- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-25-2010 08:29 AM - edited 03-12-2019 09:32 AM
CUCM Database Replication is an area in which Cisco customers and partners have asked for more in-depth training in being able to properly assess a replication problem and potentially resolve an issue without involving TAC. This document discusses the basics needed to effectively troubleshoot and resolve replication issues.
Replication Architecture
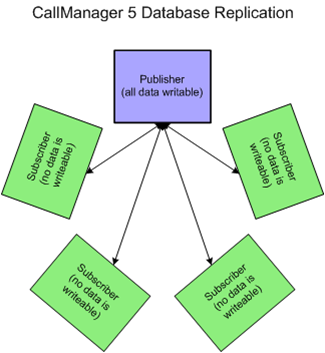
CUCM 5.x Replication Architecture
Communications Manager 5.x has a similar replication topology to Callmanager 4.X. They both follow a hub and spoke topology. The publisher establishes a connection to every server in the cluster and the subscribers establish a connection the local database and the publisher only. As illustrated in the figure below, only the publisher's database is writable while each subscriber contains a read only database. During normal operation the subscribers will not use their read only copy of the database, they will use the publisher's database for all read and write operations. In the event the publisher goes down or becomes inaccessible the subscribers will use their local copy of the database. Since the subscriber's database is read only and the publisher's database is inaccessible, no changes are permitted to the database during the failover period. Changes in architecture are implemented in later versions to address this limitation.
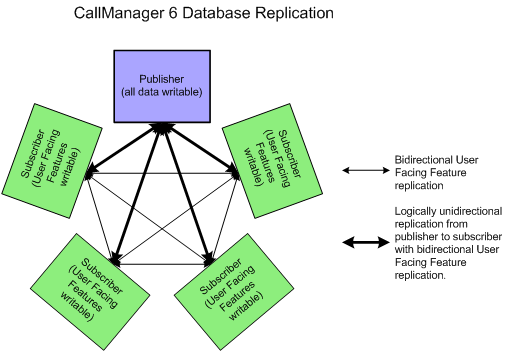
CUCM 6.x-10.x Architecture
Replication in Communications Manager 6.x, 7.x, and 8.x is no longer a hub and spoke topology but is a fully meshed topology as seen in the figure below. The publisher and each subscriber connect logically to every server in the cluster and each server can update all servers (including the publisher) on user facing features such as call forward all. The full list of user facing features is located on the following slide. This change in topology overcomes previous limitations in replication architecture, as changes can now be made to local subscriber databases for user facing faetures even while the publisher is inaccessible. Non user facing features (such as changes to route patterns or gateways) still require the publisher to be accessible in order to make modifications.
User Facing Features
Below is a list of some user facing features that can be updated by the subscriber and therefore updated while the publisher is down. This is not an exhaustive list.
User Facing Features
|
Call Forward All (CFA) |
Checking Current Replication Status
The first step to fix replication properly is to first identify what the current state of replication is in the cluster. Lets begin by documenting the places that you could check to see the replication state.
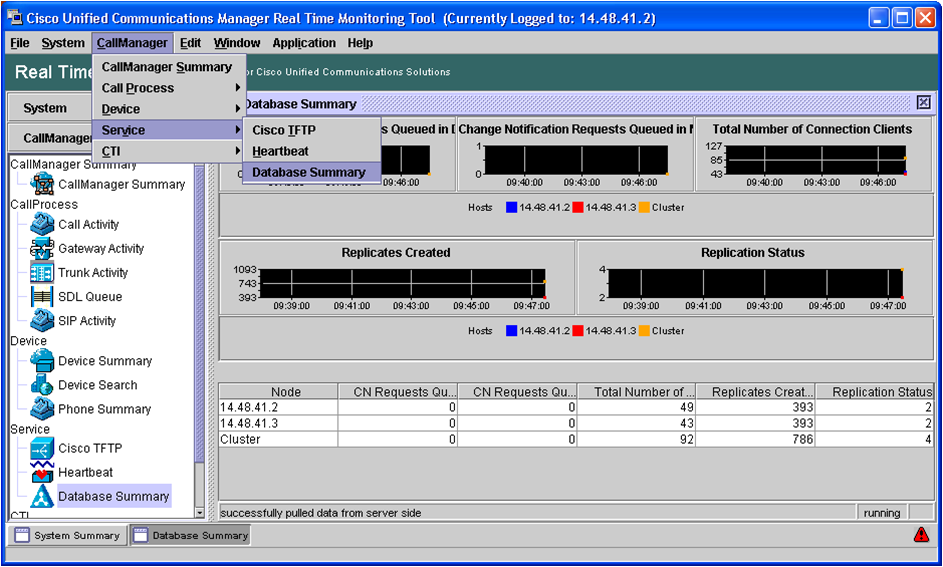
The Real Time Monitoring Tool - Database Summary Page
In RTMT, Choose CallManager->Service->Database Summary.
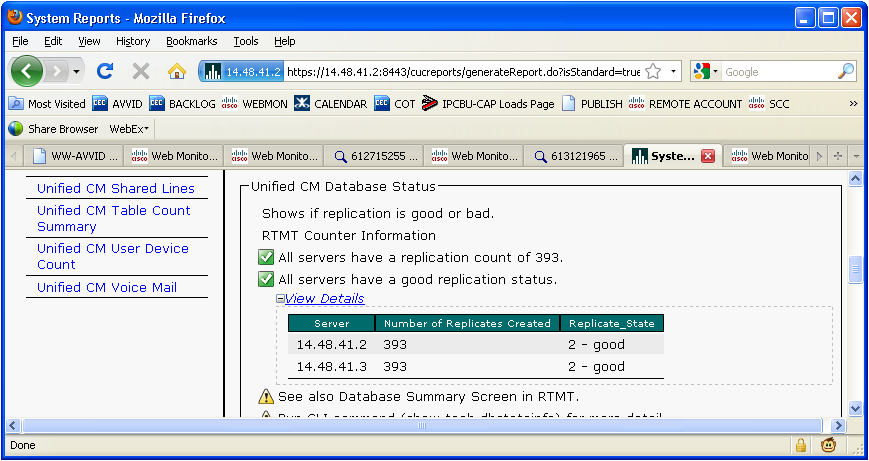
Cisco Unified Reporting - Database Status Report
Choose "Cisco Unified Reporting" from the Navigation dropdown in the upper right corner of the CCMAdministration page. Then choose "Database Status Report", and generate a new report.
CLI Commands to Check Replication State
admin:show perf query class "Number of Replicates Created and State of Replication"==>query class :
- Perf class (Number of Replicates Created and State of Replication) has instances and values:
ReplicateCount -> Number of Replicates Created = 348
ReplicateCount -> Replicate_State = 2
 |
What does the Status (0,1,2,3,4) Mean?
After checking the current stat of replication using one of the previous methods, we can use the table below to understand what each state means
| 0 | Initialization State | This state indicates that replication is in the process of trying to setup. Being in this state for a period longer than an hour could indicate a failure in setup. |
| 1 | Number of Replicates not correct | This state is rarely seen in 6.x and 7.x but in 5.x can indicate its still in the setup process. Being in this state for a period longer than an hour could indicate a failure in setup. |
| 2 | Replication is good | Logical connections have been established and tables match the other servers on the cluster. |
| 3 | Tables are suspect |
Logical connections have been established but we are unsure if tables match. In 6.x and 7.x all servers could show state 3 if one server is down in the cluster. This can happen because the other servers are unsure if there is an update to a user facing feature that has not been passed from that sub to the other device in the cluster. |
| 4 | Setup Failed / Dropped | The server no longer has an active logical connection to receive database table across. No replication is occurring in this state. |
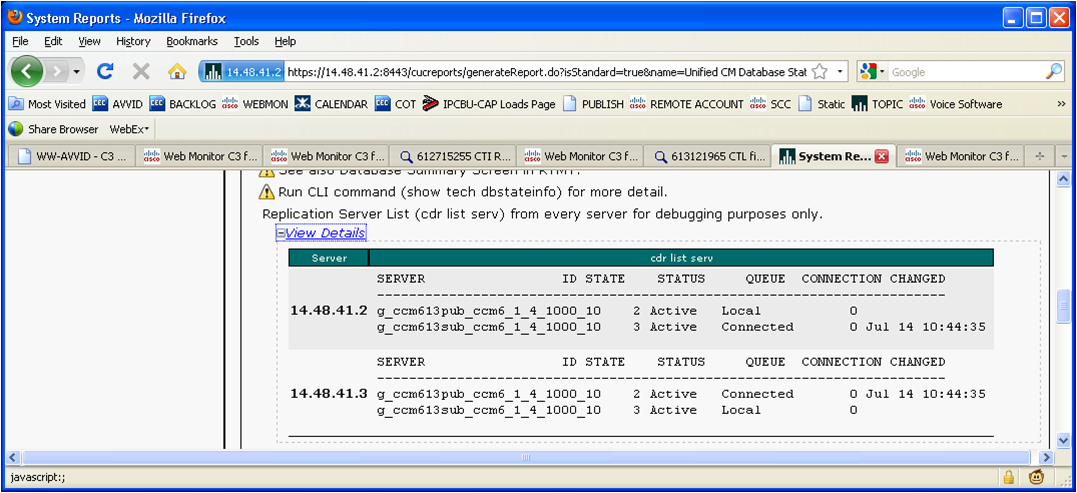
The logical connections discussed above are the connections seen in the Topology Diagram in the begining of this document. The way we look at these logical connections is through our cdr list serv (Cisco Database Replicator List of Server Connections).
Verifying the Status Number Based on Descriptions
It is important to verify the state of replication that is being provided by any of these 3 methods. For example, in some instances a server could show that it is in state 3 but the 'cdr list serv' output shows that the logical connections are in "Dropped" state. This is similar to the server being in state 4. The best place to see these logical connections we are referring to is from Cisco Unified Reporting Database Status Report. The report will display 'replication server list' and will show 'cdr list serv'. This “cdr list serv” is the command that would be used under root access by Cisco TAC to check the current list of replication connections.
| Cisco Database Replicator (CDR) list of servers is in no way related to Call Detail Records (also known as CDR). |
Ciso Unified Reporting - Replication Server List (cdr list serv)
Next Steps
Now that the state of replication has been identified, if the servers are in a state other than 2 it is necessary to identify what other information is needed in order to proceed in taking further acction. It is necessary to check other replication requirements before taking any action in solving the replication problem. Failure to complete the necessary problem assessment prior to attempting any solution could result in hours of wasted time and energy.
Server/Cluster Connectivity
Confirm the connectivity between nodes. In 5.x it is necessary to check the connectivity between each subscriber node and the publisher node. In 6.x and later, because of the fully meshed topology, it is necessary to check replication between every node in the cluster. This is important to keep in mind if an upgrade has taken place from 5.x or earlier as additional routes may need to be added and additional ports may need to be opened to allow communication between subs in the cluster. The documentation on checking connectivity is linked below.
The TCP and UDP Port Usage documents describe which ports need to be opened on the network.
CUCM 8.5:
http://www.cisco.com/en/US/docs/voice_ip_comm/cucm/port/8_5_1/portlist851.html
CUCM 8.0:
http://www.cisco.com/en/US/docs/voice_ip_comm/cucm/port/8_0_2/portlist802.html
Configuration Files
Check all the hosts files that will be used when setting up replication. These files play a role in what each server will do and which servers we will trust. The files we are referring to here are listed below
FilePurpose
| /etc/hosts | This file is used to locally resolve hostnames to IP addresses. It should include the hostname and IP address of all nodes in the cluster including CUPS nodes. |
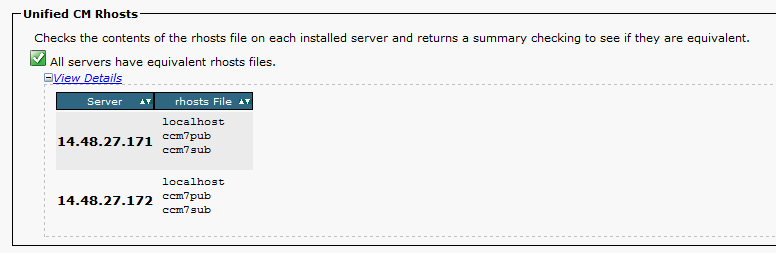
| /home/informix/.rhosts | A list of hostnames which are trusted to make database connections |
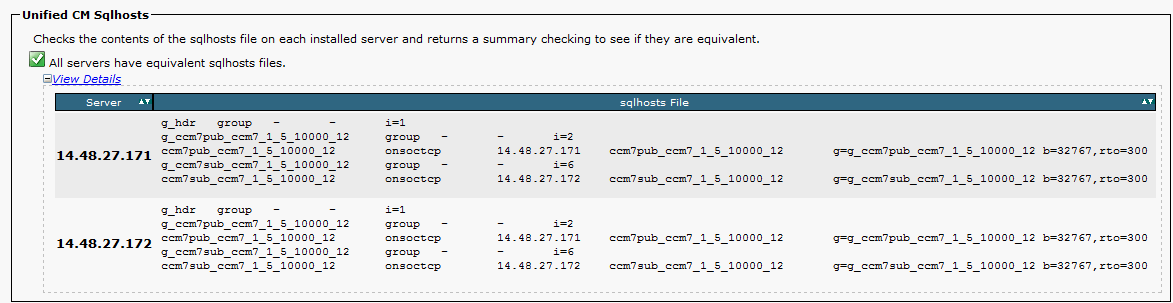
| $INFORMIXDIR/etc/sqlhosts | Full list of CCM servers for replication. Servers here should have the correct hostname and node id (populated from the process node table). This is used to determine to which servers replicates are pushed. |
/etc/hosts
Below is the /etc/hosts as displayed Verified in Unified Reporting. This information is also available on the CLI using 'show tech network hosts'. Cluster Manager populates this file and is used for local name resolution.

.rhosts file
sqlhosts
DNS (Optional)
If DNS is configured on a particular server it is required for both forward and reverse DNS to resolve correctly. Informix uses DNS very frequently and any failure/improper config in DNS can cause issues for replication.
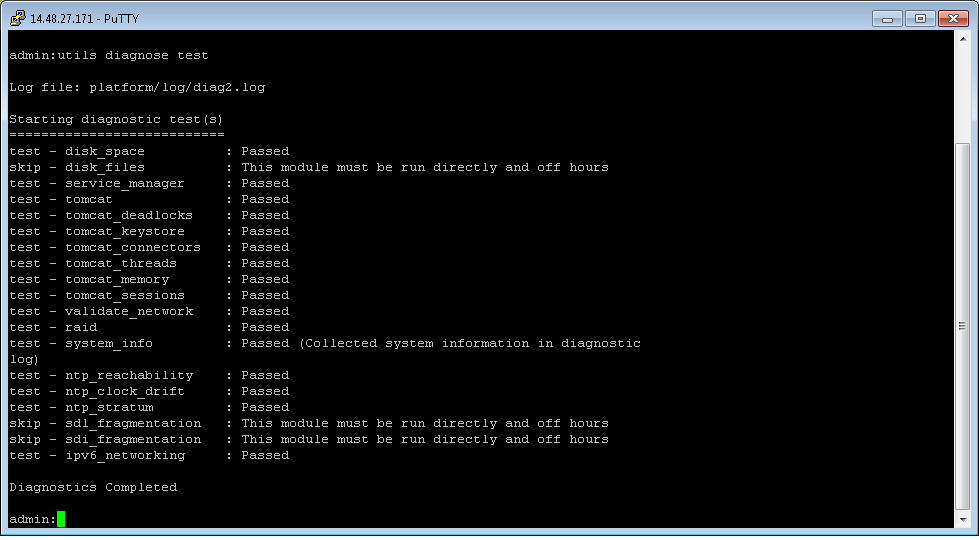
Verifying DNS
The best command to verify DNS is utils diagnose test. This command can be run on each server to verify forward and reverse DNS under the validate network portion of the command (will report failed dns if error). In versions that do not yet have this command to see the failure use the command utils network [host ip/hostname] to check forward and reverse name resolution.
Using Replication Commands
Meaning of each command
After verifying that we have good connectivity and all the underlying hosts files are correct and matching across the cluster it might be necessary to use CLI replication commands to fix the replication problem. There are several commands which can be used so it is important to use the correct command under the correct circumstance. The following table lists each command and it's function. Certain commands are not available in each version of CUCM.
commandfunction
| utils dbreplication stop |
Normally run on a subscriber. Stops currently replication running, restarts A Cisco DB Replicator, deletes marker file used to signal replication to begin. This can be run on each node of the cluster by doing “utils dbreplication stop”. In 7.1.2 and later “utils dbreplication stop all” can be run on the Publisher node to stop replication on all nodes |
| utils dbreplication repair | |
|
utils dbreplication repairtable utils dbreplication repairreplicate |
Introduced in 7.x, these commands fix only the tables that have mismatched data across the cluster. This mismatched data is found by issuing a utils dbreplication status. These commands should only be used if logical connections have been established between the nodes. |
| utils dbreplication reset | Always run from the publisher node, used to reset replication connections and do a broadcast of all the tables. This can be executed to one node by hostname “utils dbreplication reset nodename” or on all nodes by “utils dbreplication reset all”. |
| utils dbreplication quickaudit | Checkes critical dynamic tables for consistency. To check all tables run utils dbreplication status. |
| utils dbreplication clusterreset |
Always run from the publisher node, used to reset replication connections and do a broadcast of all tables. Error checking is ignored. Following this command 'utils dbreplication reset all' should be run in order to get correct status information. Finally after that has returned to state 2 all subs in the cluster must be rebooted Note: This command is no longer functional as of CUCM 9.0(1). Use "utils dbreplication reset all" instead. |
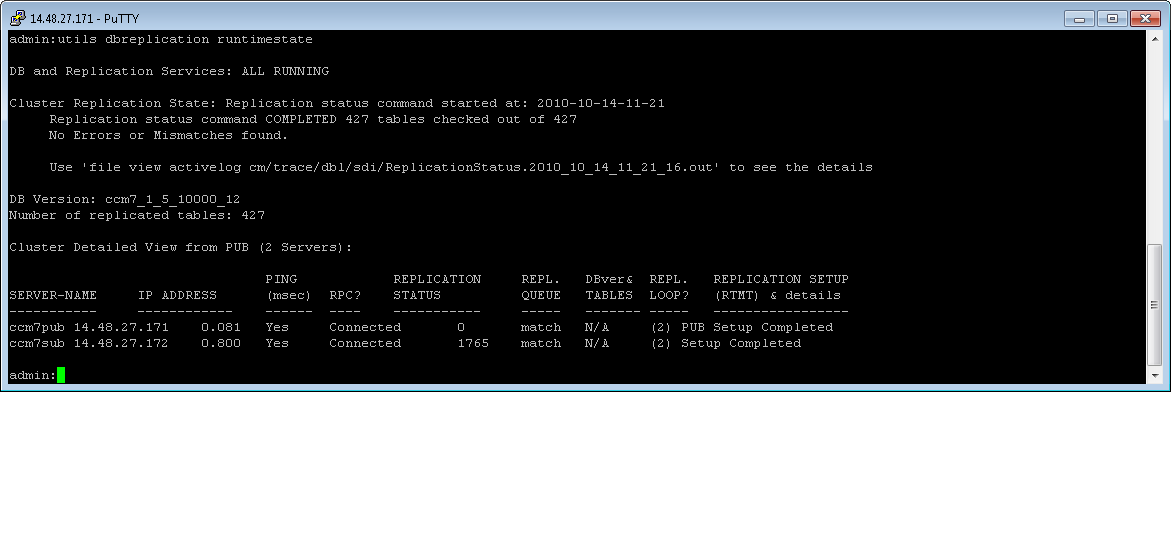
| utils dbreplication runtimestate | Available in 7.X and later this command shows the state of replication as well as the state of replication repairs and resets. This can be used as a helpful tool to see which tables are replicating in the process. |
| utils dbreplication forcedatasyncsub | This command forces a subscriber to have its data restored from data on the publisher. Use this command only after the 'utils dbreplication repair' command has been run several times and the 'utils dbreplication status' ouput still shows non-dynamic tables out of sync. |
| utils dbreplication dropadmindb | Run on a publisher or subscriber, this command is used to drop the syscdr database. This clears out configuration information from the syscdr database which forces the replicator to reread the configuration files. Later examples talk about identifying a corrupt syscdr database. |
| utils dbreplication dropadmindbforce | Same as above, but may need to be used in cases where above command fails |
| utils dbreplication setprocess | Sets the "process" value within Informix. This enables multithreading and improves replication setup time at the slight cost of processing power. Recommended to set to 40 for large clusters (10+ nodes). |
Examples
Reestablish logical CDR connections to all servers for replication
Getting on I would instantly check the RTMT or Unified Report in order to identify the current state of replication. I choose to ask for the Database Status report as the customer is in a version that has this available. In the report the information I find is the following.
- The cluster is a 5 node cluster.
- The publisher is in Replication State = 3
- All subscribers in the cluster are in Replication State = 4
- We check in the report for Replication Server List and only the publisher shows local as connected. This verifies to us that based on our descriptions the servers are indeed in the states listed above.
- We now do some other checks to prepare to fix replication. We verify in the report that all of the hosts files look correct. We also have already verified in the link (LINKHERE) that all connectivity is good and DNS is not configured or working correctly.
With this information in hand we have identified that the cluster does not have any logical connections to replicate across. Thus the recommendation to the customer would be to follow the most basic process that fixes about 50 percent of replication cases. Below are these steps.
- utils dbreplication stop on all subscribers. This command can be run on all subscribers at the same time but needs to complete on all subscribers prior to being run on the publisher. The amount of time this command takes to return is based on your cluster's repltimeout. This can be seen through the Command show tech repltimeout and by default is 300 seconds or 5 minutes. At the end of this document I will provide a calculation for determining what you should set your repltimeout (via utils dbreplication setrepltimeout) in your cluster and how this value affects replication. (If utils dbreplication stop all is available (7.X and later) then step 1 and step 2 can be accomplished in this one command)
- utils dbreplication stop on publisher. Again this command can be done through the utils dbreplication stop all if available. This also will wait the repltimeout as said above.
- utils dbreplication reset all - This command will take an hour to complete or longer depending on your cluster. You can monitor the status through the utils dbreplication runtimestate or through the procedure following the examples portion of this document.
Reestablish logical CDR connection to a single node
Getting on I would instantly check the RTMT or Unified Report in order to identify the current state of replication. I choose to ask for the Database Status report as the customer is in a version that has this available. In the report the information I find is the following.
- The cluster is a 3 node cluster.
- The publisher is in Replication State = 3
- SubscriberA is in Replication State =3 and SubscriberB is in Replication State = 4
- We check in the report for Replication Server List and the publisher shows local as connected and SubscriberA as connected. Subscriber B is not listed in this list (NOTE* Would be the same procedure if SubscriberB showed "Dropped". This verifies to us that based on our descriptions the servers are indeed in the states listed above.
- We now do some other checks to prepare to fix replication. We verify in the report that all of the hosts files look correct. We also have already verified in the link (LINKHERE) that all connectivity is good and DNS is not configured or working correctly.
- utils dbreplication stop on Subscriber B. This command can be run on all subscribers at the same time but needs to complete on all subscribers prior to being run on the publisher. The amount of time this command takes to return is based on your cluster's repltimeout. This can be seen through the Command show tech repltimeout and by default is 300 seconds or 5 minutes.
- utils dbreplication reset nodename from publisher. In our example I would type utils dbreplication stop subscriberB from the publisher and then wait for it to recreate the logical connection to the subscriberB and broadcast the tables to that subscriber. To follow where in the procedure it is you can use utils dbreplication runtimestate or the procedure following the examples section.
- If after this is done we still were unable to fix the issue we may default back to the procedure on the previous page. (utils dbreplicaton stop all from publisher (or on subs then pub) and then utils dbreplication reset all)
Logical connections are established but tables are out of sync
Getting on I would instantly check the RTMT or Unified Report in order to identify the current state of replication. I choose to ask for the Database Status report as the customer is in a version that has this available. In the report the information I find is the following.
- All nodes in the cluster are in Replication State = 3
- We check in the report for Replication Server List and all servers show as connected in the list (each server shows local for itself but connected from other servers perspective) This verifies to us that based on our descriptions the servers are indeed in the states listed above.
- We now do some other checks to prepare to fix replication. We verify in the report that all of the hosts files look correct. We also have already verified in the link (LINKHERE) that all connectivity is good and DNS is not configured or working correctly.
- utils dbreplication status from publisher. This command will confirm for us that indeed we have mismatched tables. Based on our earlier explanations this means that we do not need to do any reset as they fix connections and repairs fix mismatched tables. Once we have used the status to confirm that we have tables different we then can proceed to fix.
- utils dbreplication repair from publisher - Which repair command depends on which tables and how many tables are out of sync. If you have a megacluster or a very large deployment a repair can take a long time (a day in some instances depending on how it failed) Thus it is important on which command you pick in those circumstances. On smaller deployments (less than 5,000 phones for example a utils dbreplication repair all is normally fine to do. If it is only one node with a bad table we can do utils dbreplication repair nodename. If it is only one table you can use utils dbreplication repairtable (node/all) to fix it on the problem server or on the whole cluster.
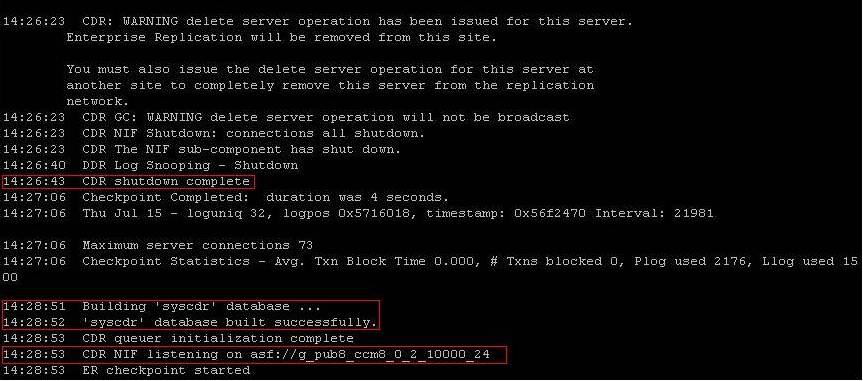
Corrupt syscdr causing replication failure
- The cluster is a 3 node cluster.
- The publisher is in Replication State = 3
- SubscriberA is in Replication State =3 and SubscriberB is in Replication State = 4
- We check in the report for Replication Server List and the publisher shows local as connected and SubscriberA as connected. Subscriber B is not listed in this list (NOTE* Would be the same procedure if SubscriberB showed "Dropped". This verifies to us that based on our descriptions the servers are indeed in the states listed above.
- We now do some other checks to prepare to fix replication. We verify in the report that all of the hosts files look correct. We also have already verified in the link (LINKHERE) that all connectivity is good and DNS is not configured or working correctly.
- Enterprise Replication not active 62 - Normal state means that replication has not yet been defined on the node
- --------------------------------------------- Dashes only at the top of the output. This could indicate a corrupt syscdr. This output can only be checked from the utils dbreplication status command as the Cisco Unified Reporting Tool Database Status Report displays just ------------------------ for both of the above states (CSCti84361 as been opened to address that issue).
- utils dbreplication stop - Issued on SubscriberB
- utils dbreplication dropadmindb - Issued on SubscriberB to restart the syscdr on that node.
- utils dbreplication reset <subscriberB> - TO once again try to reestablish the connection after fixing the corrupted syscdr.
Replication Steps
These steps are done automatically (by replication scripts) when the system is installed. When we do a “utils dbreplication reset all” they get done again.
List of steps
Define Pub - Set it up to start replicating
Define template on pub and realize it (Tells pub which tables to replicate)
Define each Sub
Realize Template on Each Sub (Tells sub which tables they will get/send data for)
Sync data using "cdr check" or "cdr sync" (older systems use sync)
Replication Flow Chart
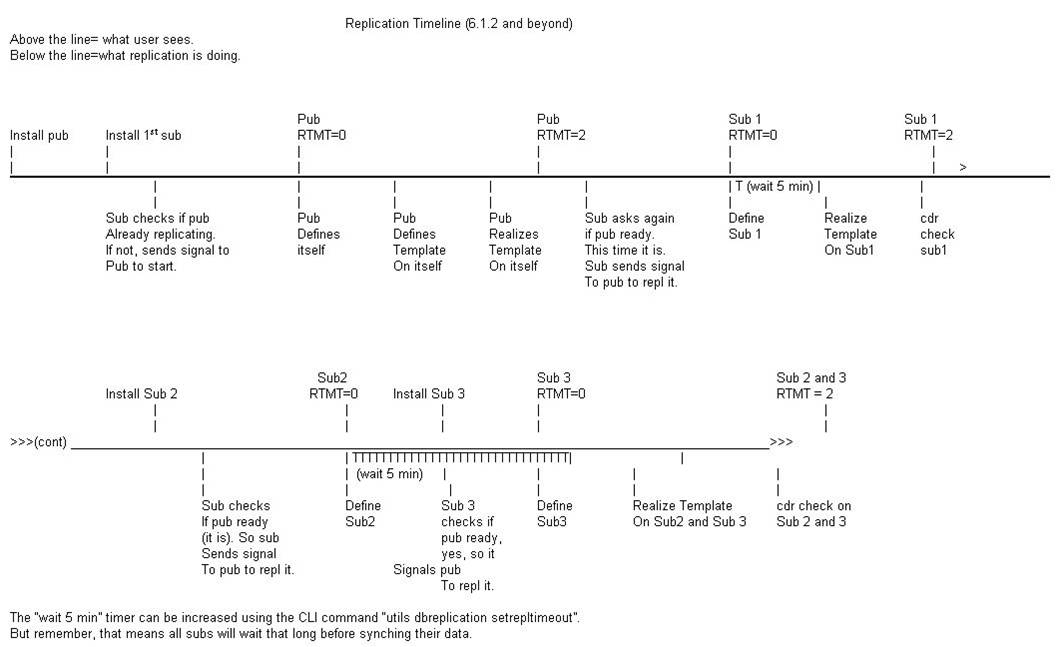
It is possible to determine where in the process the replication setup is using commands, log files, and the database status report.
Publisher syscdr/define
Subscriber define
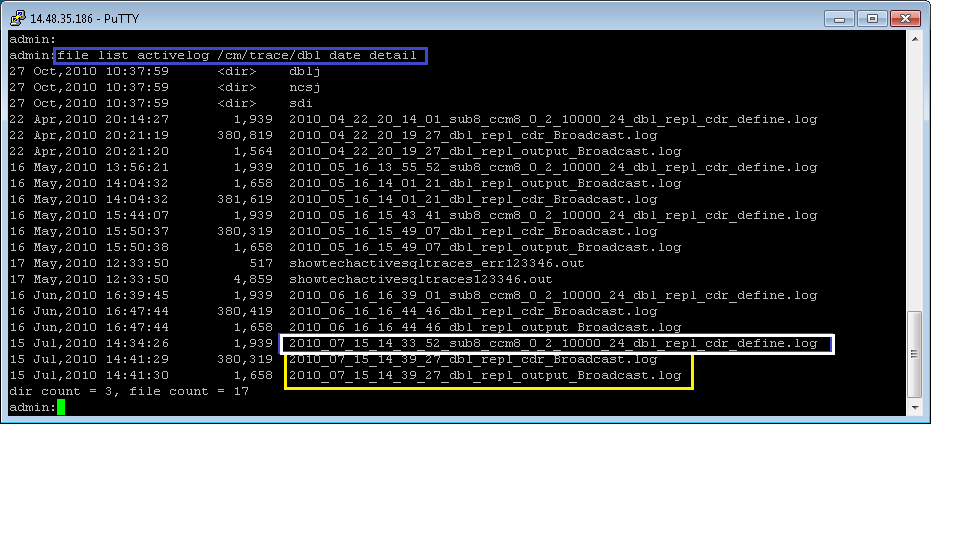
You can also check the output of file list activelog cm/trace/dbl date detail. This should show corresponding defines for each subscriber in the cluster. *Note*: Publisher define not listed here.
The define is shown in white below.
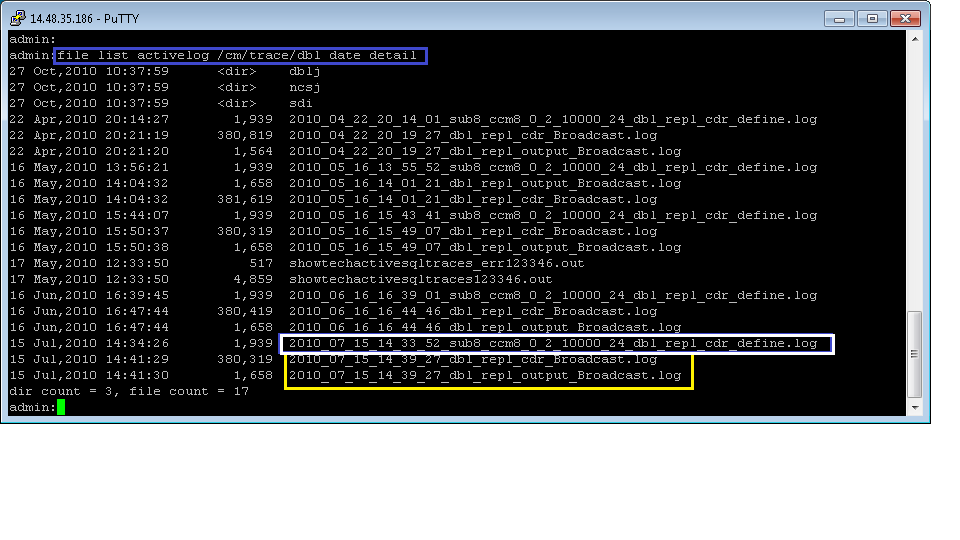
If we have a define for every server following a reset then things are more than likely looking good. Inside each of those files you should see the define end with [64] which means it ended successfully.
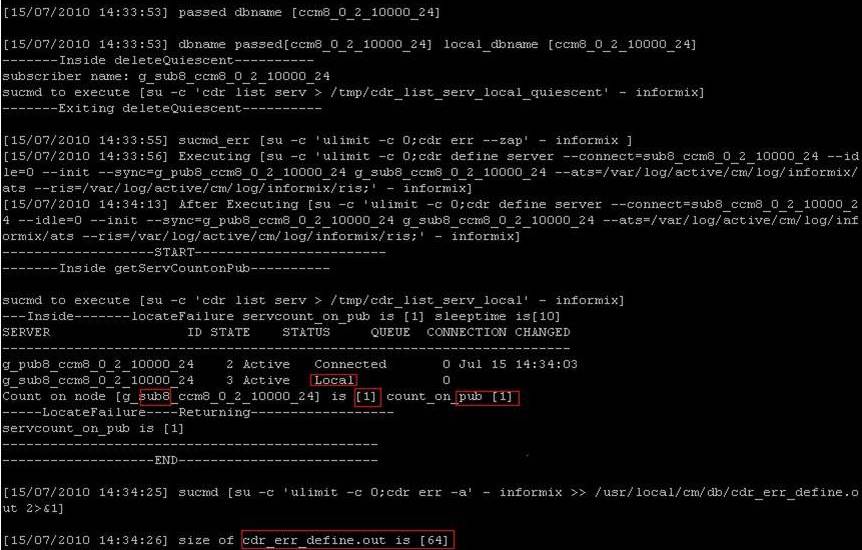
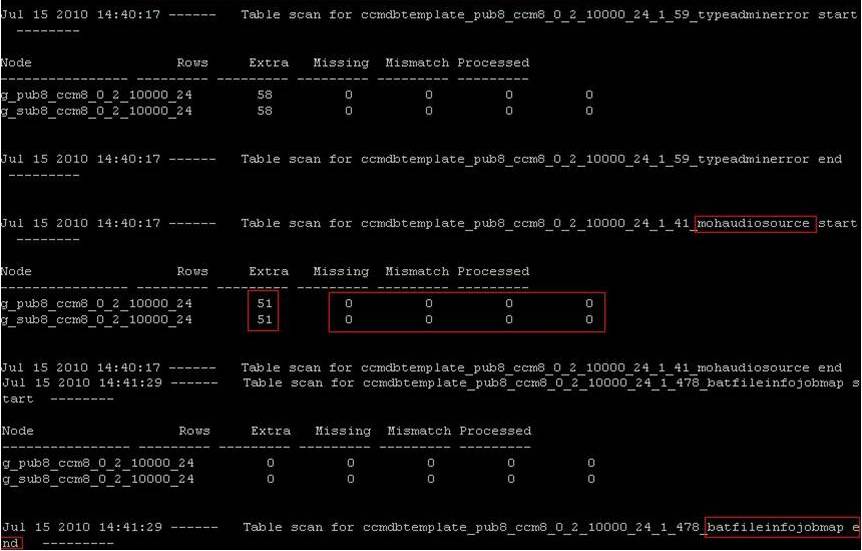
After all subscribers have been defined we then wait the repltimeout (Can check from show tech repltimeout) it will then do a broadcast file that actually pushes the replicates across. The broadcast is shown in yellow. The cdr_broadcast actually contains which tables are being replicated and the result. Below is the list and then an excerpt from the cdr_broadcast log (Broadcast shown in Yellow Box)
CDR Broadcast Log Excerpt
With this you should be able to follow and fix replication cases. Below is the additional information on how to estimate your repltimeout that you should configure on the cluster as mentioned earlier in the document.
Replication Timeout Design Estimation
Replication timeout is the time that CUCM publisher waits for the subscriber server defines to complete before it will start a define.
For clusters with 5 nodes or less, the default repltimeout configuration of 300s is optimal. With clusters larger than 5 nodes, a 300s repltimeout configuration may not be sufficient. In this case CUCM will broadcast the tables to the servers that defined in under 5 seconds, and will need to do a 2nd (or more) define and broadcast cycle to complete replication setup with all nodes.
THe following guideline provides recommended intervals for repltimeout for configuration based on the number of nodes in the cluster:
Server 1-5 = 1 Minute Per Server
Servers 6-10 = 2 Minutes Per Server
Servers >10 = 3 Minutes Per Server.
Example: 12 Servers in Cluster : Server 1-5 * 1 Min = 5 Min, + 6-10 * 2 Min = 10 min, + 11-12 * 3 Min = 6 Min,
Repltimeout should be set to 21 Minutes.
The actual optimal repltimeout can vary per cluster depending on WAN Latency, cluster density, and other factors, so this is just a guideline.
To confirm that replication is setting up in a single batch, run utils dbreplication stop all followed by utils dbreplication reset all from the CUCM publisher, and then verify the sequence of logs using file list activelog cm/trace/dbl/* date detailed from the publisher CLI. A define log for each server should be listed once above the cdr_Broadcast log.
Note:
Starting in CUCM 10.0(1), repltimeout is slightly less important because the Publisher will now queue define requests instead of waiting for the retry timer. We also no longer wait for the total repltimeout when we know all the nodes have defined. Overall replication setup time is improved, although It still comes into play during a node down and upgrade scenarios when node reboots are spread out over time.
Document Contributors:
=========
Russ Hardison (rhardiso)
Sriram Sivaramakrishnan (srsivara)
Wes Sisk (wsisk)
Ryan Ratliff (rratliff)
Jason Burns (jasburns)
Kenneth Russel (kerussel)
Omar Mora (ommora)
Shane Kirby (shkirby)
Special thanks to Nancy Balsbaugh.- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Excellent contribution.
10 / 10 points.
Very helpful
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Great guide! Saved me hours of extra work.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
An excellent and comprehensive DB replication guide! Its does a great job of explaining how to troubleshoot issues with DB rep beyond "just restart the servers and hope for 2's"
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
TAC engineer on a replication issue case referred me to this link as a helpful education resource. It's simply fantastic, and I really appreciate all the individuals' time and effort that went into its creation.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks a lot for this easy-to-understand and highly useful guide!!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Informative and detailed doc.. Easy to understand
Tx,
Shalu
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks for sharing.
This is pure gold.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Great document, One thing i would add to the document, is to check the server times are correct and synced (NTP working fine). That has slowed me down fixing some DB replication issues.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
excellent document !!! Many thanks !
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
That would be covered under the "utils diagnose test" section.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Excellent DOC for troubleshooting.
regds,
aman
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi
I have Question, If the .rhost file is deleted/corrputed, is there a way to recreate it? how can customer recreate it?
Thanks
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
hi Team,
Great article...appreciate your hard work on this stuff ! Love it...!!!
Regards,
Vimal Kooran Varkey
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
This is very helpful information. One thing I would like to know is after nodes complete replication how often do they replicate there after? Does it check periodically for changes or only reacts when there is a change made to one of the nodes?
Thanks,
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Replication is continuous. It is more like a push model than a pull model.