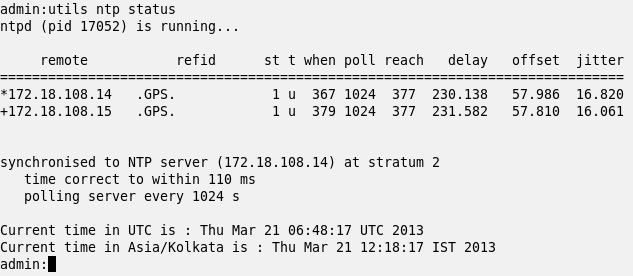
Figure 3:
High Availability over WAN
CUCM-UCCX communication and intra-UCCX communication should experience as little lag as possible. Customers who have deployed the High Availability Over WAN (HAoWAN) option will be familiar with this requirement.
However, we at TAC often see that the server communication is hampered by a very small mistake, which also prevents the HAoWAN feature from working as designed. Let's talk about HAoWAN before I get to this mistake.
There are 2 sites in a HAoWAN deployment, separated by a WAN link. This deployment option is designed such that in case of a WAN link failure, both sites will split into independent UCCX sites: they will operate in “island mode” till the WAN link comes back up and the cluster can communicate within itself again.
Logically, it is understood that there should be a CUCM and a UCCX at either site, at the bare minimum. Imagine this scenario where the WAN link goes down between Sites A and B.
- Site A's UCCX initially refuses to communicate with its CUCM, but instead reaches out to Site B's CUCM first. Site B's UCCX does the same, preferring to communicate with Site A's CUCM. Valuable time is lost in recovering from the WAN link failure.
- When callers are put on hold by Site A, they hear the familiar hold music, pleasant and soothing as always. However, callers who reach Site B hear only a disquieting silence, and drop out of queue in bunches because they suspect that their calls got hung.
- Callers who reach Site A get transcoded from G.729 to G.711 with no issues. However, callers who reach Site B get disconnected because their calls are not getting transcoded.
All this could have been avoided by following a simple mantra: Ensure that the UCCX first reaches out to the local CUCM. This entails the following configuration:
- The local CUCM is listed as the first AXL Provider, Unified CM Telephony Provider, and the RmCm provider for each UCCX node. This can be found in Appadmin > System > Cisco Unified CM Configuration.
- The Call Control Group configuration in HAoWAN is split in two: one half per UCCX. Ensure that the Device Pool and Hold Audio Sources selected for each half point to the local CUCM, and to local sources.
Unless the HA over WAN Best Practices are adhered to, the cluster will misbehave during a WAN outage, and WAN bandwidth consumption will needlessly shoot up.
Let's go back to what my colleague said: “If you don't have a phone, you cannot make calls”. This may seem fairly obvious, yes. However, what about a situation where the agent phone is present and it does have the IPCC extension on it, but UCCX does not know that this is the phone to which the call must be delivered?
I'm talking about sharing UCCX directory numbers, which is an unsupported configuration. UCCX requires that the directory numbers are unique across any partition: a CUCM Route Plan Report search (found under the Call Routing menu) for the DN should return exactly 1 result.
This applies to CTI Ports (Call Control Groups), CTI Route Points (triggers), and agent phone extensions.
This rule goes for the non-ACD extensions on the agent phones, too. The reasoning behind this? UCCX places JTAPI observers on these so that Cisco Agent Desktop can recognize when the agent is on a non-ACD call. Sharing a line with a JTAPI observer on it will result in the observer getting confused.
Troubleshooting
We really love it when we get a case with all the initial data already present in it. As this helps us in faster troubleshooting, it will help bring your call center back up faster.
This includes:
- The exact UCCX version string (this can be 7.0(1)SR05_Build504, 8.5(1)SU4, or 8.5.1.11004-25).
- Whether it is a single node or a HA cluster.
- The time when the issue started happening, or at least the time when the issue was first reported.
- The frequency of the issue, and the wideness of its impact. For example: are all agents impacted, or only some? If only some, what makes them different from those who are impacted?
- What changed just prior to the start of the issue. If you are aware of any changes to the network, the CUCM, the UCCX, or anything even slightly related to the UCCX, do let us know. It's better for us to get irrelevant information, than to miss relevant information. I once had a case where the agent PCs were entering sleep mode, causing CAD to disconnect! If only the network admin could have informed me of that...
- Any steps you have taken to try correcting the issue, or working around it.
Updates
Cisco regularly releases Service Updates (SUs) for UCCX, which contain important bug fixes and product enhancements. We also release Field Notices whenever issues of high importance crop up and we want our customers to be aware of them. Please try to be on the latest SU release; this is a proactive step you'll be taking towards protecting and nurturing the health of your Contact Center. Keep an eye out especially for Field Notices, and do follow the instructions closely when one comes out.
Conclusion
I have talked about DRS backups, understanding and reading logs and information using the tools and guides provided, and ensuring that best practices are followed. Hope this gave you food for thought, at least for those waits on hold with the TAC Front Line!
About the Author
Presently in the APAC shift, Anirudh Ramachandran has been working with Unified Contact Center Express TAC since the day he joined Cisco. While not solving service requests, he enjoys tea, photography, Linux, and using the kitchen as a laboratory.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Great discussion on HA over WAN and the errors we can make in the field. Thanks for taking the time to create this document. I will include this information in our UCCX courses.
- Marty Griffin, Contact Center Instructor, Sunset Learning Institute
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks for sharing
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Are there any update to this BLOG ? I was told by TAC that only the first 4 lines on the phone device were watched by a JTAPI observer. Is this still the case ? I have CSR's that are On-call and perform multiple duties which requires a unique "device profile" depending on the location and function for that day.
I am deploying a KEM to move unique lines away from the primary lines on the phone.
Any other suggestions ?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Larry,
Yes, that is still the case even with the latest version of UCCX i..e., 11. UCCX still monitors the first four lines of an agent phone. Below is the snippet from UCCX 11 Release Notes:

For your reference, I am providing you with the link for UCCX 11 Release Notes that will give all the details about new and updated features:
http://www.cisco.com/c/en/us/td/docs/voice_ip_comm/cust_contact/contact_center/crs/express_11_0/release/docs/UCCX_BK_R7697E6E_00_release-notes-for-uccx-solution.pdf
Regards
Deepak
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
An excellent and very helpful document.
Reading it, I've just found out that our implementer didn't get the correct AXL etc ordering on our HA subscriber and our UCCX backups have been silently failing for 3 years now with the LDAP bug...
This document has possible saved us from a complete s**t storm - thankyou!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi
In HA over WAN deployment model, is there a possibility to route finesse traffic over WAN optimizer ?
Below is the scenario:
Node1 @ Dallas
Node2 @ Miami
Agents are located @Dallas
During failover, Node2@Miami becomes Master and the agents from Dallas connect to current master which is Node2@Miami.
In such scenario, how to effectively optimize Finesse traffic over WAN using wan optimizer ?
Your suggestions are much appreciated.
-Thanks & Regards
Rajesh
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Is it possible to view dependency records for call control groups? Before deleting a call control group it needs to be determined if it is being used. There are way too many triggers to have to individually view to see if a specific call control group is being used.
Regards,
Julie
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks Deepak!
Question,
Is it possible to view dependency records for call control groups? Before deleting a call control group it needs to be determined if it is being used. There are way too many triggers to have to individually view to see if a specific call control group is being used.
Regards,
Julie
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Here's a tip:
Switch Version Failure
Another way data often gets lost is when customers lose patience with the switch-version section of a UCCX 8.x or 9.x upgrade: the switch-version process does not show a progress update and all too often, customers reboot the server because they think the process “hung”. During a switch-version, all data from the old version is copied across to the new version. Interrupting this process will result in the data becoming corrupt, and unusable. Switching version to UCCX 8.5(1)SU3 and above includes an option to recover from this. However, it is simply better to prevent; you can read the logs instead of wondering whether the process hung. Use the CLI command
The key word in that post is 'often'. So, a way data often gets lost is via known deficiencies in the update process, yet here we are five years later and Cisco still hasn't fixed this. It's compounded by the fact that other software in the unified communications suite has the same upgrade process, yet doesn't have the horrid delay when switching versions. We're taught by CUCM that it should go quickly, then find UCCX goes slowly, with no apparent CPU or disk activity while it is actually doing something, then a reboot is issued.
If the web interface can't be fixed, customers should be forced to upgrade via CLI. It would have saved me hours of wasted time today, and downtime. I would have been perfectly content to switch versions via CLI had I been given even the most simple of warnings via web interface that hey, this may take a VERY LONG time and you should use CLI instead if you want to know what's going on. Even that isn't good enough though, CLI will appear to hang forever too, so why not incorporate the tail command output into the switch command so you know it is actually doing something?
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community: