- Cisco Community
- Technology and Support
- Collaboration
- IP Telephony and Phones
- Cluster Database Replication problems
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Cluster Database Replication problems
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-17-2012 10:41 AM - edited 03-16-2019 01:44 PM
Hello,
Have 2 new c200-m2 servers. Have installed ESXi 5. Created publisher (8.6.2.20000-2) on one server and then had problems when creating the sub on the other server. Sub wouldn't verify connectivity to Pub. Finally got by that but when I checked replication status it was all messed up. After trying the stuff I could find on the forums I opened a TAC case. Three days later we were able to get the replication working. When I checked it from the CLI (utils dbreplication runtimestate) both nodes had a status of 2. When I checked via the GUI however, replication status was good but everything else wasn't. TAC Engineer stated that this was 'cosmetic'. We tried several things to reset the status but none worked. He said he would research this, I haven't heard back from yet.
Has anyone seen this issue? If so what was done to fix it?
Below is a screen shot of the DB replication status report.
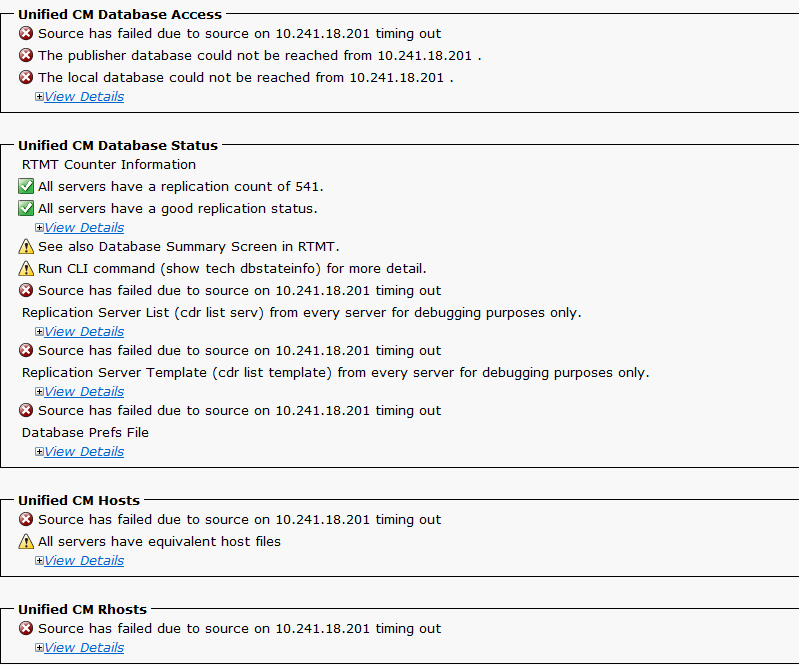
- Labels:
-
Other IP Telephony

")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-17-2012 10:48 AM
Hello,
See this doc:
https://supportforums.cisco.com/docs/DOC-13672
Regards
Leonardo Santana
Leonardo Santana
*** Rate All Helpful Responses***
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-17-2012 10:52 AM
Here are the utils dbreplication runtimestate from each node:
DB and Replication Services: ALL RUNNING
Cluster Replication State: Replication status command started at: 2012-10-11-17-36
Replication status command COMPLETED 541 tables checked out of 541
No Errors or Mismatches found.
Use 'file view activelog cm/trace/dbl/sdi/ReplicationStatus.2012_10_11_17_36_48.out' to see the details
DB Version: ccm8_6_2_20000_2
Number of replicated tables: 541
Cluster Detailed View from PUB (2 Servers):
PING REPLICATION REPL. DBver& REPL. RE PLICATION SETUP
SERVER-NAME IP ADDRESS (msec) RPC? STATUS QUEUE TABLES LOOP? (R TMT) & details
----------- ------------ ------ ---- ----------- ----- ------- ----- -- ---------------
SUCmgrPub xxx.xxx.xxx.xxx 0.046 Yes Connected 0 match Yes (2 ) PUB Setup Completed
SUCmgrSub xxx.xxx.xxx.xxx 0.361 Yes Connected 0 match Yes (2 ) Not Setup ??? (didn't notice this before)
DB and Replication Services: ALL RUNNING
Cluster Replication State: Only available on the PUB
DB Version: ccm8_6_2_20000_2
Number of replicated tables: 541
Cluster Detailed View from SUB (2 Servers):
PING REPLICATION REPL. DBver& REPL. RE PLICATION SETUP
SERVER-NAME IP ADDRESS (msec) RPC? STATUS QUEUE TABLES LOOP? (R TMT)
----------- ------------ ------ ---- ----------- ----- ------- ----- -- ---------------
SUCmgrPub 10.241.18.200 0.456 Yes Connected 0 match Yes (2 )
SUCmgrSub 10.241.18.201 0.060 Yes Connected 0 match Yes (2 )
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-17-2012 11:00 AM
I suggest you enter in contact with your Cisco TAC Engineer.
Leonardo Santana
*** Rate All Helpful Responses***
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-17-2012 02:17 PM
Hi,
When it's come to virtualisation please ensure that read the Cisco implementing virtualisation guide, particularly the section regarding the Installing and Configuring Esxi virtualisation software as below:
http://docwiki.cisco.com/wiki/Implementing_Virtualization_Deployments
The key caveat is that you must disable LRO as documented in the following link. This can adversely affect TCP connectivity, so have you specifically made these changes and restart the esxi host?
http://docwiki.cisco.com/wiki/Disable_LRO
Regards
Allan
Sent from Cisco Technical Support iPad App
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2012 06:46 AM
Allan,
Thanks for the great info! I have looked through those pages before but I didn't change any LRO params. I have now and rebooted both hosts but I still have the samed dbrep status in the GUI.
Mark
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2012 06:51 AM
Please try the following in the exact sequence, this works for me:
>> utils dbreplication stop on the subscriber and on the publisher. Wait the process finish on the sub and go to the pub
>> wait for a few minutes for it to finish
>> utils dbreplication dropadmindb on the publisher
>> wait for it to finish
>> utils dbreplication dropadmindb on the subscriber
>> wait for a few minutes for it to finish
>>utils dbreplication reset all on the publisher
I hope that this helps you.
Dont hesitate in contact your Cisco TAC Engineer responsible for your case!
Regards
Leonardo Santana
Leonardo Santana
*** Rate All Helpful Responses***
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-17-2016 08:32 AM
Absolutely confirmed working after following the steps from Leondardo Santana.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-18-2016 06:49 AM
Hello maybelynplecic,
Good to know that this procedure solved your issue.
Regards
Leonardo Santana
Leonardo Santana
*** Rate All Helpful Responses***
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2012 09:01 AM
Hi Mark,
Thank you for the rating, much appreciated. The DB replication status from the GUI and the CLI indicates that the status is good, connected and with matching replicate counts. Its the timeouts which is of concern, why the Subscriber is not responding when you generate the DB summary report.
Are you using shared LOM and/or dedicated Mgmt for CIMC? How have you configured the distributed switch in vSphere? I would be inclinded to start isolating from the physical level up, take a look at the switch ports for errors etc, and proceed from there.
Incidentally, do you have a valid and accessible NTP source as this can also adversly affect replication, but this is not the issue here.
Regards
Allan.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2012 10:25 AM
Hi Mark,
Hope all is well my friend
I just wanted to add a note to the great help you've received from Allan
and Leonardo so far (+5 guys!)
If the TAC engineer is referring to this as a "Cosmetic" issue then I'm
assuming there should be a Bug ID for this. I looked in 8.5, 8.6 & 9.0
for any related Bugs and came up empty. You can ask for this information
or ask for the case to be re-queued or escalated as well.
This newer doc has some nice Bug ownership tips.
https://supportforums.cisco.com/docs/DOC-27207
Cheers!
Rob
"May your heart always be joyful
May your song always be sung" - Bob Dylan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2012 02:13 PM
Gentlemen thank you all for the responses! Rob NO HOCKEY !!!! What are we going to do? Go to Europe and watch? hehehe
***THIS SYSTEM IS NOT IN PROD YET***. So I have some time but it is being built to replace an old ver 4 setup. You know I'd like to get it off my plate and move on.
Allan to answer your questions; NTP is configured and tested (at install time). NIC are set to Share LOM (CIMC). No vCenter so just running the standard vSwitch on each host.
This just keeps getting better all the time. I executed Leo's instructions exactly as he said. It had been 2 hours and the dbrep status wasn't returning back 2, it's stuck at 3 on each node. So I turned on some traces on the sub for DB monitor and replication. Found this error in replication scripts output repeated many times all the way to the end of the file:
Thu Oct 18 14:48:10 2012 dblmkrepl-plugin.delRemoteSub DEBUG: The syscdr database is missing!
, sqlcode=-329
ISAM error -111:
command failed -- Enterprise Replication not active (62)
Also in the 'startrpc' file:
Thu Oct 18 14:48:10 2012 dblrpc.delself DEBUG: Inside delself before returning retval = The syscdr database is missing!
, sqlcode=-329
ISAM error -111:
command failed -- Enterprise Replication not active (62)
dblrpc:
sh: line 0: kill: (1741) - No such process
SUCmgrPub - - [18/Oct/2012 14:48:10] "POST /RPC2 HTTP/1.0" 200 -
I noticed that after executing these commands that the services on the sub weren't starting, so I tried to start them but this error message:
| Update Failed for the Service(s): Cisco CallManager Service cannot be Activated or Deactivated due to Database Update Failure. |
So turned on autostart for the services for the node and reloaded it but it still wouldn't start the services.
As I stated at the start of this file I had a lot of trouble at the start getting the sub to synch up to the pub. I deleted the sub off the disk several times and recreated it. I'm just wondering of some piece of info or something didn't get deleted or corrupted new files. I'm almost at the point of scrapping the whole thing and starting over. Getting quite frustrated
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2012 03:05 PM
Hi Mark,
I understand your frustration, when replication goes wrong it goes wrong. First things first can you confirm whether the hosts/rhost correct for both nodes and that there were no host name changes or IP address changes following installation?
The cdrsys table is like to be missing due to the drop admindb steps as this removes the replication configuration forcing a reload of the configuration from the pub. I'm not aware that this is actually removed. The utils dbreplication clusterreset and reset all commands should reset the connections, but this is only providing certain db services are actually running?
Were the Cisco DB, Cisco DB Replicator and Database Layer Monitor service actually running or are these the services you were having problems with? If these services are running and providing the hosts/rhosts tables are correct try running the clusterreset followed by the reset all command on the pub again. Don't expect instance results as this could take considerable to time to complete.
What is the current DB status incidentally?
Regards
Allan
Sent from Cisco Technical Support iPad App
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-19-2012 06:52 AM
Hey Mark,
Yeah.....no Hockey I guess the millions aren't enough
anymore! And all this time I thought it was about
"the love of the game" (silly me!!)
With the issues you are having with this I'd really be tempted to start over
fresh here. If all the replication re-build steps are failing here and the "key"
services won't start there's probably "no joy" and you may be spending
more cycles trying to fix this than it would take for a do-over. As this is not
in production yet it seems like it might be the best bet.
Just a thought.
Cheers!
Rob
"May your heart always be joyful
May your song always be sung" - Bob Dylan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-24-2012 12:49 PM
I'm creating another cluster. Allan thanks for your responses. I did check the hosts file on both nodes and they were okay. The db status changed to 3 after executing the commands you suggested. No services will start on the sub with the same 'update failure' message.
Hoping that this install goes better.
Discover and save your favorite ideas. Come back to expert answers, step-by-step guides, recent topics, and more.
New here? Get started with these tips. How to use Community New member guide